Run unit tests
views.py
# -*- coding: utf-8 -*-
"""
Monomotapa - A Micro CMS
Copyright (C) 2014, Paul Munday.
PO Box 28228, Portland, OR, USA 97228
paul at paulmunday.net
Modificado por: Rodrigo Garcia 2017 https://rmgss.net/contacto
This program is free software: you can redistribute it and/or modify
it under the terms of the GNU Affero Public License as published by
the Free Software Foundation, either version 3 of the License, or
(at your option) any later version.
This program is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU General Public License for more details.
You should have received a copy of the GNU Affero General Public License
along with this program. If not, see <http://www.gnu.org/licenses/>.
Monomotapa:
a city whose inhabitants are bounded by deep feelings of friendship,
so that they intuit one another's most secret needs and desire.
For instance, if one dreams that his friend is sad, the friend will
perceive the distress and rush to the sleepers rescue.
(Jean de La Fontaine, *Fables choisies, mises en vers*, VIII:11 Paris,
2nd ed., 1678-9)
cited in :
Alberto Manguel and Gianni Guadalupi, *The Dictionary of Imaginary Places*,
Bloomsbury, London, 1999.
A micro cms written using the Flask microframework, orignally to manage my
personal site. It is designed so that publishing a page requires no more than
dropping a markdown page in the appropriate directory (though you need to edit
a json file if you want it to appear in the top navigation).
It can also display its own source code and run its own unit tests.
The name 'monomotapa' was chosen more or less at random (it shares an initial
with me) as I didn't want to name it after the site and be typing import
paulmunday, or something similar, as that would be strange.
"""
from flask import render_template, abort, Markup, escape, request #, make_response
from flask import redirect
from werkzeug.utils import secure_filename
from pygments import highlight
from pygments.lexers import PythonLexer, HtmlDjangoLexer, TextLexer
from pygments.formatters import HtmlFormatter
import markdown
from time import gmtime, strptime, strftime, ctime, mktime
import datetime
import os.path
import os
import subprocess
import json
import traceback
from collections import OrderedDict
from simplemotds import SimpleMotd
from monomotapa import app
from monomotapa.config import ConfigError
from monomotapa.utils import captcha_comprobar_respuesta, captcha_pregunta_opciones_random
from monomotapa.utils import categorias_de_post, categoriasDePost, categoriasList, cabezaPost
from monomotapa.utils import titulo_legible, metaTagsAutomaticos
from markdown.extensions.toc import TocExtension
json_pattrs = {}
with open(os.path.join('monomotapa','pages.json'), 'r') as pagefile:
json_pattrs = json.load(pagefile)
simplemotd = SimpleMotd("config_simplemotds.json")
class MonomotapaError(Exception):
"""create classs for own errors"""
pass
def get_page_attributes(jsonfile):
"""Returns dictionary of page_attributes.
Defines additional static page attributes loaded from json file.
N.B. static pages do not need to have attributes defined there,
it is sufficient to have a page.md in src for each /page
possible values are src (name of markdown file to be rendered)
heading, title, and trusted (i.e. allow embeded html in markdown)"""
try:
with open(src_file(jsonfile), 'r') as pagesfile:
page_attributes = json.load(pagesfile)
except IOError:
page_attributes = []
return page_attributes
def get_page_attribute(attr_src, page, attribute):
"""returns attribute of page if it exists, else None.
attr_src = dictionary(from get_page_attributes)"""
if page in attr_src and attribute in attr_src[page]:
return attr_src[page][attribute]
else:
return None
# Navigation
def top_navigation(page):
"""Generates navigation as an OrderedDict from navigation.json.
Navigation.json consists of a json array(list) "nav_order"
containing the names of the top navigation elements and
a json object(dict) called "nav_elements"
if a page is to show up in the top navigation
there must be an entry present in nav_order but there need not
be one in nav_elements. However if there is the key must be the same.
Possible values for nav_elements are link_text, url and urlfor
The name from nav_order will be used to set the link text,
unless link_text is present in nav_elements.
url and urlfor are optional, however if ommited the url wil be
generated in the navigation by url_for('staticpage', page=[key])
equivalent to @app.route"/page"; def page())
which may not be correct. If a url is supplied it will be used
otherwise if urlfor is supplied it the url will be
generated with url_for(urlfor). url takes precendence so it makes
no sense to supply both.
Web Sign-in is supported by adding a "rel": "me" attribute.
"""
with open(src_file('navigation.json'), 'r') as navfile:
navigation = json.load(navfile)
base_nav = OrderedDict({})
for key in navigation["nav_order"]:
nav = {}
nav['base'] = key
nav['link_text'] = key
if key in navigation["nav_elements"]:
elements = navigation["nav_elements"][key]
nav.update(elements)
base_nav[key] = nav
return {'navigation' : base_nav, 'page' : page}
# For pages
class Page:
"""Generates pages as objects"""
def __init__(self, page, **kwargs):
"""Define attributes for pages (if present).
Sets self.name, self.title, self.heading, self.trusted etc
This is done through indirection so we can update the defaults
(defined in the 'attributes' dictionary) with values from config.json
or pages.json easily without lots of if else statements.
If css is supplied it will overide any default css. To add additional
style sheets on a per page basis specifiy them in pages.json.
The same also applies with hlinks.
css is used to set locally hosted stylesheets only. To specify
external stylesheets use hlinks: in config.json for
default values that will apply on all pages unless overidden, set here
to override the default. Set in pages.json to add after default.
"""
# set default attributes
self.page = page.rstrip('/')
self.defaults = get_page_attributes('defaults.json')
self.pages = get_page_attributes('pages.json')
self.url_base = self.defaults['url_base']
title = titulo_legible(page.lower())
heading = titulo_legible(page.capitalize())
self.categorias = categoriasDePost(self.page)
self.exclude_toc = True
try:
self.default_template = self.defaults['template']
except KeyError:
raise ConfigError('template not found in default.json')
# will become self.name, self.title, self.heading,
# self.footer, self.internal_css, self.trusted
attributes = {'name' : self.page, 'title' : title,
'navigation' : top_navigation(self.page),
'heading' : heading, 'footer' : None,
'css' : None , 'hlinks' :None, 'internal_css' : None,
'trusted': False,
'preview-chars': 250,
}
# contexto extra TODO: revisar otra forma de incluir un contexto
self.contexto = {}
self.contexto['consejo'] = simplemotd.getMotdContent()
# set from defaults
attributes.update(self.defaults)
# override with kwargs
attributes.update(kwargs)
# override attributes if set in pages.json
if page in self.pages:
attributes.update(self.pages[page])
# set attributes (as self.name etc) using indirection
for attribute, value in attributes.items():
# print('attribute', attribute, '=-==>', value)
setattr(self, attribute, value)
# meta tags
try:
self.pages[self.page]['title'] = attributes['title']
self.pages[self.page]['url_base'] = self.url_base
metaTags = metaTagsAutomaticos(self.page, self.pages.get(self.page, {}))
self.meta = metaTags
# for key, value in self.pages[self.page].items():
# print(' ', key, ' = ', value)
except Exception as e:
tb = traceback.format_exc()
print('Error assigning meta:', str(e), '\n', str(tb))
# reset these as we want to append rather than overwrite if supplied
if 'css' in kwargs:
self.css = kwargs['css']
elif 'css' in self.defaults:
self.css = self.defaults['css']
if 'hlinks' in kwargs:
self.hlinks = kwargs['hlinks']
elif 'hlinks' in self.defaults:
self.hlinks = self.defaults['hlinks']
# append hlinks and css from pages.json rather than overwriting
# if css or hlinks are not supplied they are set to default
if page in self.pages:
if 'css' in self.pages[page]:
self.css = self.css + self.pages[page]['css']
if 'hlinks' in self.pages[page]:
self.hlinks = self.hlinks + self.pages[page]['hlinks']
# append heading to default if set in config
self.title = self.title + app.config.get('default_title', '')
def _get_markdown(self):
"""returns rendered markdown or 404 if source does not exist"""
src = self.get_page_src(self.page, 'src', 'md')
if src is None:
abort(404)
else:
return render_markdown(src, self.trusted)
def get_page_src(self, page, directory=None, ext=None):
""""return path of file (used to generate page) if it exists,
or return none.
Also returns the template used to render that page, defaults
to static.html.
It will optionally add an extension, to allow
specifiying pages by route."""
# is it stored in a config
pagename = get_page_attribute(self.pages, page, 'src')
if not pagename:
pagename = page + get_extension(ext)
if os.path.exists(src_file(pagename , directory)):
return src_file(pagename, directory)
else:
return None
def get_template(self, page):
"""returns the template for the page"""
pagetemplate = get_page_attribute(self.pages, page, 'template')
if not pagetemplate:
pagetemplate = self.default_template
if os.path.exists(src_file(pagetemplate , 'templates')):
return pagetemplate
else:
raise MonomotapaError("Template: %s not found" % pagetemplate)
def generate_page(self, contents=None):
"""return a page generator function.
For static pages written in Markdown under src/.
contents are automatically rendered.
N.B. See note above in about headers"""
toc = '' # table of contents
if not contents:
contents, toc = self._get_markdown()
# print('////', toc)
template = self.get_template(self.page)
# print('......................')
# def mos(**kwargs):
# for k in kwargs:
# print(k, end=',')
# mos(**vars(self))
return render_template(template,
contents = Markup(contents),
toc=toc,
**vars(self))
# helper functions
def src_file(name, directory=None):
"""return potential path to file in this app"""
if not directory:
return os.path.join( 'monomotapa', name)
else:
return os.path.join('monomotapa', directory, name)
def get_extension(ext):
'''constructs extension, adding or stripping leading . as needed.
Return null string for None'''
if ext is None:
return ''
elif ext[0] == '.':
return ext
else:
return '.%s' % ext
def render_markdown(srcfile, trusted=False):
""" Returns markdown file rendered as html and the table of contents as html.
Defaults to untrusted:
html characters (and character entities) are escaped
so will not be rendered. This departs from markdown spec
which allows embedded html."""
try:
with open(srcfile, 'r') as f:
src = f.read()
md = markdown.Markdown(extensions=['toc', 'codehilite'])
md.convert(src)
toc = md.toc
if trusted == True:
content = markdown.markdown(src,
extensions=['codehilite',
TocExtension(permalink=True)])
else:
content = markdown.markdown(escape(src),
extensions=['codehilite',
TocExtension(permalink=True)])
return content, toc
except IOError:
return None
def render_pygments(srcfile, lexer_type):
"""returns src(file) marked up with pygments"""
if lexer_type == 'python':
with open(srcfile, 'r') as f:
src = f.read()
contents = highlight(src, PythonLexer(), HtmlFormatter())
elif lexer_type == 'html':
with open(srcfile, 'r') as f:
src = f.read()
contents = highlight(src, HtmlDjangoLexer(), HtmlFormatter())
# default to TextLexer for everything else
else:
with open(srcfile, 'r') as f:
src = f.read()
contents = highlight(src, TextLexer(), HtmlFormatter())
return contents
def get_pygments_css(style=None):
"""returns css for pygments, use as internal_css"""
if style is None:
style = 'friendly'
return HtmlFormatter(style=style).get_style_defs('.highlight')
def heading(text, level):
"""return as html heading at h[level]"""
heading_level = 'h%s' % str(level)
return '\n<%s>%s</%s>\n' % (heading_level, text, heading_level)
def posts_list(ordenar_por_fecha=True, ordenar_por_nombre=False):
'''Retorna una lista con los nombres de archivos con extension .md
dentro de la cappeta src/posts, por defecto retorna una lista con
la tupla (nombre_archivo, fecha_subida)'''
lista_posts = []
lp = []
if ordenar_por_nombre:
try:
ow = os.walk("monomotapa/src/posts")
p , directorios , archs = ow.__next__()
except OSError:
print ("[posts] - Error: Cant' os.walk() on monomotapa/src/posts except OSError")
else:
for arch in archs:
if arch.endswith(".md") and not arch.startswith("#") \
and not arch.startswith("~") and not arch.startswith("."):
lista_posts.append(arch)
lista_posts.sort()
return lista_posts
if ordenar_por_fecha:
try:
ow = os.walk("monomotapa/src/posts")
p,d,files=ow.__next__()
except OSError:
print ("[posts] - Error: Can't os.walk() on monomotapa/src/posts except OSError.")
else:
for f in files:
nombre_con_ruta = os.path.join("monomotapa/src/posts", f)
if not f.endswith("~") and not f.startswith("#") and not f.startswith("."):
secs_modificacion = SecsModificacionPostDesdeJson(f, json_pattrs)
ultima_modificacion = os.path.getmtime(nombre_con_ruta)
lp.append((secs_modificacion, ultima_modificacion, f))
lp.sort()
lp.reverse()
# colocando fecha en formato
for tupla in lp:
#fecha = strftime("a, %d %b %Y %H:%M:%S", ctime(tupla[0]))
cfecha = ctime(tupla[1])
#fecha = strptime("%a %b %d %H:%M:%S %Y", cfecha)
lista_posts.append((cfecha, tupla[2]))
return lista_posts
def categorias_list(categoria=None):
""" Rotorna una lista con los nombres de posts y el numero de posts que
pertenecen a la categoria dada o a cada categoria.
Las categorias se obtienen analizando la primera linea de cada archivo .md
an la carpeta donde se almacenan los posts.
Si no se especifica `categoria' cada elemento de la lista devuelta es:
(nombre_categoria, numero_posts, [nombres_posts])
si se especifica `categoria' cada elemento de la lista devuelta es:
(numero_posts, [nombres_posts]
"""
lista_posts = posts_list(ordenar_por_nombre=True)
lista_categorias = []
if categoria is not None:
c = 0
posts = []
for post in lista_posts:
nombre_arch = "monomotapa/src/posts/"+post
with open(nombre_arch, 'r') as file:
linea = file.readline().decode("utf-8")
lc = linea.split("[#")[1:]
for cad in lc:
cat = cad.split("]")[0]
if cat == categoria:
c += 1
posts.append(post)
lista_categorias = (c, posts)
return lista_categorias
dic_categorias = {}
for post in lista_posts:
nombre_arch = "monomotapa/src/posts/"+post
with open(nombre_arch, 'r') as fil:
linea = fil.readline().decode('utf-8') # primera linea
# extrayendo las categorias y registrando sus ocurrencias
# ejemplo: catgorías: [#reflexión](categoria/reflexion) [#navidad](categoria/navidad)
# extrae: [reflexion,navidad]
lc = linea.split("[#")[1:]
for cad in lc:
cat = cad.split("]")[0]
if cat not in dic_categorias:
dic_categorias[cat] = (1,[post]) # nuevo registro por categoria
else:
tupla = dic_categorias[cat]
c = tupla[0] + 1
lis = tupla[1]
if post not in lis:
lis.append(post)
dic_categorias[cat] = (c, lis)
# convirtiendo en lista
for k, v in dic_categorias.iteritems():
lista_categorias.append((k,v[0],v[1]))
lista_categorias.sort()
lista_categorias.reverse()
return lista_categorias
def cabeza_post(archivo , max_caracteres=250, categorias=True):
""" Devuelve las primeras lineas de una archivo de post (en formato markdown)
con un maximo numero de caracteres excluyendo titulos en la cabeza devuelta.
Si se especifica `categorias' en True
Se devuelve una lista de la forma:
(cabeza_post, categorias)
donde categorias son cadenas con los nombres de las categorias a la que
pertenece el post
"""
cabeza_post = ""
cats = []
with open(os.path.join("monomotapa/src/posts",archivo)) as file:
# analizando si hay titulos al principio
# Se su pone que la primera linea es de categorias
for linea in file.readlines():
linea = linea.decode("utf-8")
if linea.startswith(u"categorías:") or linea.startswith("categorias"):
if categorias:
cats = categoriasDePost(archivo)
#cats = categorias_de_post(archivo)
else:
# evitando h1, h2
if linea.startswith("##") or linea.startswith("#"):
cabeza_post += " "
else:
cabeza_post += linea
if len(cabeza_post) >= max_caracteres:
break
cabeza_post = cabeza_post[0:max_caracteres-1]
if categorias:
return (cabeza_post, cats)
return cabeza_post
def ultima_modificacion_archivo(archivo):
""" Retorna una cadena indicando la fecha de ultima modificacion del
`archivo' dado, se asume que `archivo' esta dentro la carpeta "monomotapa/src"
Retorna una cadena vacia en caso de no poder abrir `archivo'
"""
try:
ts = strptime(ctime(os.path.getmtime("monomotapa/src/"+archivo+".md")))
return strftime("%d %B %Y", ts)
except OSError:
return ""
def SecsModificacionPostDesdeJson(archivo, dict_json):
''' dado el post con nombre 'archivo' busca en 'dict_json' el
attribute 'date' y luego obtiene los segundos totales desde
esa fecha.
Si no encuentra 'date' para 'archivo' en 'dict.json'
retorna los segundos totales desde la ultima modificacion
del archivo de post directamente (usa os.path.getmtime)
'''
nombre = archivo.split('.md')[0] # no contar extension .md
nombre_con_ruta = os.path.join("monomotapa/src/posts", archivo)
date_str = dict_json.get('posts/'+nombre, {}).\
get('attributes',{}).\
get('date','')
if date_str == '':
# el post no tiene "date" en pages.json
return os.path.getmtime(nombre_con_ruta)
else:
time_struct = strptime(date_str, '%Y-%m-%d')
dt = datetime.datetime.fromtimestamp(mktime(time_struct))
return (dt - datetime.datetime(1970,1,1)).total_seconds()
def noticias_recientes(cantidad=11, max_caracteres=250,
categoria=None, pagina=0):
'''Devuelve una lista con hasta `cantidad' de posts mas recientes,
un maximo de `max_caracteres' de caracteres del principio del post y
el numero total de posts encontrados
Si se proporciona `categoria' devuelve la lista de posts solamente
pertenecientes esa categoria.
Si `pagina' > 0 se devulve hasta `cantidad' numero de posts en el
rango de [ cantidad*pagina : cantidad*(pagina+1)]
Cada elemento de la lista devuelta contiene:
(nombre_post, ultima_modificacion, cabeza_archivo, categorias)
Al final se retorna: (lista_posts, numero_de_posts)
'''
lista_posts = []
lp = []
num_posts = 0
posts_en_categoria = []
if categoria is not None:
#posts_en_categoria = categorias_list(categoria)[1]
posts_en_categoria = categoriasList(categoria)[1]
# categoria especial fotos
if categoria == "fotos":
l = []
for p in posts_en_categoria:
l.append(p + '.md')
posts_en_categoria = l
try:
ow = os.walk("monomotapa/src/posts")
p,d,files = ow.__next__()
#p,d,files=ow.next()
except OSError:
print ("[posts] - Error: Can't os.walk() on monomotapa/src/posts except OSError.")
else:
for f in files:
nombre_con_ruta = os.path.join("monomotapa/src/posts", f)
if not f.endswith("~") and not f.startswith("#") and not f.startswith("."):
secs_modificacion = SecsModificacionPostDesdeJson(f, json_pattrs)
ultima_modificacion = os.path.getmtime(nombre_con_ruta)
previewChars = json_pattrs.get('posts/'+f[:-3], {}).\
get('attributes', {}).\
get('preview-chars', max_caracteres)
if categoria is not None:
if f in posts_en_categoria:
lp.append((secs_modificacion,
ultima_modificacion,
previewChars,
f))
num_posts += 1
else:
lp.append((secs_modificacion,
ultima_modificacion,
previewChars,
f))
num_posts += 1
lp.sort()
lp.reverse()
# seleccionado por paginas
lp = lp[cantidad*pagina : cantidad*(pagina+1)]
# colocando fecha en formato
for tupla in lp:
cfecha = ctime(tupla[1])
nombre_post = tupla[3].split(os.sep)[-1]
previewChars = tupla[2]
#contenido = cabeza_post(tupla[3], max_caracteres=previewChars)[0]
#categorias = cabeza_post(tupla[3], max_caracteres=previewChars)[1]
contenido = cabezaPost(tupla[3], max_caracteres=previewChars)[0]
categorias = cabezaPost(tupla[3], max_caracteres=previewChars)[1]
cabeza_archivo = markdown.markdown(escape(contenido + ' ...'))
lista_posts.append((nombre_post[:-3], cfecha, \
cabeza_archivo, categorias))
return (lista_posts, num_posts)
def noticias_relacionadas(cantidad=5, nombre=None):
"""Retorna una lista con posts relacionadas, es decir que tienen son de las
mismas categorias que el post con nombre `nombre'.
Cada elemento de la lista de posts contiene el nombre del post
"""
#categorias = categorias_de_post(nombre) ## TODO: corregir categorias de post
categorias = categoriasDePost(nombre)
numero = 0
if categorias is None:
return None
posts = []
for categoria in categorias:
#lista = categorias_list(categoria)[1] # nombres de posts
lista = categoriasList(categoria)[1]
numero += len(lista)
for nombre_post in lista:
if nombre_post + '.md' != nombre:
posts.append(nombre_post)
if numero >= cantidad:
return posts
return posts
def rss_ultimos_posts_jinja(cantidad=15):
"""Retorna una lista de los ultimos posts preparados para
ser renderizados (usando jinja) como un feed rss
Examina cada post del mas reciente al menos reciente, en
total `cantidad' posts. Por cada post devuelve:
id: id which identifies the entry using a
universally unique and permanent URI
author: Get or set autor data. An author element is a dict containing a
name, an email adress and a uri.
category: A categories has the following fields:
- *term* identifies the category
- *scheme* identifies the categorization scheme via a URI.
- *label* provides a human-readable label for display
comments: Get or set the the value of comments which is the url of the
comments page for the item.
content: Get or set the cntent of the entry which contains or links to the
complete content of the entry.
description(no contiene): Get or set the description value which is the item synopsis.
Description is an RSS only element.
link: Get or set link data. An link element is a dict with the fields
href, rel, type, hreflang, title, and length. Href is mandatory for
ATOM.
pubdate(no contiene): Get or set the pubDate of the entry which indicates when the entry
was published.
title: the title value of the entry. It should contain a human
readable title for the entry.
updated: the updated value which indicates the last time the entry
was modified in a significant way.
"""
lista_posts = []
lp = []
num_posts = 0
try:
ow = os.walk("monomotapa/src/posts")
p,d,files=ow.__next__()
except OSError:
print ("[posts] - Error: Can't os.walk() on monomotapa/src/posts except OSError.")
else:
for f in files:
nombre_con_ruta = os.path.join("monomotapa/src/posts", f)
if not f.endswith("~") and not f.startswith("#") and not f.startswith("."):
lp.append((os.path.getmtime(nombre_con_ruta), f))
num_posts += 1
if num_posts > cantidad:
break
lp.sort()
lp.reverse()
# colocando fecha en formato
for tupla in lp:
nombre_post = tupla[1].split(os.sep)[-1]
#contenido = cabeza_post(tupla[1], max_caracteres=149999)
contenido = cabezaPost(tupla[1], max_caracteres=149999)
id_post = "https://rmgss.net/posts/"+nombre_post[:-3]
#categorias = categorias_de_post(nombre_post)
categorias = categoriasDePost(nombre_post)
dict_categorias = {}
c = ""
for cat in categorias:
c += cat + " "
dict_categorias['label'] = c
#dict_categorias['term'] = c
html = markdown.markdown(escape(contenido))
link = id_post
pubdate = ctime(tupla[0])
title = titulo_legible(nombre_post[:-3]) # no incluir '.md'
updated = pubdate
dict_feed_post = {
"id":id_post,
"author": "Rodrigo Garcia",
"category" : categorias,
"content": html,
"link" : id_post,
"updated" : updated,
"title": title
}
lista_posts.append(dict_feed_post)
return lista_posts
###### Define routes
@app.errorhandler(404)
def page_not_found(e):
""" provides basic 404 page"""
defaults = get_page_attributes('defaults.json')
try:
css = defaults['css']
except KeyError:
css = None
pages = get_page_attributes('pages.json')
if '404' in pages:
if'css' in pages['404']:
css = pages['404']['css']
return render_template('static.html',
title = "404::page not found", heading = "Page Not Found",
navigation = top_navigation('404'),
css = css,
contents = Markup(
"This page is not there, try somewhere else.")), 404
@app.route('/users/', defaults={'page': 1})
@app.route('/users/page/<int:page>')
@app.route("/", defaults={'pagina':0})
@app.route('/<int:pagina>')
def index(pagina):
"""provides index page"""
index_page = Page('index')
lista_posts_recientes, total_posts = noticias_recientes(pagina=pagina)
index_page.contexto['lista_posts_recientes'] = lista_posts_recientes
index_page.contexto['total_posts'] = total_posts
index_page.contexto['pagina_actual'] = int(pagina)
return index_page.generate_page()
# default route is it doe not exist elsewhere
@app.route("/<path:page>")
def staticpage(page):
""" display a static page rendered from markdown in src
i.e. displays /page or /page/ as long as src/page.md exists.
srcfile, title and heading may be set in the pages global
(ordered) dictionary but are not required"""
static_page = Page(page)
return static_page.generate_page()
@app.route("/posts/<page>")
def rposts(page):
""" Mustra las paginas dentro la carpeta posts, no es coincidencia
que en este ultimo directorio se guarden los posts.
Ademas incrusta en el diccionario de contexto de la pagina la
fecha de ultima modificacion del post
"""
static_page = Page("posts/"+page)
ultima_modificacion = ultima_modificacion_archivo("posts/"+page)
static_page.contexto['relacionadas'] = noticias_relacionadas(nombre=page+".md")
static_page.contexto['ultima_modificacion'] = ultima_modificacion
static_page.exclude_toc = False # no excluir Índice de contenidos
return static_page.generate_page()
@app.route("/posts")
def indice_posts():
""" Muestra una lista de todos los posts
"""
lista_posts_fecha = posts_list()
#lista_posts_categoria = categorias_list()
lista_posts_categoria = categoriasList()
static_page = Page("posts")
static_page.contexto['lista_posts_fecha'] = lista_posts_fecha
static_page.contexto['lista_posts_categoria'] = lista_posts_categoria
return static_page.generate_page()
@app.route("/posts/categorias")
def lista_categorias():
""" Muestra una lista de las categorias , los posts pertenecen
a cada una y un conteo"""
#lista_categorias = categorias_list()
lista_categorias = categoriasList()
static_page = Page("categorias")
static_page.contexto['lista_posts_categoria'] = lista_categorias
#return (str(lista_categorias))
return static_page.generate_page()
@app.route("/posts/categoria/<categoria>")
def posts_de_categoria(categoria):
""" Muestra los posts que perteneces a la categoria dada
"""
lista_posts = []
if categoria == "fotos": # caegoria especial fotos
lista_posts, total_posts = noticias_recientes(max_caracteres=1250,categoria=categoria)
static_page = Page("fotos")
static_page.contexto['categoria_actual'] = categoria
static_page.contexto['lista_posts_recientes'] = lista_posts
return static_page.generate_page()
#lista_posts = categorias_list(categoria=categoria)
lista_posts = categoriasList(categoria=categoria)
static_page = Page("categorias")
static_page.contexto['categoria_actual'] = categoria
static_page.contexto['lista_posts_categoria'] = lista_posts
return static_page.generate_page()
@app.route("/posts/recientes", defaults={'pagina':0})
@app.route("/posts/recientes/<int:pagina>")
def posts_recientes(pagina):
""" muestra una lista de los posts mas recientes
TODO: terminar
"""
lista_posts, total_posts = noticias_recientes(max_caracteres=368,
pagina=pagina)
static_page = Page("recientes")
static_page.contexto['lista_posts_recientes'] = lista_posts
static_page.contexto['total_posts'] = total_posts
static_page.contexto['pagina_actual'] = pagina
#return (str(lista_posts))
return static_page.generate_page()
@app.route("/contacto", methods=['GET'])
def contacto():
tupla_captcha = captcha_pregunta_opciones_random()
if tupla_captcha is None:
return ("<br>Parece un error interno!</br>")
pregunta = tupla_captcha[0]
opciones = tupla_captcha[1]
static_page = Page("contacto")
static_page.contexto['pregunta'] = pregunta
static_page.contexto['opciones'] = opciones
return static_page.generate_page()
@app.route("/contactoe", methods=['POST'])
def comprobar_mensaje():
""" Comprueba que el mensaje enviado por la caja de texto sea valido
y si lo es, guarda un archivo de texto con los detalles"""
errors = []
if request.method == "POST":
# comprobando validez
nombre = request.form["nombre"]
dir_respuesta = request.form['dir_respuesta']
mensaje = request.form['mensaje']
pregunta = request.form['pregunta']
respuesta = request.form['respuesta']
if len(mensaje) < 2 or mensaje.startswith(" "):
errors.append("Mensaje invalido")
if not captcha_comprobar_respuesta(pregunta, respuesta):
errors.append("Captcha invalido")
if len(errors) > 0:
return str(errors)
# guardando texto
texto = "Remitente: "+nombre
texto += "\nResponder_a: "+dir_respuesta
texto += "\n--- mensaje ---\n"
texto += mensaje
# TODO: cambiar a direccion especificada en archivo de configuracion
dt = datetime.datetime.now()
nombre = "m_"+str(dt.day)+"_"+str(dt.month)+\
"_"+str(dt.year)+"-"+str(dt.hour)+\
"-"+str(dt.minute)+"-"+str(dt.second)
with open(os.path.join("fbs",nombre), "wb") as f:
f.write(texto.encode("utf-8"))
return redirect("/mensaje_enviado", code=302)
@app.route("/mensaje_enviado")
def mensaje_enviado():
static_page = Page("mensaje_enviado")
return static_page.generate_page()
@app.route("/rss")
def rss_feed():
"""Genera la cadena rss con las 15 ultimas noticias del sitio
TODO: Agregar mecenismo para no generar los rss feeds y solo
devolver el archivo rss.xml generado anteriormente. Esto
quiere decir solamente generar el rss_feed cuando se haya hecho
un actualizacion en los posts mas reciente que la ultima vez
que se genero el rss_feed
"""
#return str(rss_ultimos_posts_jinja())
return render_template("rss.html",
contents = rss_ultimos_posts_jinja())
#**vars(self)
#)
##### specialized pages
@app.route("/source")
def source():
"""Display source files used to render a page"""
source_page = Page('source', title = "view the source code",
#heading = "Ver el código fuente",
heading = "Ver el codigo fuente",
internal_css = get_pygments_css())
page = request.args.get('page')
# get source for markdown if any. 404's for non-existant markdown
# unless special page eg source
pagesrc = source_page.get_page_src(page, 'src', 'md')
special_pages = ['source', 'unit-tests', '404']
if not page in special_pages and pagesrc is None:
abort(404)
# set enable_unit_tests to true in config.json to allow
# unit tests to be run through the source page
if app.config['enable_unit_tests']:
contents = '''<p><a href="/unit-tests" class="button">Run unit tests
</a></p>'''
# render tests.py if needed
if page == 'unit-tests':
contents += heading('tests.py', 2)
contents += render_pygments('tests.py', 'python')
else:
contents = ''
# render views.py
contents += heading('views.py', 2)
contents += render_pygments(source_page.get_page_src('views.py'),
'python')
# render markdown if present
if pagesrc:
contents += heading(os.path.basename(pagesrc), 2)
contents += render_pygments(pagesrc, 'markdown')
# render jinja templates
contents += heading('base.html', 2)
contents += render_pygments(
source_page.get_page_src('base.html', 'templates'), 'html')
template = source_page.get_template(page)
contents += heading(template, 2)
contents += render_pygments(
source_page.get_page_src(template, 'templates'), 'html')
return source_page.generate_page(contents)
# @app.route("/unit-tests")
# def unit_tests():
# """display results of unit tests"""
# unittests = Page('unit-tests', heading = "Test Results",
# internal_css = get_pygments_css())
# # exec unit tests in subprocess, capturing stderr
# capture = subprocess.Popen(["python", "tests.py"],
# stdout = subprocess.PIPE, stderr = subprocess.PIPE)
# output = capture.communicate()
# results = output[1]
# contents = '''<p>
# <a href="/unit-tests" class="button">Run unit tests</a>
# </p><br>\n
# <div class="output" style="background-color:'''
# if 'OK' in results:
# color = "#ddffdd"
# result = "TESTS PASSED"
# else:
# color = "#ffaaaa"
# result = "TESTS FAILING"
# contents += ('''%s">\n<strong>%s</strong>\n<pre>%s</pre>\n</div>\n'''
# % (color, result, results))
# # render test.py
# contents += heading('tests.py', 2)
# contents += render_pygments('tests.py', 'python')
# return unittests.generate_page(contents)
Coronavirus-y-su-relación-con-el-trato-a-la-naturaleza.md
Desde los primeros meses de 2020 gran parte del mundo, ha sido forzado a detener el estilo de vida habitual por las medidas que tomaron varios países para evitar el contagio acelerado del coronavirus, una enfermedad causada por el síndrome respiratorio agudo grave [SARS-CoV-2](https://es.wikipedia.org/wiki/SARS-CoV-2).
Este post esta dividido en secciones, con el fin de analizar y compartir algunos artículos y reflexiones sobre como debería cambiar nuestra relación con la naturaleza a causa de la pandemia.
## El origen del SARS-COV-2
<img src="https://upload.wikimedia.org/wikipedia/commons/d/d2/Pandemics_transmitted_by_Eating_Animals_ENG_%26_CHINESE_%28blue%29.-1.jpg" width="620">
<span class="foto_nota">Epidemias y pandemias provenientes del consumo de carne animal y ganado. Imagen de [Fangpila](https://commons.wikimedia.org/wiki/File:Pandemics_transmitted_by_Eating_Animals_ENG_%26_CHINESE_(blue).-1.jpg)</span>
Hay varias teorías sobre el posible origen, pero una de las mejores respaldadas es que el SARS-CoV-2 es de origen zoonótico y que fue transmitida de animales a humanos, una enfermedad infecciosa desde una especie animal a la nuestra. Por ejemplo un estudio dice que el SARS-CoV-2 no es un diseño de laboratorio o un virus fabricado a propósito[[3]](#ref_3). Al parecer el SARS-CoV-2 no tiene como pariente más cercano al SARS-CoV-1, sino se han encontrado más parecidos en virus presentes en murciélagos y en pangolines malayos, aunque la transmisión directa desde estos mamíferos a los humanos es poco probable[[1]](#ref_1). Si la transmisión es poco probable, ¿qué ha causado que se den las condiciones?.
Hay un dato que dice que más del 70% de las infecciones emergentes en los últimos cuarenta años han sido zoonosis[[17]](#ref_17), es decir, enfermedades infecciosas causadas por bacterias, virus, hongos o parásitos que se transmiten de los animales a los humanos[[2]](#ref_2). Nuestra especie ha estado en contacto con animales desde tiempos inmemorables y siempre ha estado expuesta a enfermedades infecciosas, por tanto el «intercambio» de microorganismos entre humanos y animales está presente y es un proceso natural. Sin embargo, todo proceso natural lleva tiempo y cada especie asimila ese intercambio a su ritmo.
El contacto progresivo hace que se generen cambios biológicos **progresivos**, pero el contacto súbito o en condiciones desfavorables para una especie provoca cambios **súbitos**. Un ejemplo claro son las especies amenazadas o en peligro de extinción, el estrés y sufrimiento que experimentan hace que sus **defensas bajen** y por tanto **no puedan** generar anticuerpos por si mismas para controlar enfermedades que en condiciones normales podían.
En el caso del SARS-CoV-2, las investigaciones apuntan a que la transmisión se hizo de un animal a un animal intermedio y luego a un ser humano. El animal que transmitió el virus a otro animal intermedio era un murciélago, y el animal intermedio con toda seguridad era un pangolín de acuerdo con el genoma del coronavirus encontrado en estos animales y que se transmitió hasta los humanos. Según esa hipótesis, las características genéticas que hacen que el nuevo coronavirus sea tan patógeno para infectar células humanas, es que residían en esos animales antes de saltar a los humanos.
En China la caza de pangolines los ha puesto en peligro de extición, se mantienen poblaciones de pangolines en cautividad y enjaulados para luego venderlos en mercados o cocinarlos. El mal estado sanitario y la baja inmunidad que afecta a las poblaciones en cautividad son un importante riesgo potencial para la salud humana[[2]](#ref_2).
Resumiendo, mucho apunta a que el SARS-COV-2 (causa del coronavirus) se originó por una mutación en animales víctimas de la caza furtiva y — es una consecuencia directa de la insensibilidad de muchas personas hacia los animales.

<span class="foto_nota">Un pangolín. [Imagen de A. J. T. Johnsingh, WWF-India and NCF](https://commons.wikimedia.org/wiki/File:Pangolin_brought_to_the_Range_office,_KMTR_AJTJ_cropped.jpg)</span>
## ¿El covid-19 es una consecuencia?
La respuesta es; la pandemia por el coronavirus de 2019 y 2020 es una clara consecuencia de las acciones de los seres humanos, en especial las relacionadas a la destrucción de ecosistemas naturales y vida silvestre.
### Destrucción de ecosistemas
Se sabe que una especie vegetal o animal no es amenazada sólo por la caza o consumo, también esta la pérdida de su ecosistema u otros cambios desfavorables. La destrucción de ecosistemas naturales ha crecido de forma alarmante en las últimas décadas. Sin las condiciones ni el lugar adecuado los seres vivos no pueden prosperar y la supervivencia se vuelve cada vez más difícil.
#### Bosques primarios
<img src="https://upload.wikimedia.org/wikipedia/commons/b/b9/Deforestation_2074483b.jpg" width="560" alt="Deforestation 2074483b" >
<span class="foto_nota">Deforestación. Imagen de [Dikshajhingan](https://commons.wikimedia.org/wiki/File:Deforestation_2074483b.jpg)</span>
Un [bosque primario](https://es.wikipedia.org/wiki/Bosque_primario) o virgen, es un bosque que no ha sido intervenido por la especie humana, es un lugar con gran **biodiversidad** y tiene gran capacidad de atrapar el CO2 de la atmósfera, mitigando el cambio climático. Los manglares y humedales son otro ejemplo de ecosistema que atrapa gran cantidad de CO2[[9]](#ref_9).
A nivel global, un informe señala que la pérdida de bosque primario en 2019 representa un aumento global de 2.8% respecto a la pérdida del año anterior. Y aunque fue menor que la de los años record de 2016 y 2017, es la tercera peor tasa de pérdida en los últimos 20 años[[8]](#ref_8).
La amazonía es un área rica en bosques vírgenes, pero esa riqueza se va perdiendo debido a la desenfrenada deforestación en países como Brasil, Argentina, Bolivia, Perú y otros en América Latina. Es difícil imaginar la destrucción causada, pero según datos publicados en Global Forest Watch (GFW), en 2019 los trópicos perdieron 11,9 millones de hectáreas de cobertura arbórea. Casi un tercio de esa pérdida, 3,8 millones de hectáreas, ocurrió en bosques primarios tropicales húmedos. Esto es equivalente a perder un campo de Futbol de selva cada 6 segundos[[10]](#ref_10).
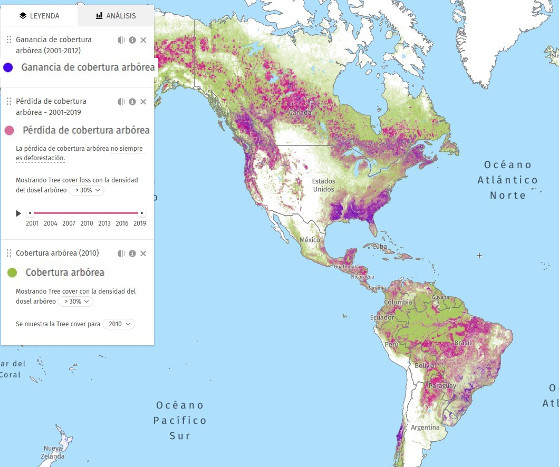
<span class="foto_nota">Mapa de pérdida, ganancia y cobertura arbórea de 2001 a 2019. Extraído de [https://www.globalforestwatch.org/map/](https://www.globalforestwatch.org/map/) en Julio de 2020.</span>
El gráfico anterior se centra en América, muestra en color rosado la pérdida de cobertura arbórea de 2001 a 2019. La ganancia en azul de 2001 a 2012 y en color verde la cobertura arbórea que se mantiene.
Vemos claramente que la pérdida es especialmente alta en la región de la amazonía en Brasil, Perú y Bolivia. El norte argentino y Paraguay también muestran gran pérdida seguidos de Colombia, Ecuador y otros países.
En contraste, en Norteamérica a pesar de también existir una gran pérdida de cobertura árborea, también hay zonas con una considerable ganancia. Sin embargo, hay estudios que indican que estos nuevos árboles ganados en el hemisferio norte a nivel mundial «no se comparan» con el bosque primario perdido en Sudamérica en términos de biodiversidad. Un artículo dice: "Los árboles establecidos en el hemisferio norte en años recientes no tienen el mismo impacto que los bosques primarios de Brasil en dos parámetros clave: la capacidad de albergar biodiversidad y la capacidad de absorber y secuestrar dióxido de carbono" [[11]](#ref_11).
En 2019, los bosques sufrieron masivos incendios en especial en Brasil, Bolivia y Australia, pero aún así, los incendios no fueron la principal causa de pérdida de bosque primario en Brasil [[8]](#ref_8). Las causas principales de la deforestación en nuestros países tienen que ver con factores que analizaremos más adelante.
Bolivia tuvo una pérdida de cobertura arbórea sin precedentes en bosques primarios y zonas circundantes. Según GFW, en el 2019, la pérdida total en el país fue un **80 % más alta** que la del año con la mayor pérdida registrada hasta la fecha (que fue 2016). GFW indica que **la actividad agropecuaria a gran escala** fue el conductor principal de la deforestación en Bolivia, especialmente para la siembra de soya y ganadería[[12]](#ref_12).
De acuerdo con GFW la pandemia del coronavirus plantea más amenazas para los bosques del mundo en los meses y años por delante. Y a corto plazo, los bosques pueden verse afectados por una falta de vigilancia y control, lo que puede dar lugar a una mayor incidencia de desmonte ilegal e incendios[[12]](#ref_12). Entonces es lógico suponer que mientras la mayoría de la población en Bolivia debe acatar el confinamiento para controlar el contagio masivo del coronavirus, los desmontes van avanzando sin parar.
Argentina que es uno de los 10 países del mundo con más deforestación, de igual forma ha suspendido la mayoría de las actividades, pero el agronegocio destruyó 200 hectáreas por día de monte nativo [[13]](#ref_13). —¿Cúanto daño más va a sufrir la selva y los bosques antes de que se tomen medidas y políticas de protección?.
La destrucción de los ecosistemas naturales tiene graves consecuencias no sólo para las especies que viven en ellas, también tienen su efecto a nivel global, y, permitiendo que continúe, se permite que quienes destruyen la vida del planeta que nos acoge, queden impunes y sean cada vez más insensibles realizando estos actos.
### Vida silvestre afectada por la destrucción de bosques
<img width="460" alt="Sumatran Rhinoceros - Rapunzel" src="https://upload.wikimedia.org/wikipedia/commons/thumb/7/7e/Sumatran_Rhinoceros_-_Rapunzel.jpg/512px-Sumatran_Rhinoceros_-_Rapunzel.jpg">
<span class="foto_nota">Rinoceronte de Sumatra, una especie muy afectada por la destrucción de sus bosques. Foto de [nicolaitan](https://commons.wikimedia.org/wiki/File:Sumatran_Rhinoceros_-_Rapunzel.jpg)</span>
Incluso luego de la deforestación y si la zona deforestada se deja intacta, los árboles pueden vuelven a crecer y en el mediano plazo se podría restaurar la flora del bosque. Pero los animales (la fauna) no, una especie animal puede requerir mucho más tiempo para recuperarse y puede que no lo haga nunca más.
Sólo en el caso de Bolivia durante los incendios forestales del bosque seco Chiquitano, hay varias estimaciones sobre la muerte de animales pero se maneja una cifra de mas de dos millones de animales salvajes[[14]](#ref_14) y hay algunos que opinan que la Chiquitania no podrá recuperarse.
Con relación a los incendios del bosque Seco Chiquitano en 2019, no encontré muchos estudios que cuantifiquen los daños en la fauna. Un estudio que analiza el impacto en el hábitat del Jaguar (por el rol ecológico de este) indica que el 17% del área total de su hábitat en el bosque Modelo Chiquitano resultó quemada[[15]](#ref_15). El hábitat del Jaguar es muy extenso, en el bosque Chiquitano existen otras especies cuyos ecosistemas fuerón afectados y cubren menos extensión, y por el daño a estos ecosistemas seguramente estas resultarón diezmadas.
En ecosistemas diversos como los bosques, cuando el hábitat de los animales es destruido estos pierden el lugar en donde viven y se alimentan. Los que consiguen huir de la destrucción sufren de hambruna y buscan nuevos territorios para vivir. En ese proceso se pueden convertir en **especies invasoras** porque ocupan el territorio en el que otras especies viven y si llegan a sobrevivir en el nuevo hábitat, causan un impacto sobre este. Por ejemplo consumen el alimento que normalmente consumían otras especies, modifican el ecosistema, pueden traer **nuevas enfermedades**, etc. Aunque la «invasión» de hábitats es normal en especies animales, la «invasión forzada» (en este caso por la destrucción provocada por el hombre) resulta en desbalances descontrolados.
### Intereses económicos y de poder
¿Qué es lo que hace que muchas personas se ocupen en causar los daños mencionados por la destrucción de ecosistemas y el tráfico ilegal de animales? ¿cúales son las causas?
De seguro que hay muchas y hasta cierto punto se pueden considerar muy difíciles de evitar, pero la forma en que esto ocurre como ha estado ocurriendo en los últimos años hace que se noten motivaciones comunes como ser:
- Agricultura
- Industria maderera
- Industria de bio combustibles
- Ganadería
- Minería
- Caza Furtiva
- Construcción de carreteras
- Asentamientos
Las causas citadas anteriormente comparten su origen en intereses económicos, analizaremos brevemente algunas de estas a continuación:
#### Agricultura
<img width="512" alt="Train in corn field (15320086036)" src="https://upload.wikimedia.org/wikipedia/commons/thumb/7/76/Train_in_corn_field_%2815320086036%29.jpg/512px-Train_in_corn_field_%2815320086036%29.jpg">
<span class="foto_nota">Tren en un campo de maíz. Foto de [David McCormack](https://commons.wikimedia.org/w/index.php?curid=36785700).</span>
La agricultura una actividad milenaria y de vital importancia para la producción de alimentos pero que últimamente ha sido llevada una escala difícil de imaginar hace unos siglos, a esta actividad masiva se le conoce como [agricultura industrial o intensiva](https://es.wikipedia.org/wiki/Agricultura_intensiva).
Debido a la población mundial, hay una gran necesidad de alimentos y otros productos de la actividad agrícola. Pero muchas «técnicas» que se usan masivamente deterioran los suelos y ecosistemas. Por ejemplo el **monocultivo** o el exceso de producción, el **ignorar** el rol ecológico que cumple una zona que se va a destinar a la agricultura, la aplicación irresponsable de químicos agrotóxicos y uso de otras especies invasoras para mejorar la rentabilidad agrícola, etc. La agricultura industrial usa enormes cantidades de agua, energía y químicos industriales, lo que incrementa la contaminación en la tierra cultivable y agua [[18]](#ref_18).
Existen grupos de empresarios y gobiernos que prefieren "enriquecerse" y no detenerse a pesar de las consecuencias de su enriquecimiento, por ejemplo en Bolivia hay quienes responsabilizan al agronegocio ya que el 90% de los incendios forestales anuales se dan entre Santa Cruz y Beni que son los departamentos que concentran prácticamente al empresariado agropecuario del país[[19]](#ref_19). En Argentina los monocultivos transgénicos de soja y maíz se plantan sobre zonas boscosas devastadas masivamente incluso durante la cuarentena por el coronavirus [[13]](#ref_13).
Si bien debido al crecimiento poblacional esta actividad es importante, muchas empresas aprovechan la situación para expandir su actividad de forma descontrolada y como esta actividad genera ganancias económicas importantes, muchos empresarios se convierten en una poderosa **influencia política** en los gobiernos que flexibilizan las regulaciones y se deslindan de implementar políticas de protección al medio ambiente. En países como Argentina, Brasil, Bolivia, Uruguay, Paraguay, Ecuador, Chile entre otros, se desplazan de sus territorios a poblaciones indígenas originarias en favor de la agricultura, ganadería y minería.
Además del desplazamiento, la concentración de tierras recae en su mayoría en grandes empresas y cada vez menos en productores agropecuarios independientes. En Argentina a 2018 donde menos del 1% de las explotaciones agropecuarias controla el 36.4% de tierra y el 55% de los pequeños productores concentran el 2.2% de la tierra, en Bolivia el 70% de la tierra es controlada por el 2% de los productores[[20]](#ref_20). Este y otros hechos son signos claros de una gran influencia que ejercen las personas que controlan este negocio en los países de Sudamérica.
#### Ganadería
<img width="540" alt="Ganado en Apure" src="https://upload.wikimedia.org/wikipedia/commons/4/46/Ganado_en_Apure.jpg">
<span class="foto_nota">Gnando en Apure, Venezuela. Foto de [Fhaidel](https://commons.wikimedia.org/wiki/File:Ganado_en_Apure.jpg)</span>
La ganadería es otro gran impulso para la depredación de ecosistemas y amenaza a la vida salvaje en todo el mundo. Esta actividad requiere mucho más espacio abierto que la agricultura y por los desechos que produce el ganado se libera gas metano que contribuye al efecto invernadero y cambio climático.

<span class="foto_nota">¿Qué se necesita para hacer una hamburguesa de 250 gramos?. Ilustración de extraída de ["El precio de la carne" - Tunupa 103/2017](https://funsolon.files.wordpress.com/2018/02/tunupa-103-color.pdf), Fundación Solón.</span>
La ganadería principalmente bovina es también causante de desmontes e incendios forestales para que el ganado se alimente de pastizales, la selva tropical más grande del mundo está siendo destruida principalmente para alimentar ganado y los costos de derribar árboles y convertir la tierra en praderas se pueden cubrir con la venta de madera[[21]](#ref_21). Este es por tanto un gran impulso para inversionistas que buscan generar ingresos con la menor pérdida económica posible. Un artículo[[13]](#ref_13) dice sobre los estragos causados por el agronegocio en Argentina:
> Las vacas pastando apacibles, esas imágenes que aparecen impresas en etiquetas de supermercado, esconden la violencia del fuego y también lo que ocurre después, el paso a paso del agronegocio que muchas personas desconocen. Los monocultivos transgénicos de soja y maíz que se implantan sobre las cenizas y son regados con venenos, bajo un sol de 50 grados.
Según éste mismo, 50% de los niños son pobres y comen poco. Es importante recordar que el consumo de carne tiene un precio alto sobre el medio ambiente, y al no controlar los hábitos de consumo de carne se contribuye a que desastres como el covid-19 y mucho peores sigan ocurriendo por ser este una consecuencia de invadir espacios naturales motivados por el agronegocio.
#### Caza Furtiva
La caza furtiva de murciélagos y pangolines en China es un negocio lucrativo que prefiere ignorar las consecuencias para estas especies y por ende para toda la humanidad. Asumiendo que el SARS-CoV-2 tiene origen zoonótico, — el covid-19 es una de las consecuencias del tráfico de animales silvestres.
La caza furtiva es un multimillonario negocio que genera hasta 23000 millones de dólares americanos, donde la cadena empieza con el cazador, que por un intermediario o mercados locales, contacta con el comerciante de un país en tránsito. Al llegar al país comprador, las especies pueden terminar como mascotas, comida, medicamentos o bienes de consumo. Y donde el 80% del comercio ilegal corresponde a marfil, reptiles, aves, pangolines, otros mamíferos y productos marinos[[22]](#ref_22).
En la actualidad se sabe que hay más tigres en cautiverio que en la vida salvaje en todo el mundo, y mientras incrementan las incautaciones, los traficantes se vuelven más esquivos[[16, 22]](#ref_22). Pero los traficantes y toda la red de captura y transporte no son los únicos responsables, los consumidores que prefieren ignorar (voluntaria o involuntariamente) el daño causado a la especie animal que compran son «el mercado» que alimenta la voraz matanza de vida silvestre inocente.
Un informe de la ONU dice que los marcos regulatorios para la protección de especies traficadas son limitados e inconsistentes, donde cada país puede ser una fuente de tránsito o destino y según el papel que desempeñan deberían prevenir y abordar estos crímenes con un enfoque integral que apunte a las bases de oferta y demanda[[23]](#ref_23).
#### Caza y tráfico ilegal relacionado al covid-2019
<img width="512" alt="Myanmar Illicit Endangered Wildlife Market 04 (cropped)" src="https://upload.wikimedia.org/wikipedia/commons/thumb/6/69/Myanmar_Illicit_Endangered_Wildlife_Market_04_%28cropped%29.jpg/512px-Myanmar_Illicit_Endangered_Wildlife_Market_04_%28cropped%29.jpg">
<span class="foto_nota">Foto del comercio ilícito de vida salvaje en un mercado. Foto de [Dan Bennet](https://commons.wikimedia.org/wiki/File:Myanmar_Illicit_Endangered_Wildlife_Market_04_(cropped).jpg)</span>
Si asumimos que el SARS-CoV-2 es una consecuencia de la caza y [comercialización de pangolines](https://en.wikipedia.org/wiki/Pangolin_trade), esto significa que esta y otras actividades similares deben detenerse por el bien de la salud pública.
En China luego del brote del coronavirus se han cerrado algunos mercados de comercialización de vida silvestre que incluían pangolines. La comercialización de muchas especies de pangolín esta internacionalmente prohibida, a pesar de esto, se dice que el pangolín es uno de los mamíferos más traficados en el mundo, por su carne o el uso de sus escamas en la medicina tradicional China entre otros [[16]](#ref_16). Durante la pandemia, mientras se aplican medidas y restricciones globales de viajes para transporte de personas, los métodos de transporte que usa el crimen organizado para el comercio de animales silvestres probablemente se ve menos afectado. Incluso por la gran disminución del turismo y el aumento de la pobreza, la caza furtiva puede tender a aumentar [[17]](#ref_17).
El tráfico de animales no sólo representa un riesgo para la salud y una importante causa de pérdida de biodiversidad, —también engrandece una costumbre soberbia que alimenta la idea de que los seres humanos son superiores a otras especies de animales. Esta idea retrasa el progreso y desarrollo sostenible de la humanidad, empeora la calidad de vida de otras especies y de la especie humana, y destruye formas de vida diversas. Los animales cazados, enjaulados o separados de sus congéneres, sufren enormemente sus pérdidas.
### Impacto de las medidas de confinamiento en el medio ambiente
De muchas formas el COVID-2019 ha causado consecuencias en el planeta, nos centraremos en algunas que tienen que ver con el medio ambiente.
#### Emisiones de CO2 durante la cuarentena
Debido a la implementación de medidas de confinamiento en muchos países, el uso de transporte motorizado ha disminuido considerablemente y esta reducción se ha traducido en una rápida reducción de la contaminación del aire y emisiones de dióxido de carbono (CO2).
Desde los primeros días de la cuarentena, en China se han ido registrando los más bajos niveles de emisiones de CO2 y otros gases de efecto invernadero desde la crisis financiera hace una década. Las emisiones principalmente provenientes de automóviles y camiones cayeron un 50%. Las proyecciones iban esperando que las emisiones sean las más bajas en el hemisferio norte desde 2009 [[4]](#ref_4).
A pesar de que los reportes de emisiones de CO2 son anuales, existen datos mensuales de distintas fuentes y mediante estimaciones se hizo un análisis, en el cual, para mayo de 2020 se registró que debido a la reducción en el transporte aéreo y terrestre las emisiones diarias de CO2 se redujeron a los niveles del año 2009[[5]](#ref_5).
<img src="https://media.springernature.com/full/springer-static/image/art%3A10.1038%2Fs41558-020-0797-x/MediaObjects/41558_2020_797_Fig3_HTML.png?as=webp" width="560">
<span class="foto_nota">Reducción temporal de emisiones globales de CO2 durante el confinamiento por el COVID-19. Imagen de [https://www.nature.com/articles/s41558-020-0797-x/figures/3](https://www.nature.com/articles/s41558-020-0797-x/figures/3)</span>
Esta disminución en las emisiones habría sido prácticamente imposible en circunstancias normales. El siguiente gráfico muestra las emisiones por sector o actividad.
<img src="https://media.springernature.com/full/springer-static/image/art%3A10.1038%2Fs41558-020-0797-x/MediaObjects/41558_2020_797_Fig4_HTML.png?as=webp" width="560">
<span class="foto_nota">Cambios en emisiones globales de CO2 por sector. Imagen de [https://www.nature.com/articles/s41558-020-0797-x/figures/4](https://www.nature.com/articles/s41558-020-0797-x/figures/4)</span>
Claramente se ve la disminución drástica en los sectores de transporte terrestre y aviación y un ligero incremento en el sector de energía para uso residencial.
A pesar del incremento de la [huella de carbono](https://es.wikipedia.org/wiki/Huella_de_carbono) resultante de la generación de energía para calefacción, la disminución en el transporte hace que haya un descenso global.
Es bueno recordar que la disminución en las emisiones durante la cuarentena es temporal y lo más seguro es que estas vuelvan a subir a medida que se normalizan las actividades. Por lo que, es necesario comenzar a desarrollar nuevas estrategias que busquen encaminarnos a nuevas formas de vida menos contaminantes, y una primera meta podría ser disminuir aún más las emisiones de clorofluorocarbonos e hidroclorofluorocarbonos (los químicos culpables del daño a la capa de ozono)[[6]](#ref_6).
#### ¿Vida silvestre retomando su lugar?
Durante el confinamiento muchas ciudades han estado más vacías de lo normal, en la ausencia de seres humanos algunos animales han aprovechado el momento para tomar el espacio. Se hicieron famosos muchos videos y reportes de animales silvestres caminando por las ciudades, por ejemplo ciervos, familias de jabalíes, conejos, vizcachas, zorros, pumas, monos, osos, peces, ovejas, etc. Muchos de estos videos se reportaron como falsos y otros no.
Sin embargo hay casos como el de algunas playas, donde la reducción del turismo ha dado espacio a animales como tortugas marinas en peligro de extinción a desovar con tranquilidad[[7]](#ref_7).
Para que más animales se «animen» a tomar las ciudades, tendría que pasar mas tiempo. Pero seguramente ya han habido muchos exploradores que se han aventurado.
## La importancia de la biodiversidad
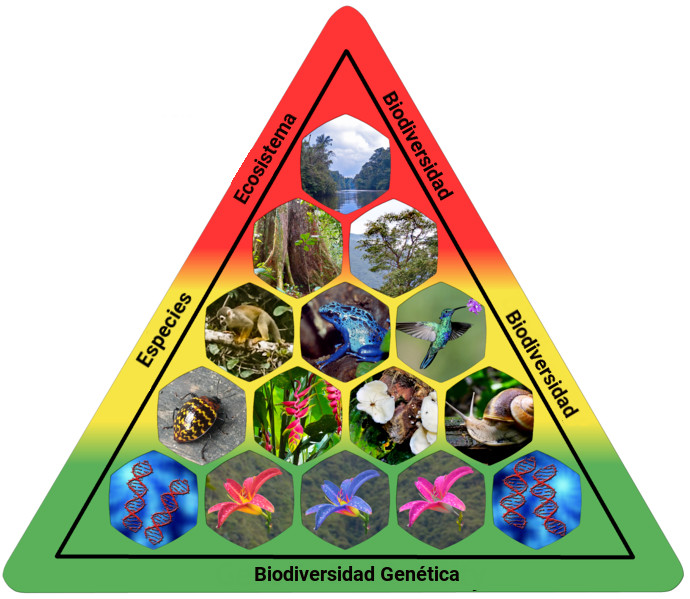
<span class="foto_nota">Pirámide de la biodiversidad. Esta imagen se ha modificado de la original de [Fährtenleser](https://commons.wikimedia.org/wiki/File:Biodiversity_Pyramid_(English).png)</span>
La biodiversidad, es el conjunto de todos los seres vivos del planeta, el ambiente en el que viven y su relación que guardan con otras especies. Se calcula que la biodiversidad mundial podría estar compuesta de 3 a 110 millones de especies y se estima que se necesitarían al menos 200 años al ritmo de descripción anual de especies para llegar a conocer la biodiversidad real[[25]](#ref_25).
La riqueza del mundo reside en su diversidad, miles de millones de años le ha tomado a la vida transformarse, adaptarse, establecerse y llegar al punto actual. La diversidad biológica es el resultado de todo el proceso de incontables experiencias de los seres vivos que han vivido.
> "No son los más fuertes o los más inteligentes los que sobrevivirán, sino los que mejor pueden manejar el cambio".
>
> Leon C. Megginson
El impacto de los humanos en la red de ecosistemas naturales y sus relaciones finamente equilibradas se ha hecho más evidente el último siglo, y uno de los efectos de las acciones humanas en el mundo natural es la reducción generalizada y drástica de la biodiversidad[[24]](#ref_24). En los últimos 100 años el hombre ha acelerado el ritmo de extinción de especies posiblemente 1000 veces respecto al ritmo natural, actualmente se ha alcanzado una extinción de entre 50 a 300 especies cada día, eso es como 100000 especies cada año[[25, 26]](#ref_26).
Una lectura dice: Los procesos y servicios que prestan los ecosistemas sanos, son el fundamento del bienestar de las personas. No sólo al cubrir las necesidades materiales básicas para la supervivencia, sino que son el fundamento de otros aspectos del "vivir bien" como la salud, la seguridad, buenas relaciones sociales y la libertad de elección. Estos procesos se agrupan en cuatro categorías; aprovisionamiento o suministro de bienes, reguladores, culturales, y de apoyo. Sin estos procesos y servicios ecosistémicos como el agua, comida, ropa, medicinas, protección contra el frío y la lluvia, la diversión, la regulación de gases de efecto invernadero, y también la belleza de los espacios naturales, nuestro planeta sería irreconocible[[25]](#ref_25).
La pérdida acelerada de biodiversidad tiene y tendrá un efecto sobre la forma en que vivimos, directa o indirectamente.
Citando del informe de evaluación global sobre la pérdida de biodiversidad de la plataforma intergubernamental Científica-Normativa y servicios de los ecosistemas ([IPEBS](https://ipbes.net/) por sus siglas en inglés):
> - Estamos erosionando los cimientos mismos de nuestras economías, medios de vida, seguridad alimentaria, salud y calidad de vida en todo el mundo.
> - La biodiversidad y las contribuciones de la naturaleza a las personas son nuestro patrimonio común y la 'red de seguridad' más importante de la humanidad para apoyar la vida.
> - Alrededor de un millón de especies animales y vegetales están ahora amenazadas de extinción, muchas en décadas más que nunca antes en la historia de la humanidad.
> - La abundancia media de especies nativas en la mayoría de los principales hábitats terrestres ha disminuido al menos un 20%. Más del 40% de especies de anfibios, casi el 33% de los corales, y más de un tercio de todos los mamíferos marinos están amenazados, la evidencia disponible apoya una estimación tentativa de que el 10% de los insectos está amenazado.
> - Los ecosistemas, las especies, las poblaciones silvestres, las variedades locales y las razas de plantas y animales domesticados se están reduciendo, deteriorando o desapareciendo.
El cambio climático es sólo una consecuencia del impacto que el ser humano causa en el mundo natural y a pesar de que sus consecuencias son enormes, hay muchas personas que todavía niegan que este ocurriendo a causa de las acciones del ser humano, [el artículo corto del siguiente enlace muestra 8 argumentos](https://www.nationalgeographic.com.es/ciencia/8-argumentos-ante-negacionistas-cambio-climatico_14979/1).
El mismo informe del [IPEBS](https://ipbes.net/), indica que los cinco impulsores directos del cambio en la naturaleza con mayor impacto hasta la fecha son:
1. Los cambios en el uso de la tierra y el mar.
2. La explotación directa de los organismos.
3. El cambio climático.
4. La contaminación.
5. Las especies exóticas invasoras.
Para mitigar el impacto del ser humano en los sistemas naturales del planeta, el mantenimiento de la biodiversidad debe ser una prioridad clave, junto con la reducción de las fuentes de cambio ambiental inducido por el hombre[[24]](#ref_24).
Para que las especies proliferen es importante la dispersión a larga distancia (*Long-distance dispersal* en inglés o LDD), para ello las especies requieren **poder recorrer ciertas distancias** y si estas distancias se ven afectadas por la destrucción o fragmentación de los ecosistemas, no sería posible para ellas hacer una LDD adecuada[[29]](#ref_29). Es decir, el proceso de movimiento en el cual las especies obtienen información biológica, es un factor importante para la biodiversidad.
### Pérdida de la biodiversidad relacionada al coronavirus
Es factible relacionar la pérdida de biodiversidad con el brote del coronavirus, así como una especie amenazada impacta a las demás con las que se relaciona, la caza furtiva en Asia ha impactado al pangolín debilitando sus defensas, y a consecuencia de esto se podría haber originado la mutación que resultó en el SARS-COV-2. Los virus asociados con los murciélagos surgieron debido a la pérdida de sus hábitats a causa de la deforestación y expansión agrícola [[27]](#ref_27).

<span class="foto_nota">¿Qué factores aumentan el surgimiento de las zoonosis?. Ilustración extraída de artículo [Seis datos sobre la conexión entre la naturaleza y el coronavirus](https://www.unenvironment.org/es/noticias-y-reportajes/reportajes/seis-datos-sobre-la-conexion-entre-la-naturaleza-y-el-coronavirus)</span>
Algo que es evidente en especial es que debido al coronavirus se ha reaccionado mayoritariamente **sin atacar a las causas de la pandemia**, como cuando una persona se enferma y se tratan sus síntomas sin mirar de dónde viene el problema.
Muchas personas expertas en zoonosis señalan que estamos creando demasiados problemas manteniendo e incluso aumentando la demanda de proteína animal con la ganadería intensiva no sostenible. Esto hace que en muchos establecimientos los animales estén hacinados, donde se seleccionan a las razas del mismo tipo genético para que crezcan lo más rápido posible, a causa de esto, estos animales tienen un sistema inmunológico debilitado y por tanto más susceptible a patógenos. Si no se atacan las causas de las pandemias, vendrán otras mucho más graves que la del covid-19[[28]](#ref_28).
## Reconstrucción post-pandemia
Estamos padeciendo las consecuencias de la pandemia del coronavirus y preparándonos para las consecuencias en varios sectores de la economía. Podemos actuar tratando los síntomas, pero una vez que termine el estado de emergencia por la pandemia, ¿habremos construido algo que prevenga esta y otras pandemias?
Se viene una fuerte desaceleración económica, hay pronósticos que dicen que en latinoamérica el Producto Interno Bruto (PIB) caerá en 4.6% como consecuencia de los efectos del COVID-19 y cada país se verá afectado de diferente forma, la brecha de desigualdad se podría hacer más evidente[[30]](#ref_30).
A menudo desde el punto de vista de la economía, el consumo de productos es buena señal porque se refleja en movimiento económico. Pero por muchas razones descritas brevemente en este artículo, el modelo de consumo actual del mundo **no es sostenible** y tiene graves consecuencias.
Un camino es continuar como siempre y apuntar a mejorar la economía en base a un modelo de consumo que a propósito y sin pensar en las consecuencias, agrava las desigualdades entre "ricos" y "pobres". Algunos señalan que bajo el modelo económico actual y predominante, las ganancias de los mercados financieros occidentales no se traducen en inversiones productivas que creen más empleos, sino que se destinan a "bolsillos" personales de multimillonarios[[31]](#ref_31).
Un comportamiento económico que hace que a pesar de que se produzcan más alimentos que nunca antes, no se distribuyan para calmar el hambre de miles de millones de personas hambrientas y en cambio terminen alimentando la glotonería de una minoría de personas con un consumo desmedido y depredador. —Ese es el camino que hará que a la larga perdamos nuestra sensibilidad y riquezas naturales— el camino que basa su política económica como lo hacen gigantes de la economía como China en la premisa: "La vida natural es un recurso para ser usado" y la tendencia de ver a la naturaleza desde un punto de vista económico en lugar de un punto de vista ecológico[[33]](#ref_33). Ese es el rumbo de desarrollo económico que se ha estado siguiendo.
Hay otro camino que es **reconstruir mejor**, no hay modelo económico sostenible cuyos cimientos se basen en destruir el medio ambiente, muchas personas ya se han dado cuenta, naciones unidas entre otras instituciones internacionales recomiendan:
* Reducir los hábitos de producción y consumo de alimentos.
* Reducir los niveles de CO2 en la atmósfera.
* Incrementar la inversión en energías renovables.
* Incremento y mejora del transporte público limpio.
* Entrar en menos contacto con la vida silvestre, respetarla más.
Construir una economía diferente requiere un marco mundial de la diversidad biológica post-2020, para mantener la naturaleza rica, diversa y floreciente como indica una propuesta de naciones unidas que destaca — la salud de las personas y la salud del planeta son la misma cosa [[32]](#ref_32).
## Reflexiones adicionales y conclusiones
Esta pandemia del coronoavirus nos debe hacer notar y recordar que somos dependientes de la naturaleza que vive en el planeta, —somos producto de ella y pertenecemos a ella en lo más profundo, no al revés—. Seguir olvidando eso como civilización hará que a mediano o corto plazo suframos consecuencias mucho peores que la pandemia por el coronavirus.
Incluso si no tendríamos que sufrir las consecuencias, no es saludable que para alcanzar un grado de "bienestar" se lastimen especies animales, destruyan hábitats y ponga en peligro la rica biodiversidad de la que nos beneficiamos todos los días de nuestra vida.
La intención principal de este artículo es informar y concientizar sobre las consecuencias del daño a la naturaleza, y una prueba evidente es el coronavirus que es como una advertencia y pedido de auxilio al mismo tiempo.
Podemos escoger seguir improvisando y pensando equivocadamente que las cosas se arreglarán por si solas, dejando que las personas a quienes no les importa el bienestar de nadie mas que no sea el suyo propio, las que destruyen nuestra naturaleza, someten a poblaciones de animales llevándolas a la extinción y someten a poblaciones humanas, sean las que decidan el futuro de nuestro mundo.
O podemos escoger **tomar acción**, asumir la responsabilidad de cambiar nuestros viejos hábitos depredadores y consumistas en favor del equilibrio natural del que también estamos diseñados a ser parte. Aportar al cuidado y el conocer de nuestra madre tierra desde nuestras posibilidades y acciones.
Algunas acciones clave que podemos seguir:
* Reducir los hábitos de consumo de alimentos, en especial de origen animal.
* Ayudar a detener las redes de tráfico de animales silvestres.
* Apoyar y **exigir a nuestros gobiernos** políticas serias de protección al medioambiente.
* Informarse mas al respecto y concientizar a otras personas.
* **Participar** en acciones de protección al medio ambiente.
* Incentivar la investigación e inversión en tecnologías alternativas y respetuosas con el medioambiente.
* No encubrir actividades destructoras o que pongan en peligro la vida natural local.
Por esta pandemia, nuestro mundo esta cambiando y más que antes tenemos la oportunidad de aprovechar esta situación y reconstruirlo para bien.
<img width="512" alt="Zitting cisticola feeding its chicks" src="https://upload.wikimedia.org/wikipedia/commons/thumb/8/83/Zitting_cisticola_feeding_its_chicks.jpg/512px-Zitting_cisticola_feeding_its_chicks.jpg">
<span class="foto_nota">
Cistícola buitrón alimentando a sus polluelos. Foto de [Budi Santoso Adji](https://commons.wikimedia.org/wiki/File:Zitting_cisticola_feeding_its_chicks.jpg)
</span>
> “Lo único que necesita el mal para triunfar es que los hombres buenos no hagan nada”
>
> ― Edmund Burke
Tomando prestada una frase de los [Yes Men](https://es.wikipedia.org/wiki/The_Yes_Men) ... "Oh bueno, has llegado al final de la página. HAZ ALGO. »
## Referencias y enlaces de interés
<html>
<ol>
<li id="ref_1">
El origen del coronavirus SARS-CoV-2, a la luz de la evolución - [https://theconversation.com/el-origen-del-coronavirus-sars-cov-2-a-la-luz-de-la-evolucion-136897](https://theconversation.com/el-origen-del-coronavirus-sars-cov-2-a-la-luz-de-la-evolucion-136897).
</li>
<li id="ref_2">
Murciélagos y pangolines: el coronavirus es una zoonosis, no un producto de laboratorio - [https://theconversation.com/murcielagos-y-pangolines-el-coronavirus-es-una-zoonosis-no-un-producto-de-laboratorio-135753](https://theconversation.com/murcielagos-y-pangolines-el-coronavirus-es-una-zoonosis-no-un-producto-de-laboratorio-135753).
</li>
<li id="ref_3">
The proximal origin of SARS-CoV-2 - [https://www.nature.com/articles/s41591-020-0820-9](https://www.nature.com/articles/s41591-020-0820-9).
</li>
<li id="ref_4">
Coronavirus: Air pollution and CO2 fall rapidly as virus spreads - [https://www.bbc.com/news/science-environment-51944780](https://www.bbc.com/news/science-environment-51944780).
</li>
<li id="ref_5">
Temporary reduction in daily global CO2 emissions during the COVID-19 forced confinement - [https://www.nature.com/articles/s41558-020-0797-x](https://www.nature.com/articles/s41558-020-0797-x).
</li>
<li id="ref_6">
Nuevo agujero en la capa de ozono aparece en medio de la crisis del coronavirus - [https://www.tekcrispy.com/2020/03/31/nuevo-agujero-capa-ozono-aparece/](https://www.tekcrispy.com/2020/03/31/nuevo-agujero-capa-ozono-aparece/).
</li>
<li id="ref_7">
Miles de tortugas marinas en peligro de extinción anidan en las playas vacías durante la cuarentena por coronavirus - [https://www.20minutos.es/noticia/4218619/0/miles-de-tortugas-marinas-en-peligro-de-extincion-anidan-en-las-playas-vacias-durante-la-cuarentena-por-coronavirus/?autoref=true](https://www.20minutos.es/noticia/4218619/0/miles-de-tortugas-marinas-en-peligro-de-extincion-anidan-en-las-playas-vacias-durante-la-cuarentena-por-coronavirus/?autoref=true).
</li>
<li id="ref_8">
Deforestación: los 10 países que perdieron más bosque virgen en el mundo (y 5 están en América Latina) - [https://www.bbc.com/mundo/noticias-52915114](https://www.bbc.com/mundo/noticias-52915114).
</li>
<li id="ref_9">
Los ecosistemas de manglar frente al cambio climático global. ISSN: 1405-0471 -[https://www.redalyc.org/pdf/617/61740202.pdf](https://www.redalyc.org/pdf/617/61740202.pdf).
</li>
<li id="ref_10">
Perdimos el Equivalente a un Campo de Futbol de Selva Tropical Primaria Cada 6 Segundos en 2019 - [https://blog.globalforestwatch.org/es/data-and-research/datos-globales-de-perdida-de-cobertura-arborea-2019/](https://blog.globalforestwatch.org/es/data-and-research/datos-globales-de-perdida-de-cobertura-arborea-2019/).
</li>
<li id="ref_11">
Por qué la Tierra tiene hoy más bosques que en 1982 (y por qué esto no es necesariamente una buena noticia) - [https://www.bbc.com/mundo/noticias-45182681](https://www.bbc.com/mundo/noticias-45182681).
</li>
<li id="ref_12">
Bolivia perdió 290.000 hectáreas de bosques primarios en 2019 - [http://www.raibolivia.org/bolivia-perdio-290-000-hectareas-de-bosques-primarios-en-2019/](http://www.raibolivia.org/bolivia-perdio-290-000-hectareas-de-bosques-primarios-en-2019/).
</li>
<li id="ref_13">
Los desmontes sin cuarentena - [ http://revistaanfibia.com/cronica/los-desmontes-sin-cuarentena/](http://revistaanfibia.com/cronica/los-desmontes-sin-cuarentena/).
</li>
<li id="ref_14">
Más de 2 millones de animales mueren en incendios forestales en Bolivia - [https://noticiasdelatierra.com/mas-de-2-millones-de-animales-mueren-en-incendios-forestales-en-bolivia/](https://noticiasdelatierra.com/mas-de-2-millones-de-animales-mueren-en-incendios-forestales-en-bolivia/).
</li>
<li id="ref_15">
Diagnóstico por teledetección de áreas quemadas en la Chiquitania - [https://www.fcbc.org.bo/wp-content/uploads/2019/12/DiagnosticoIncendios.pdf](https://www.fcbc.org.bo/wp-content/uploads/2019/12/DiagnosticoIncendios.pdf)
</li>
<li id="ref_16">
El pangolín, el mamífero más traficado del mundo - [https://www.nationalgeographic.com.es/ciencia/actualidad/16-febrero-dia-mundial-pangolin_13890/2](https://www.nationalgeographic.com.es/ciencia/actualidad/16-febrero-dia-mundial-pangolin_13890/2)
</li>
<li id="ref_17">
Para evitar más pandemias se necesita controlar el tráfico ilegal de fauna y flora silvestre - [https://news.un.org/es/story/2020/07/1477241](https://news.un.org/es/story/2020/07/1477241)
</li>
<li id="ref_18">
Industrial agriculture - [https://www.newworldencyclopedia.org/entry/Industrial_agriculture](https://www.newworldencyclopedia.org/entry/Industrial_agriculture)
</li>
<li id="ref_19">
La Chiquitanía vuelve a arder ¿Y el estruendo? - [https://desacatosenlared.wordpress.com/2020/06/10/la-chiquitania-vuelve-a-arder-y-el-estruendo/](https://desacatosenlared.wordpress.com/2020/06/10/la-chiquitania-vuelve-a-arder-y-el-estruendo/)
</li>
<li id="ref_20">
Atlas del agronegocio transgénico en el cono sur - [http://www.ftierra.org/index.php/component/attachments/download/218](http://www.ftierra.org/index.php/component/attachments/download/218)
</li>
<li id="ref_21">
Altas de la Carne, Fundación Henrich Böll Stiftung - [https://mx.boell.org/sites/default/files/atlasdelacarne2014_web_140717.pdf](https://mx.boell.org/sites/default/files/atlasdelacarne2014_web_140717.pdf)
</li>
<li id="ref_22">
Tráfico de animales. Del lavado de dinero al coronavirus, la trama del negocio ilegal millonario. [https://www.lanacion.com.ar/lifestyle/trafico-animales-del-lavado-dinero-al-coronavirus-nid2397240](https://www.lanacion.com.ar/lifestyle/trafico-animales-del-lavado-dinero-al-coronavirus-nid2397240)
</li>
<li id="ref_23">
Tráfico de animales amenaza la salud humana: ONU - [https://www.proceso.com.mx/637772/coronavirus-en-el-mundo-trafico-de-animales-amenaza-la-salud-humana-onu](https://www.proceso.com.mx/637772/coronavirus-en-el-mundo-trafico-de-animales-amenaza-la-salud-humana-onu)
</li>
<li id="ref_24">
Benefits from biodiversity - [https://natureecoevocommunity.nature.com/users/346027-joseph-aslin/posts/benefits-from-biodiversity](https://natureecoevocommunity.nature.com/users/346027-joseph-aslin/posts/benefits-from-biodiversity)
</li>
<li id="ref_25">
Dossier- "El papel de la biodiversidad" - [https://www.fuhem.es/media/cdv/file/biblioteca/Dossier/Dossier_El_papel_de_la_biodiversidad.pdf](https://www.fuhem.es/media/cdv/file/biblioteca/Dossier/Dossier_El_papel_de_la_biodiversidad.pdf)
</li>
<li id="ref_26">
Nature’s Dangerous Decline ‘Unprecedented’ Species Extinction Rates ‘Accelerating’: Intergovernmental Science-Policy Platform on Biodiversity and Ecosystem Services (IPBES) - [https://ipbes.net/news/Media-Release-Global-Assessment](https://ipbes.net/news/Media-Release-Global-Assessment)
</li>
<li id="ref_27">
Seis datos sobre la conexión entre la naturaleza y el coronavirus - [https://www.unenvironment.org/es/noticias-y-reportajes/reportajes/seis-datos-sobre-la-conexion-entre-la-naturaleza-y-el-coronavirus](https://www.unenvironment.org/es/noticias-y-reportajes/reportajes/seis-datos-sobre-la-conexion-entre-la-naturaleza-y-el-coronavirus)
</li>
<li id="ref_28">
El mundo está tratando los síntomas de la pandemia de covid-19, pero no las causas - [https://www.bbc.com/mundo/noticias-53435056](https://www.bbc.com/mundo/noticias-53435056)
</li>
<li id="ref_29">
"The importance of long-distance dispersal in biodiversity conservation" - [https://onlinelibrary.wiley.com/doi/epdf/10.1111/j.1366-9516.2005.00156.x](https://onlinelibrary.wiley.com/doi/epdf/10.1111/j.1366-9516.2005.00156.x)
</li>
<li id="ref_30">
"Coronavirus en Latinoamérica: economía post-pandemia" - [https://h2gconsulting.com/how2go-latinoamerica/coronavirus-en-latinoamerica-economia-post-pandemia/](https://h2gconsulting.com/how2go-latinoamerica/coronavirus-en-latinoamerica-economia-post-pandemia/)
</li>
<li id="ref_31">
"¿SE VIENE UN NUEVO MODELO ECONÓMICO GLOBAL POST-PANDEMIA? Ernesto Cazal." - [https://observatoriodetrabajadores.wordpress.com/2020/04/30/se-viene-un-nuevo-modelo-economico-global-post-pandemia-ernesto-cazal/](https://observatoriodetrabajadores.wordpress.com/2020/04/30/se-viene-un-nuevo-modelo-economico-global-post-pandemia-ernesto-cazal/)
</li>
<li id="ref_32">
La pandemia de coronavirus es una oportunidad para construir una economía que preserve la salud del planeta - [https://news.un.org/es/story/2020/04/1472482](https://news.un.org/es/story/2020/04/1472482)
</li>
<li id="ref_33">
To Prevent Next Coronavirus, Stop the Wildlife Trade, Conservationists Say - [https://www.nytimes.com/2020/02/19/health/coronavirus-animals-markets.html](https://www.nytimes.com/2020/02/19/health/coronavirus-animals-markets.html)
</li>
</ol>
</html>
base.html
<!DOCTYPE html>
<!--
Monomotapa - A Micro CMS
Copyright (C) 2014, Paul Munday.
PO Box 28228, Portland, OR, USA 97228
paul at paulmunday.net
This program is free software: you can redistribute it and/or modify
it under the terms of the GNU Affero Public License as published by
the Free Software Foundation, either version 3 of the License, or
(at your option) any later version.
This program is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU General Public License for more details.
You should have received a copy of the GNU Affero General Public License
along with this program. If not, see <http://www.gnu.org/licenses/>.
There should also be a copy of the AGPL in src/license.md that should be
accessible by going to <a href ="/license">/license<a> on this site.
-->
<html>
<head>
<title>{% if title -%}{{title}}{% endif %}</title>
<meta name="viewport" content="width=device-width, initial-scale=1">
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<meta name="lang" content="es"/>
<meta name="author" content="Rodrigo Garcia Saenz"/>
<meta property="article:publisher" content="https://rmgss.net"/>
<meta property="og:site_name" content="Sitio personal de Rodrigo Garcia Saenz"/>
<!-- meta datos dinamicos -->
{%- for metadato in meta -%}
<meta {{metadato.tag}}="{{metadato.name}}" content="{{metadato.content}}"/>
{%- endfor -%}
<!-- -->
<link rel="stylesheet" type="text/css" title="oscuro" href="/static/style_rmgss.css">
<link rel="alternate stylesheet" type="text/css" title="claro" href="/static/style_rmgss_claro.css">
<!-- {%- if css -%} -->
<!-- {%- for file in css %} -->
<!-- <link href="{{ url_for('static', filename=file) }}" rel="stylesheet" type="text/css" /> -->
<!-- {%- endfor -%} -->
<!-- {%- endif %} -->
{% if internal_css %}
<style type="text/css">
{{internal_css}}
</style>
{% endif %}
{%- if hlinks -%}
{%- for item in hlinks -%}
<link
{%- if item.href %} href="{{item.href}}"{% endif -%}
{%- if item.rel %} rel="{{item.rel}}"{% endif -%}
{%- if item.type %} type="{{item.type}}"{% endif -%}
{%- if item.media %} type="{{item.media}}"{% endif -%}
{%- if item.hreflang %} type="{{item.hreflang}}"{% endif -%}
{%- if item.charset %} type="{{item.charset}}"{% endif -%}
>
{% endfor %}
{%- endif -%}
<link rel="apple-touch-icon" sizes="76x76" href="{{ url_for('static', filename='imgs/favicon/apple-touch-icon.png')}}">
<link rel="icon" type="image/png" sizes="32x32" href="{{ url_for('static', filename='imgs/favicon/favicon-32x32.png')}}">
<link rel="icon" type="image/png" sizes="16x16" href="{{ url_for('static', filename='imgs/favicon/favicon-16x16.png')}}">
<link rel="manifest" href="{{ url_for('static', filename='imgs/favicon/site.webmanifest')}}">
<link rel="mask-icon" href="{{ url_for('static', filename='imgs/favicon/safari-pinned-tab.svg')}}" color="#5bbad5">
<meta name="msapplication-TileColor" content="#da532c">
<meta name="theme-color" content="#ffffff">
{# <link rel="shortcut icon" type="image/png" href="/{{ url_for('static', filename='imgs/favicon.png') }}> #}
</head>
<body onload="loadCssStyle()">
<div id="wrap">
<div>
<p>
<a href="/">
<img src="/static/imgs/cabecera1.png">
</a>
<br>
<span style="font-size:12px;">
<q><b>sitio personal</b> de Rodrigo Garcia Saenz.</q>
</span>
</p>
</div>
<div class="row">
<!-- <div class="col fifth"> -->
<!-- Importante dejar este -->
<!-- </div> -->
<div class="col fifth">
<!-- Tabla de contenidos del post -->
{%- if not exclude_toc -%}
<div id="side_toc">
<h3>Índice del post</h3>
{{ toc|safe }}
</div>
{%- endif -%}
<div id="nav_left">
<ul>
<dd>
<a href="/">
<img class="leftbaricon"
src="/static/imgs/inicio.svg" alt="Inicio / Start" title="Inicio 🏡">
</a>
</dd>
<dd>
<a href="/posts">
<img class="leftbaricon" src="/static/imgs/misc.svg" alt="Posts" title="Posts">
Posts
</a>
<ul>
<dd>
<a href="/posts/categorias">
<img
class="leftbaricon"
src="/static/imgs/categorias.svg" alt="Categorías" title="Categorías">
Categorías
</a>
</dd>
</ul>
</dd>
<dd>
<a href="/posts/categoria/fotos">
<img
class="leftbaricon"
src="/static/imgs/fotos.svg" alt="fotos" title="fotos 🖼">
Fotos
</a>
<dd>
<a href="/acerca_de_mi">
<img src="/static/imgs/acercade.svg" alt="acerca de mi" title="Acerca de mi">
Acerca de mi
</a>
</dd>
<dd>
<a href="/contacto">
<img
class="leftbaricon"
src="/static/imgs/contacto.svg" alt="contacto" title="Contacto 📨">
Contacto
</a>
</dd>
</ul>
<ul>
<hr>
{%- for item in navigation.navigation.values() -%}
<li><a href="
{%- if item.url -%}{{item.url}}
{%- elif item.urlfor -%}
{%- if item.urlfor == "source" -%}
{{ url_for(item.urlfor, page=navigation.page) }}
{%- else -%}
{{ url_for(item.urlfor) }}
{%- endif -%}
{%- else -%}
{{ url_for('staticpage', page=item.base) }}
{%- endif -%}
{%- if item.rel -%}
" rel="{{item.rel}}
{%- endif -%}
">{{item.link_text}}</a></li>
{% endfor -%}
</ul>
<p>
<a href="/rss" >
<img src="/static/imgs/rss.png" width="24" heigth="24">
RSS
</a>
</p>
</div>
<!-- consejo del dia -->
<div id="consejo_del_dia">
<b>Consejo del día</b>
<hr>
{% if contexto %}
{{ contexto['consejo']|safe }}
{% endif %}
</div>
<!-- Noticias Realcionadas si es un post -->
<div id="noticias_relacionadas">
{% if contexto is defined %}
{% if contexto['relacionadas'] is defined %}
<h3>Posts/Noticias relacionadas</h3>
{% for post_relacionado in contexto['relacionadas'] %}
<p>
<a href="/posts/{{ post_relacionado }}">
{{ post_relacionado|n_heading }}
</a>
</p>
<hr>
{% endfor %}
{% endif %}
{% endif %}
</div>
</div>
<!-- Contenido -->
<div class="col fill">
<!-- Cabecera -->
<div style="margin-bottom: 7px">
<form>
<input type="submit" onclick="cambiarEstilo('oscuro'); return false;" name="theme" value="☻" id="oscuro" style="background-color: #333933; color: #C3C4C2; border-radius:3px;">
<input type="submit" onclick="cambiarEstilo('claro'); return false;" name="theme" value="☺" id="claro" style="background-color: #D1E9D3; color: #131914; border-radius:3px;">
</form>
</div>
<!-- Contenido -->
{% block content %}{% endblock %}
<!-- nav bottom (para pantallas chicas) -->
<div id="nav_bottom">
<ul>
<dd>
<a href="/">
<img src="/static/imgs/inicio.svg"
class="leftbaricon"
title="Inicio 🏡"
alt="Inicio">
</a>
</dd>
<dd>
<a href="/posts">
<img
class="leftbaricon"
title="Posts"
src="/static/imgs/misc.svg" alt="posts">
Posts
</a>
<ul>
<dd>
<a href="/posts/categorias">
<img
class="leftbaricon"
title="Categorías"
src="/static/imgs/categorias.svg" alt="categorías">
categorías
</a>
</dd>
</ul>
</dd>
<dd>
<a href="/posts/categoria/fotos">
<img
class="leftbaricon"
title="Fotos 🖼"
src="/static/imgs/fotos.svg" alt="fotos">
fotos
</a>
</dd>
<dd>
<a href="/acerca_de_mi">
<img
class="leftbaricon"
title="Acerca de mi"
src="/static/imgs/acercade.svg" alt="Acerca de mi">
acerca de
</a>
</dd>
</ul>
<dd>
<a href="/contacto">
<img
class="leftbaricon"
title="Contacto 📨"
src="/static/imgs/contacto.svg" alt="Contacto">
contacto
</a>
</dd>
</ul>
<ul>
<hr>
{%- for item in navigation.navigation.values() -%}
<li><a href="
{%- if item.url -%}{{item.url}}
{%- elif item.urlfor -%}
{%- if item.urlfor == "source" -%}
{{ url_for(item.urlfor, page=navigation.page) }}
{%- else -%}
{{ url_for(item.urlfor) }}
{%- endif -%}
{%- else -%}
{{ url_for('staticpage', page=item.base) }}
{%- endif -%}
{%- if item.rel -%}
" rel="{{item.rel}}
{%- endif -%}
">{{item.link_text}}</a></li>
{% endfor -%}
</ul>
<p>
<a href="/rss" >
<img src="/static/imgs/rss.png" width="24" heigth="24">
RSS
</a>
</p>
</div>
<!-- Noticias Realcionadas si es un post -->
<div id="noticias_relacionadas_bottom">
{% if contexto is defined %}
{% if contexto['relacionadas'] is defined %}
<h3>Posts/Noticias relacionadas</h3>
{% for post_relacionado in contexto['relacionadas'] %}
<p>
<a href="/posts/{{ post_relacionado }}">
{{ post_relacionado|n_heading }}
</a>
</p>
<hr>
{% endfor %}
{% endif %}
{% endif %}
</div>
<!-- consejo del dia -->
<div id="consejo_del_dia_bottom">
<b>Consejo del día</b>
<hr>
{% if contexto %}
{{ contexto['consejo']|safe }}
{% endif %}
</div>
</div>
</div> <!-- row -->
</div>
<div id="footer">
<p id="footer">
Este sitio web es software libre aquí el <a href="https://notabug.org/strysg/monimatapa">código fuente</a>.<br>
El contenido de este sitio esta bajo una licencia Creative Commons <a href="https://creativecommons.org/licenses/by/4.0/">Attribution 4.0 International (CC BY 4.0)</a> a menos que se indique lo contrario.
<!-- footer goes here -->
{% if footer %}
{{footer}}
{% endif %}
</p>
</div>
<!-- javascript -->
<script language="javascript">
function loadCssStyle() {
const _varStyleName = 'style_css';
var lsStyle = window.localStorage.getItem(_varStyleName);
if (!lsStyle) {
// default
window.localStorage.setItem('style_css', 'oscuro');
lsStyle = window.localStorage.getItem(_varStyleName);
}
var i, link_tag = document.getElementsByTagName("link");
// inspeccionando hojas de estilo css cargadas
for (
i = 0,
link_tag = document.getElementsByTagName("link") ; i < link_tag.length ;
i++ ) {
if ((link_tag[i].rel.indexOf( "stylesheet" ) != -1)) {
link_tag[i].disabled = true;
if (link_tag[i].title === lsStyle) {
link_tag[i].disabled = false ;
console.log('enabling', link_tag[i].title);
}
}
}
}
function cambiarEstilo(value) {
window.localStorage.setItem('style_css', value);
loadCssStyle();
}
</script>
<!-- --->
</body>
</html>
post.html
{% extends "base.html" %}
{% block content %}
<article class="h-entry">
<div>
{% if heading %}<h1 class="p-name">{{heading}}</h1>{% endif %}
</div>
{# <hr> #}
{# {{ meta }} #}
{# <hr> #}
{% if attributes %}
<div id="attributes">
<p id="post-details">
{% if attributes['date'] %}
<time class="dt-published" datetime="{{attributes['date']}}">
{% if attributes['date-text'] %}
{{attributes['date-text']}}
{% else %}
{{attributes['date']}}
{% endif %}
</time>
{% endif %}
{% if attributes['author'] %}
<span class="p-author">{{attributes['author']}}</span>
{% endif %}
<a class="u-url" href="/{{name}}">permalink.</a>
</p>
{% if attributes['summary'] %}
<p class="p-summary">{{attributes['summary']}}</p>
{% endif %}
</div>
{% endif %}
<div class='e-content'>
<div align="right">
{% if contexto['ultima_modificacion'] %}
<small>Actualizado - {{ contexto['ultima_modificacion'] }}</small>
{% endif %}
</div>
{% if categorias %}
<div class="categorias">
{% for cat in categorias %}
<a href="/posts/categoria/{{ cat }}">#{{ cat }}</a>
{% endfor %}
</div>
{% endif %}
{{contents}}
</div>
</article>
{% endblock %}


 Posts
Posts
 Categorías
Categorías
 Fotos
Fotos
 Acerca de mi
Acerca de mi
 Contacto
Contacto