# -*- coding: utf-8 -*-
"""
Monomotapa - A Micro CMS
Copyright (C) 2014, Paul Munday.
PO Box 28228, Portland, OR, USA 97228
paul at paulmunday.net
Modificado por: Rodrigo Garcia 2017 https://rmgss.net/contacto
This program is free software: you can redistribute it and/or modify
it under the terms of the GNU Affero Public License as published by
the Free Software Foundation, either version 3 of the License, or
(at your option) any later version.
This program is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU General Public License for more details.
You should have received a copy of the GNU Affero General Public License
along with this program. If not, see <http://www.gnu.org/licenses/>.
Monomotapa:
a city whose inhabitants are bounded by deep feelings of friendship,
so that they intuit one another's most secret needs and desire.
For instance, if one dreams that his friend is sad, the friend will
perceive the distress and rush to the sleepers rescue.
(Jean de La Fontaine, *Fables choisies, mises en vers*, VIII:11 Paris,
2nd ed., 1678-9)
cited in :
Alberto Manguel and Gianni Guadalupi, *The Dictionary of Imaginary Places*,
Bloomsbury, London, 1999.
A micro cms written using the Flask microframework, orignally to manage my
personal site. It is designed so that publishing a page requires no more than
dropping a markdown page in the appropriate directory (though you need to edit
a json file if you want it to appear in the top navigation).
It can also display its own source code and run its own unit tests.
The name 'monomotapa' was chosen more or less at random (it shares an initial
with me) as I didn't want to name it after the site and be typing import
paulmunday, or something similar, as that would be strange.
"""
from flask import render_template, abort, Markup, escape, request #, make_response
from flask import redirect
from werkzeug.utils import secure_filename
from pygments import highlight
from pygments.lexers import PythonLexer, HtmlDjangoLexer, TextLexer
from pygments.formatters import HtmlFormatter
import markdown
from time import gmtime, strptime, strftime, ctime, mktime
import datetime
import os.path
import os
import subprocess
import json
import traceback
from collections import OrderedDict
from simplemotds import SimpleMotd
from monomotapa import app
from monomotapa.config import ConfigError
from monomotapa.utils import captcha_comprobar_respuesta, captcha_pregunta_opciones_random
from monomotapa.utils import categorias_de_post, categoriasDePost, categoriasList, cabezaPost
from monomotapa.utils import titulo_legible, metaTagsAutomaticos
from markdown.extensions.toc import TocExtension
json_pattrs = {}
with open(os.path.join('monomotapa','pages.json'), 'r') as pagefile:
json_pattrs = json.load(pagefile)
simplemotd = SimpleMotd("config_simplemotds.json")
class MonomotapaError(Exception):
"""create classs for own errors"""
pass
def get_page_attributes(jsonfile):
"""Returns dictionary of page_attributes.
Defines additional static page attributes loaded from json file.
N.B. static pages do not need to have attributes defined there,
it is sufficient to have a page.md in src for each /page
possible values are src (name of markdown file to be rendered)
heading, title, and trusted (i.e. allow embeded html in markdown)"""
try:
with open(src_file(jsonfile), 'r') as pagesfile:
page_attributes = json.load(pagesfile)
except IOError:
page_attributes = []
return page_attributes
def get_page_attribute(attr_src, page, attribute):
"""returns attribute of page if it exists, else None.
attr_src = dictionary(from get_page_attributes)"""
if page in attr_src and attribute in attr_src[page]:
return attr_src[page][attribute]
else:
return None
# Navigation
def top_navigation(page):
"""Generates navigation as an OrderedDict from navigation.json.
Navigation.json consists of a json array(list) "nav_order"
containing the names of the top navigation elements and
a json object(dict) called "nav_elements"
if a page is to show up in the top navigation
there must be an entry present in nav_order but there need not
be one in nav_elements. However if there is the key must be the same.
Possible values for nav_elements are link_text, url and urlfor
The name from nav_order will be used to set the link text,
unless link_text is present in nav_elements.
url and urlfor are optional, however if ommited the url wil be
generated in the navigation by url_for('staticpage', page=[key])
equivalent to @app.route"/page"; def page())
which may not be correct. If a url is supplied it will be used
otherwise if urlfor is supplied it the url will be
generated with url_for(urlfor). url takes precendence so it makes
no sense to supply both.
Web Sign-in is supported by adding a "rel": "me" attribute.
"""
with open(src_file('navigation.json'), 'r') as navfile:
navigation = json.load(navfile)
base_nav = OrderedDict({})
for key in navigation["nav_order"]:
nav = {}
nav['base'] = key
nav['link_text'] = key
if key in navigation["nav_elements"]:
elements = navigation["nav_elements"][key]
nav.update(elements)
base_nav[key] = nav
return {'navigation' : base_nav, 'page' : page}
# For pages
class Page:
"""Generates pages as objects"""
def __init__(self, page, **kwargs):
"""Define attributes for pages (if present).
Sets self.name, self.title, self.heading, self.trusted etc
This is done through indirection so we can update the defaults
(defined in the 'attributes' dictionary) with values from config.json
or pages.json easily without lots of if else statements.
If css is supplied it will overide any default css. To add additional
style sheets on a per page basis specifiy them in pages.json.
The same also applies with hlinks.
css is used to set locally hosted stylesheets only. To specify
external stylesheets use hlinks: in config.json for
default values that will apply on all pages unless overidden, set here
to override the default. Set in pages.json to add after default.
"""
# set default attributes
self.page = page.rstrip('/')
self.defaults = get_page_attributes('defaults.json')
self.pages = get_page_attributes('pages.json')
self.url_base = self.defaults['url_base']
title = titulo_legible(page.lower())
heading = titulo_legible(page.capitalize())
self.categorias = categoriasDePost(self.page)
self.exclude_toc = True
try:
self.default_template = self.defaults['template']
except KeyError:
raise ConfigError('template not found in default.json')
# will become self.name, self.title, self.heading,
# self.footer, self.internal_css, self.trusted
attributes = {'name' : self.page, 'title' : title,
'navigation' : top_navigation(self.page),
'heading' : heading, 'footer' : None,
'css' : None , 'hlinks' :None, 'internal_css' : None,
'trusted': False,
'preview-chars': 250,
}
# contexto extra TODO: revisar otra forma de incluir un contexto
self.contexto = {}
self.contexto['consejo'] = simplemotd.getMotdContent()
# set from defaults
attributes.update(self.defaults)
# override with kwargs
attributes.update(kwargs)
# override attributes if set in pages.json
if page in self.pages:
attributes.update(self.pages[page])
# set attributes (as self.name etc) using indirection
for attribute, value in attributes.items():
# print('attribute', attribute, '=-==>', value)
setattr(self, attribute, value)
# meta tags
try:
self.pages[self.page]['title'] = attributes['title']
self.pages[self.page]['url_base'] = self.url_base
metaTags = metaTagsAutomaticos(self.page, self.pages.get(self.page, {}))
self.meta = metaTags
# for key, value in self.pages[self.page].items():
# print(' ', key, ' = ', value)
except Exception as e:
tb = traceback.format_exc()
print('Error assigning meta:', str(e), '\n', str(tb))
# reset these as we want to append rather than overwrite if supplied
if 'css' in kwargs:
self.css = kwargs['css']
elif 'css' in self.defaults:
self.css = self.defaults['css']
if 'hlinks' in kwargs:
self.hlinks = kwargs['hlinks']
elif 'hlinks' in self.defaults:
self.hlinks = self.defaults['hlinks']
# append hlinks and css from pages.json rather than overwriting
# if css or hlinks are not supplied they are set to default
if page in self.pages:
if 'css' in self.pages[page]:
self.css = self.css + self.pages[page]['css']
if 'hlinks' in self.pages[page]:
self.hlinks = self.hlinks + self.pages[page]['hlinks']
# append heading to default if set in config
self.title = self.title + app.config.get('default_title', '')
def _get_markdown(self):
"""returns rendered markdown or 404 if source does not exist"""
src = self.get_page_src(self.page, 'src', 'md')
if src is None:
abort(404)
else:
return render_markdown(src, self.trusted)
def get_page_src(self, page, directory=None, ext=None):
""""return path of file (used to generate page) if it exists,
or return none.
Also returns the template used to render that page, defaults
to static.html.
It will optionally add an extension, to allow
specifiying pages by route."""
# is it stored in a config
pagename = get_page_attribute(self.pages, page, 'src')
if not pagename:
pagename = page + get_extension(ext)
if os.path.exists(src_file(pagename , directory)):
return src_file(pagename, directory)
else:
return None
def get_template(self, page):
"""returns the template for the page"""
pagetemplate = get_page_attribute(self.pages, page, 'template')
if not pagetemplate:
pagetemplate = self.default_template
if os.path.exists(src_file(pagetemplate , 'templates')):
return pagetemplate
else:
raise MonomotapaError("Template: %s not found" % pagetemplate)
def generate_page(self, contents=None):
"""return a page generator function.
For static pages written in Markdown under src/.
contents are automatically rendered.
N.B. See note above in about headers"""
toc = '' # table of contents
if not contents:
contents, toc = self._get_markdown()
# print('////', toc)
template = self.get_template(self.page)
# print('......................')
# def mos(**kwargs):
# for k in kwargs:
# print(k, end=',')
# mos(**vars(self))
return render_template(template,
contents = Markup(contents),
toc=toc,
**vars(self))
# helper functions
def src_file(name, directory=None):
"""return potential path to file in this app"""
if not directory:
return os.path.join( 'monomotapa', name)
else:
return os.path.join('monomotapa', directory, name)
def get_extension(ext):
'''constructs extension, adding or stripping leading . as needed.
Return null string for None'''
if ext is None:
return ''
elif ext[0] == '.':
return ext
else:
return '.%s' % ext
def render_markdown(srcfile, trusted=False):
""" Returns markdown file rendered as html and the table of contents as html.
Defaults to untrusted:
html characters (and character entities) are escaped
so will not be rendered. This departs from markdown spec
which allows embedded html."""
try:
with open(srcfile, 'r') as f:
src = f.read()
md = markdown.Markdown(extensions=['toc', 'codehilite'])
md.convert(src)
toc = md.toc
if trusted == True:
content = markdown.markdown(src,
extensions=['codehilite',
TocExtension(permalink=True)])
else:
content = markdown.markdown(escape(src),
extensions=['codehilite',
TocExtension(permalink=True)])
return content, toc
except IOError:
return None
def render_pygments(srcfile, lexer_type):
"""returns src(file) marked up with pygments"""
if lexer_type == 'python':
with open(srcfile, 'r') as f:
src = f.read()
contents = highlight(src, PythonLexer(), HtmlFormatter())
elif lexer_type == 'html':
with open(srcfile, 'r') as f:
src = f.read()
contents = highlight(src, HtmlDjangoLexer(), HtmlFormatter())
# default to TextLexer for everything else
else:
with open(srcfile, 'r') as f:
src = f.read()
contents = highlight(src, TextLexer(), HtmlFormatter())
return contents
def get_pygments_css(style=None):
"""returns css for pygments, use as internal_css"""
if style is None:
style = 'friendly'
return HtmlFormatter(style=style).get_style_defs('.highlight')
def heading(text, level):
"""return as html heading at h[level]"""
heading_level = 'h%s' % str(level)
return '\n<%s>%s</%s>\n' % (heading_level, text, heading_level)
def posts_list(ordenar_por_fecha=True, ordenar_por_nombre=False):
'''Retorna una lista con los nombres de archivos con extension .md
dentro de la cappeta src/posts, por defecto retorna una lista con
la tupla (nombre_archivo, fecha_subida)'''
lista_posts = []
lp = []
if ordenar_por_nombre:
try:
ow = os.walk("monomotapa/src/posts")
p , directorios , archs = ow.__next__()
except OSError:
print ("[posts] - Error: Cant' os.walk() on monomotapa/src/posts except OSError")
else:
for arch in archs:
if arch.endswith(".md") and not arch.startswith("#") \
and not arch.startswith("~") and not arch.startswith("."):
lista_posts.append(arch)
lista_posts.sort()
return lista_posts
if ordenar_por_fecha:
try:
ow = os.walk("monomotapa/src/posts")
p,d,files=ow.__next__()
except OSError:
print ("[posts] - Error: Can't os.walk() on monomotapa/src/posts except OSError.")
else:
for f in files:
nombre_con_ruta = os.path.join("monomotapa/src/posts", f)
if not f.endswith("~") and not f.startswith("#") and not f.startswith("."):
secs_modificacion = SecsModificacionPostDesdeJson(f, json_pattrs)
ultima_modificacion = os.path.getmtime(nombre_con_ruta)
lp.append((secs_modificacion, ultima_modificacion, f))
lp.sort()
lp.reverse()
# colocando fecha en formato
for tupla in lp:
#fecha = strftime("a, %d %b %Y %H:%M:%S", ctime(tupla[0]))
cfecha = ctime(tupla[1])
#fecha = strptime("%a %b %d %H:%M:%S %Y", cfecha)
lista_posts.append((cfecha, tupla[2]))
return lista_posts
def categorias_list(categoria=None):
""" Rotorna una lista con los nombres de posts y el numero de posts que
pertenecen a la categoria dada o a cada categoria.
Las categorias se obtienen analizando la primera linea de cada archivo .md
an la carpeta donde se almacenan los posts.
Si no se especifica `categoria' cada elemento de la lista devuelta es:
(nombre_categoria, numero_posts, [nombres_posts])
si se especifica `categoria' cada elemento de la lista devuelta es:
(numero_posts, [nombres_posts]
"""
lista_posts = posts_list(ordenar_por_nombre=True)
lista_categorias = []
if categoria is not None:
c = 0
posts = []
for post in lista_posts:
nombre_arch = "monomotapa/src/posts/"+post
with open(nombre_arch, 'r') as file:
linea = file.readline().decode("utf-8")
lc = linea.split("[#")[1:]
for cad in lc:
cat = cad.split("]")[0]
if cat == categoria:
c += 1
posts.append(post)
lista_categorias = (c, posts)
return lista_categorias
dic_categorias = {}
for post in lista_posts:
nombre_arch = "monomotapa/src/posts/"+post
with open(nombre_arch, 'r') as fil:
linea = fil.readline().decode('utf-8') # primera linea
# extrayendo las categorias y registrando sus ocurrencias
# ejemplo: catgorías: [#reflexión](categoria/reflexion) [#navidad](categoria/navidad)
# extrae: [reflexion,navidad]
lc = linea.split("[#")[1:]
for cad in lc:
cat = cad.split("]")[0]
if cat not in dic_categorias:
dic_categorias[cat] = (1,[post]) # nuevo registro por categoria
else:
tupla = dic_categorias[cat]
c = tupla[0] + 1
lis = tupla[1]
if post not in lis:
lis.append(post)
dic_categorias[cat] = (c, lis)
# convirtiendo en lista
for k, v in dic_categorias.iteritems():
lista_categorias.append((k,v[0],v[1]))
lista_categorias.sort()
lista_categorias.reverse()
return lista_categorias
def cabeza_post(archivo , max_caracteres=250, categorias=True):
""" Devuelve las primeras lineas de una archivo de post (en formato markdown)
con un maximo numero de caracteres excluyendo titulos en la cabeza devuelta.
Si se especifica `categorias' en True
Se devuelve una lista de la forma:
(cabeza_post, categorias)
donde categorias son cadenas con los nombres de las categorias a la que
pertenece el post
"""
cabeza_post = ""
cats = []
with open(os.path.join("monomotapa/src/posts",archivo)) as file:
# analizando si hay titulos al principio
# Se su pone que la primera linea es de categorias
for linea in file.readlines():
linea = linea.decode("utf-8")
if linea.startswith(u"categorías:") or linea.startswith("categorias"):
if categorias:
cats = categoriasDePost(archivo)
#cats = categorias_de_post(archivo)
else:
# evitando h1, h2
if linea.startswith("##") or linea.startswith("#"):
cabeza_post += " "
else:
cabeza_post += linea
if len(cabeza_post) >= max_caracteres:
break
cabeza_post = cabeza_post[0:max_caracteres-1]
if categorias:
return (cabeza_post, cats)
return cabeza_post
def ultima_modificacion_archivo(archivo):
""" Retorna una cadena indicando la fecha de ultima modificacion del
`archivo' dado, se asume que `archivo' esta dentro la carpeta "monomotapa/src"
Retorna una cadena vacia en caso de no poder abrir `archivo'
"""
try:
ts = strptime(ctime(os.path.getmtime("monomotapa/src/"+archivo+".md")))
return strftime("%d %B %Y", ts)
except OSError:
return ""
def SecsModificacionPostDesdeJson(archivo, dict_json):
''' dado el post con nombre 'archivo' busca en 'dict_json' el
attribute 'date' y luego obtiene los segundos totales desde
esa fecha.
Si no encuentra 'date' para 'archivo' en 'dict.json'
retorna los segundos totales desde la ultima modificacion
del archivo de post directamente (usa os.path.getmtime)
'''
nombre = archivo.split('.md')[0] # no contar extension .md
nombre_con_ruta = os.path.join("monomotapa/src/posts", archivo)
date_str = dict_json.get('posts/'+nombre, {}).\
get('attributes',{}).\
get('date','')
if date_str == '':
# el post no tiene "date" en pages.json
return os.path.getmtime(nombre_con_ruta)
else:
time_struct = strptime(date_str, '%Y-%m-%d')
dt = datetime.datetime.fromtimestamp(mktime(time_struct))
return (dt - datetime.datetime(1970,1,1)).total_seconds()
def noticias_recientes(cantidad=11, max_caracteres=250,
categoria=None, pagina=0):
'''Devuelve una lista con hasta `cantidad' de posts mas recientes,
un maximo de `max_caracteres' de caracteres del principio del post y
el numero total de posts encontrados
Si se proporciona `categoria' devuelve la lista de posts solamente
pertenecientes esa categoria.
Si `pagina' > 0 se devulve hasta `cantidad' numero de posts en el
rango de [ cantidad*pagina : cantidad*(pagina+1)]
Cada elemento de la lista devuelta contiene:
(nombre_post, ultima_modificacion, cabeza_archivo, categorias)
Al final se retorna: (lista_posts, numero_de_posts)
'''
lista_posts = []
lp = []
num_posts = 0
posts_en_categoria = []
if categoria is not None:
#posts_en_categoria = categorias_list(categoria)[1]
posts_en_categoria = categoriasList(categoria)[1]
# categoria especial fotos
if categoria == "fotos":
l = []
for p in posts_en_categoria:
l.append(p + '.md')
posts_en_categoria = l
try:
ow = os.walk("monomotapa/src/posts")
p,d,files = ow.__next__()
#p,d,files=ow.next()
except OSError:
print ("[posts] - Error: Can't os.walk() on monomotapa/src/posts except OSError.")
else:
for f in files:
nombre_con_ruta = os.path.join("monomotapa/src/posts", f)
if not f.endswith("~") and not f.startswith("#") and not f.startswith("."):
secs_modificacion = SecsModificacionPostDesdeJson(f, json_pattrs)
ultima_modificacion = os.path.getmtime(nombre_con_ruta)
previewChars = json_pattrs.get('posts/'+f[:-3], {}).\
get('attributes', {}).\
get('preview-chars', max_caracteres)
if categoria is not None:
if f in posts_en_categoria:
lp.append((secs_modificacion,
ultima_modificacion,
previewChars,
f))
num_posts += 1
else:
lp.append((secs_modificacion,
ultima_modificacion,
previewChars,
f))
num_posts += 1
lp.sort()
lp.reverse()
# seleccionado por paginas
lp = lp[cantidad*pagina : cantidad*(pagina+1)]
# colocando fecha en formato
for tupla in lp:
cfecha = ctime(tupla[1])
nombre_post = tupla[3].split(os.sep)[-1]
previewChars = tupla[2]
#contenido = cabeza_post(tupla[3], max_caracteres=previewChars)[0]
#categorias = cabeza_post(tupla[3], max_caracteres=previewChars)[1]
contenido = cabezaPost(tupla[3], max_caracteres=previewChars)[0]
categorias = cabezaPost(tupla[3], max_caracteres=previewChars)[1]
cabeza_archivo = markdown.markdown(escape(contenido + ' ...'))
lista_posts.append((nombre_post[:-3], cfecha, \
cabeza_archivo, categorias))
return (lista_posts, num_posts)
def noticias_relacionadas(cantidad=5, nombre=None):
"""Retorna una lista con posts relacionadas, es decir que tienen son de las
mismas categorias que el post con nombre `nombre'.
Cada elemento de la lista de posts contiene el nombre del post
"""
#categorias = categorias_de_post(nombre) ## TODO: corregir categorias de post
categorias = categoriasDePost(nombre)
numero = 0
if categorias is None:
return None
posts = []
for categoria in categorias:
#lista = categorias_list(categoria)[1] # nombres de posts
lista = categoriasList(categoria)[1]
numero += len(lista)
for nombre_post in lista:
if nombre_post + '.md' != nombre:
posts.append(nombre_post)
if numero >= cantidad:
return posts
return posts
def rss_ultimos_posts_jinja(cantidad=15):
"""Retorna una lista de los ultimos posts preparados para
ser renderizados (usando jinja) como un feed rss
Examina cada post del mas reciente al menos reciente, en
total `cantidad' posts. Por cada post devuelve:
id: id which identifies the entry using a
universally unique and permanent URI
author: Get or set autor data. An author element is a dict containing a
name, an email adress and a uri.
category: A categories has the following fields:
- *term* identifies the category
- *scheme* identifies the categorization scheme via a URI.
- *label* provides a human-readable label for display
comments: Get or set the the value of comments which is the url of the
comments page for the item.
content: Get or set the cntent of the entry which contains or links to the
complete content of the entry.
description(no contiene): Get or set the description value which is the item synopsis.
Description is an RSS only element.
link: Get or set link data. An link element is a dict with the fields
href, rel, type, hreflang, title, and length. Href is mandatory for
ATOM.
pubdate(no contiene): Get or set the pubDate of the entry which indicates when the entry
was published.
title: the title value of the entry. It should contain a human
readable title for the entry.
updated: the updated value which indicates the last time the entry
was modified in a significant way.
"""
lista_posts = []
lp = []
num_posts = 0
try:
ow = os.walk("monomotapa/src/posts")
p,d,files=ow.__next__()
except OSError:
print ("[posts] - Error: Can't os.walk() on monomotapa/src/posts except OSError.")
else:
for f in files:
nombre_con_ruta = os.path.join("monomotapa/src/posts", f)
if not f.endswith("~") and not f.startswith("#") and not f.startswith("."):
lp.append((os.path.getmtime(nombre_con_ruta), f))
num_posts += 1
if num_posts > cantidad:
break
lp.sort()
lp.reverse()
# colocando fecha en formato
for tupla in lp:
nombre_post = tupla[1].split(os.sep)[-1]
#contenido = cabeza_post(tupla[1], max_caracteres=149999)
contenido = cabezaPost(tupla[1], max_caracteres=149999)
id_post = "https://rmgss.net/posts/"+nombre_post[:-3]
#categorias = categorias_de_post(nombre_post)
categorias = categoriasDePost(nombre_post)
dict_categorias = {}
c = ""
for cat in categorias:
c += cat + " "
dict_categorias['label'] = c
#dict_categorias['term'] = c
html = markdown.markdown(escape(contenido))
link = id_post
pubdate = ctime(tupla[0])
title = titulo_legible(nombre_post[:-3]) # no incluir '.md'
updated = pubdate
dict_feed_post = {
"id":id_post,
"author": "Rodrigo Garcia",
"category" : categorias,
"content": html,
"link" : id_post,
"updated" : updated,
"title": title
}
lista_posts.append(dict_feed_post)
return lista_posts
###### Define routes
@app.errorhandler(404)
def page_not_found(e):
""" provides basic 404 page"""
defaults = get_page_attributes('defaults.json')
try:
css = defaults['css']
except KeyError:
css = None
pages = get_page_attributes('pages.json')
if '404' in pages:
if'css' in pages['404']:
css = pages['404']['css']
return render_template('static.html',
title = "404::page not found", heading = "Page Not Found",
navigation = top_navigation('404'),
css = css,
contents = Markup(
"This page is not there, try somewhere else.")), 404
@app.route('/users/', defaults={'page': 1})
@app.route('/users/page/<int:page>')
@app.route("/", defaults={'pagina':0})
@app.route('/<int:pagina>')
def index(pagina):
"""provides index page"""
index_page = Page('index')
lista_posts_recientes, total_posts = noticias_recientes(pagina=pagina)
index_page.contexto['lista_posts_recientes'] = lista_posts_recientes
index_page.contexto['total_posts'] = total_posts
index_page.contexto['pagina_actual'] = int(pagina)
return index_page.generate_page()
# default route is it doe not exist elsewhere
@app.route("/<path:page>")
def staticpage(page):
""" display a static page rendered from markdown in src
i.e. displays /page or /page/ as long as src/page.md exists.
srcfile, title and heading may be set in the pages global
(ordered) dictionary but are not required"""
static_page = Page(page)
return static_page.generate_page()
@app.route("/posts/<page>")
def rposts(page):
""" Mustra las paginas dentro la carpeta posts, no es coincidencia
que en este ultimo directorio se guarden los posts.
Ademas incrusta en el diccionario de contexto de la pagina la
fecha de ultima modificacion del post
"""
static_page = Page("posts/"+page)
ultima_modificacion = ultima_modificacion_archivo("posts/"+page)
static_page.contexto['relacionadas'] = noticias_relacionadas(nombre=page+".md")
static_page.contexto['ultima_modificacion'] = ultima_modificacion
static_page.exclude_toc = False # no excluir Índice de contenidos
return static_page.generate_page()
@app.route("/posts")
def indice_posts():
""" Muestra una lista de todos los posts
"""
lista_posts_fecha = posts_list()
#lista_posts_categoria = categorias_list()
lista_posts_categoria = categoriasList()
static_page = Page("posts")
static_page.contexto['lista_posts_fecha'] = lista_posts_fecha
static_page.contexto['lista_posts_categoria'] = lista_posts_categoria
return static_page.generate_page()
@app.route("/posts/categorias")
def lista_categorias():
""" Muestra una lista de las categorias , los posts pertenecen
a cada una y un conteo"""
#lista_categorias = categorias_list()
lista_categorias = categoriasList()
static_page = Page("categorias")
static_page.contexto['lista_posts_categoria'] = lista_categorias
#return (str(lista_categorias))
return static_page.generate_page()
@app.route("/posts/categoria/<categoria>")
def posts_de_categoria(categoria):
""" Muestra los posts que perteneces a la categoria dada
"""
lista_posts = []
if categoria == "fotos": # caegoria especial fotos
lista_posts, total_posts = noticias_recientes(max_caracteres=1250,categoria=categoria)
static_page = Page("fotos")
static_page.contexto['categoria_actual'] = categoria
static_page.contexto['lista_posts_recientes'] = lista_posts
return static_page.generate_page()
#lista_posts = categorias_list(categoria=categoria)
lista_posts = categoriasList(categoria=categoria)
static_page = Page("categorias")
static_page.contexto['categoria_actual'] = categoria
static_page.contexto['lista_posts_categoria'] = lista_posts
return static_page.generate_page()
@app.route("/posts/recientes", defaults={'pagina':0})
@app.route("/posts/recientes/<int:pagina>")
def posts_recientes(pagina):
""" muestra una lista de los posts mas recientes
TODO: terminar
"""
lista_posts, total_posts = noticias_recientes(max_caracteres=368,
pagina=pagina)
static_page = Page("recientes")
static_page.contexto['lista_posts_recientes'] = lista_posts
static_page.contexto['total_posts'] = total_posts
static_page.contexto['pagina_actual'] = pagina
#return (str(lista_posts))
return static_page.generate_page()
@app.route("/contacto", methods=['GET'])
def contacto():
tupla_captcha = captcha_pregunta_opciones_random()
if tupla_captcha is None:
return ("<br>Parece un error interno!</br>")
pregunta = tupla_captcha[0]
opciones = tupla_captcha[1]
static_page = Page("contacto")
static_page.contexto['pregunta'] = pregunta
static_page.contexto['opciones'] = opciones
return static_page.generate_page()
@app.route("/contactoe", methods=['POST'])
def comprobar_mensaje():
""" Comprueba que el mensaje enviado por la caja de texto sea valido
y si lo es, guarda un archivo de texto con los detalles"""
errors = []
if request.method == "POST":
# comprobando validez
nombre = request.form["nombre"]
dir_respuesta = request.form['dir_respuesta']
mensaje = request.form['mensaje']
pregunta = request.form['pregunta']
respuesta = request.form['respuesta']
if len(mensaje) < 2 or mensaje.startswith(" "):
errors.append("Mensaje invalido")
if not captcha_comprobar_respuesta(pregunta, respuesta):
errors.append("Captcha invalido")
if len(errors) > 0:
return str(errors)
# guardando texto
texto = "Remitente: "+nombre
texto += "\nResponder_a: "+dir_respuesta
texto += "\n--- mensaje ---\n"
texto += mensaje
# TODO: cambiar a direccion especificada en archivo de configuracion
dt = datetime.datetime.now()
nombre = "m_"+str(dt.day)+"_"+str(dt.month)+\
"_"+str(dt.year)+"-"+str(dt.hour)+\
"-"+str(dt.minute)+"-"+str(dt.second)
with open(os.path.join("fbs",nombre), "wb") as f:
f.write(texto.encode("utf-8"))
return redirect("/mensaje_enviado", code=302)
@app.route("/mensaje_enviado")
def mensaje_enviado():
static_page = Page("mensaje_enviado")
return static_page.generate_page()
@app.route("/rss")
def rss_feed():
"""Genera la cadena rss con las 15 ultimas noticias del sitio
TODO: Agregar mecenismo para no generar los rss feeds y solo
devolver el archivo rss.xml generado anteriormente. Esto
quiere decir solamente generar el rss_feed cuando se haya hecho
un actualizacion en los posts mas reciente que la ultima vez
que se genero el rss_feed
"""
#return str(rss_ultimos_posts_jinja())
return render_template("rss.html",
contents = rss_ultimos_posts_jinja())
#**vars(self)
#)
##### specialized pages
@app.route("/source")
def source():
"""Display source files used to render a page"""
source_page = Page('source', title = "view the source code",
#heading = "Ver el código fuente",
heading = "Ver el codigo fuente",
internal_css = get_pygments_css())
page = request.args.get('page')
# get source for markdown if any. 404's for non-existant markdown
# unless special page eg source
pagesrc = source_page.get_page_src(page, 'src', 'md')
special_pages = ['source', 'unit-tests', '404']
if not page in special_pages and pagesrc is None:
abort(404)
# set enable_unit_tests to true in config.json to allow
# unit tests to be run through the source page
if app.config['enable_unit_tests']:
contents = '''<p><a href="/unit-tests" class="button">Run unit tests
</a></p>'''
# render tests.py if needed
if page == 'unit-tests':
contents += heading('tests.py', 2)
contents += render_pygments('tests.py', 'python')
else:
contents = ''
# render views.py
contents += heading('views.py', 2)
contents += render_pygments(source_page.get_page_src('views.py'),
'python')
# render markdown if present
if pagesrc:
contents += heading(os.path.basename(pagesrc), 2)
contents += render_pygments(pagesrc, 'markdown')
# render jinja templates
contents += heading('base.html', 2)
contents += render_pygments(
source_page.get_page_src('base.html', 'templates'), 'html')
template = source_page.get_template(page)
contents += heading(template, 2)
contents += render_pygments(
source_page.get_page_src(template, 'templates'), 'html')
return source_page.generate_page(contents)
# @app.route("/unit-tests")
# def unit_tests():
# """display results of unit tests"""
# unittests = Page('unit-tests', heading = "Test Results",
# internal_css = get_pygments_css())
# # exec unit tests in subprocess, capturing stderr
# capture = subprocess.Popen(["python", "tests.py"],
# stdout = subprocess.PIPE, stderr = subprocess.PIPE)
# output = capture.communicate()
# results = output[1]
# contents = '''<p>
# <a href="/unit-tests" class="button">Run unit tests</a>
# </p><br>\n
# <div class="output" style="background-color:'''
# if 'OK' in results:
# color = "#ddffdd"
# result = "TESTS PASSED"
# else:
# color = "#ffaaaa"
# result = "TESTS FAILING"
# contents += ('''%s">\n<strong>%s</strong>\n<pre>%s</pre>\n</div>\n'''
# % (color, result, results))
# # render test.py
# contents += heading('tests.py', 2)
# contents += render_pygments('tests.py', 'python')
# return unittests.generate_page(contents)
En este post veremos como usar un tipo de *VPN* de capa 4 y que todo el tráfico hacia internet que salga de nuestra computadora personal vaya **a través** de una VPN propia con [wireguard](https://www.wireguard.com/).
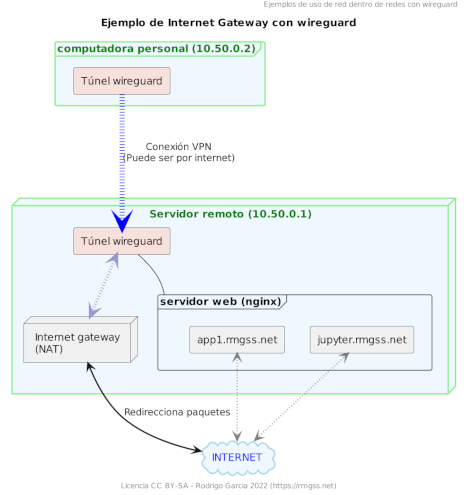
[<- Tamaño original](/static/imgs/posts/vpn-gateway.png)
Es como una evolución [de uno anterior](accediendo-a-equipos-de-casa-mediante-vpn-wireguard) donde se usaba un servidor remoto como **compuerta de entrada** para conectar equipos mediante VPN. En este caso usaremos el mismo servidor para también ser una **compuerta de salida** hacia internet.
**Aviso:** Este post está dividido en 2 secciones:
1. [La primera](#1-redes-de-computadoras-y-como-funcionan-las-vpn-a-grandes-rasgos) por si te interesa saber un poco como funcionan las VPN y las redes TCP/IP en general.
2. [La segunda](#2-configurando-la-vpn) si solo quieres ver un ejemplo de los pasos necesarios para configurar una VPN con salida hacia internet.
## 1. Redes de computadoras y cómo funcionan las VPN a grandes rasgos
Las [redes privadas virtuales](https://es.wikipedia.org/wiki/Red_privada_virtual) *VPN* permiten extender la conexión entre computadoras gracias a su flexibilidad, cifrado y "resistencia a bloqueos" se pueden establecer comunicaciones con mejor protección contra sistemas de vigilancia o filtración. Pero ¿cómo funcionan las VPN de capa 4?
### Una analogía del modelo TCP/IP
El modelo de conexiones de red [TCP/IP](https://es.wikipedia.org/wiki/Modelo_TCP/IP) es una forma de mandar/recibir mensajes alrededor del mundo entre computadoras, este tiene sus complejidades pero la forma en que funciona se asemeja al servicio postal.
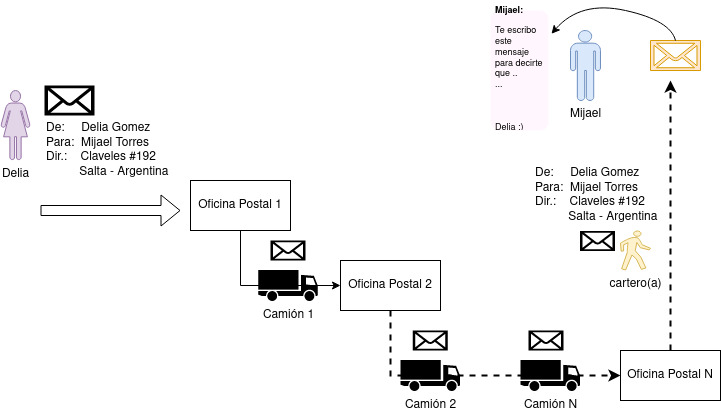
1. Delia escribe un mensaje para Mijael, lo pone en un sobre y escribe en el sobre información para que el mensaje llegue a Mijael.
- **De**: El nombre del remitente. `Delia Gomez`
- **Para**: El nombre del destinatario. `Mijael Torres`
- **Dir.**: La dirección de Mijael. `Claveles #192. Salta - Argentina`
2. Delia lleva el sobre a una oficina postal.
3. La oficina postal comprueba si la **dirección** de Mijael está en su alcance inmediato, como no está, determina cual es la siguiente oficina postal más cercana hacia la dirección de Mijael.
4. La oficina postal despacha el mensaje en un camión o medio de transporte para que lleve el sobre a la siguiente oficina postal.
5. El sobre llega a la oficina postal 2 y esta repite los pasos 3 y 4 de ser necesario.
6. En algún momento los sobres llegan a la oficina postal inmediatamente mas cercana a la dirección de Mijael (La oficina postal N), y esta le entrega el sobre a un cartero para que lo reciba Mijael.
7. El cartero lee la **dirección** de Mijael en el sobre y sale hacia esta dirección para entregarle el sobre.
8. Mijael atiende al cartero que le entrega el sobre, lee que el mensaje viene de Delia Gomez, lo abre y lee el mensaje.
En resumen, el sobre tiene la suficiente metainformación para que cada oficina postal o cartero sepa hacia dónde se debe hacer llegar el mensaje. Las oficinas postales pueden usar **cualquier medio de transporte** para hacer llegar el mensaje, lo importante es que determinarán el camino óptimo para que el sobre llegué a la **dirección** y **destinatario final**.
### Volviendo al modelo TCP/IP
Al igual que el sistema de servicio postal, el modelo TCP/IP es una serie de protocolos y tecnologías que permiten que datos lleguen desde una dirección, el objetivo final es el mismo pero la forma de hacerlo y terminología difiere, más o menos:
<table>
<tr>
<td>Servicio Postal</td>
<td>TCP/IP</td>
<td>Capa TCP/IP</td>
</tr>
<tr>
<td>Mensaje</td>
<td>Datos finales</td>
<td>4 (Aplicación)</td>
</tr>
<tr>
<td>Sobre</td>
<td>Paquetes de datos</td>
<td>3 (Transporte)</td>
</tr>
<tr>
<td>Oficina Postal</td>
<td>Router</td>
<td>2 (Internet)</td>
</tr>
<tr>
<td>Dirección en el sobre</td>
<td>Dirección IP destino</td>
<td>2 (Internet)</td>
</tr>
<tr>
<td>Dirección de otras direcciones postales</td>
<td>Direcciones IP de otros routers</td>
<td>2 (Internet)</td>
</tr>
<tr>
<td>Camión o medio de transporte</td>
<td>Medio físico de transporte</td>
<td>1 (Acceso al medio)</td>
</tr>
</table>
El modelo TCP/IP tiene muchos más elementos y es más sofisticado porque provee también formas de verificar que el mensaje llega sin alteraciones (TCP), de asegurarse de que el destinatario y el remitente sean los correctos (IP destino recibirá siempre el mensaje y se sabrá que viene de IP origen), de encontrar el camino óptimo. etc. Y esto lo hace gracias a diferentes protocolos. Las 4 capas TCP/IP actúan una independientemente de la otra mediante encapsulamiento.
### ¿Qué tiene que ver con VPN?
Imaginémos que Delia quiere enviar un mensaje a Diana de tal forma que el servicio postal no sepa que el remitente es Delia. Una forma de hacerlo es colocar en el contenido del mensaje indicaciones para Mijael que le digan que debe enviar otro mensaje a Diana, el contenido del mensaje tendrá algo como:
> Querido Mijael, por favor envía lo siguiente a Diana de mi parte pero hazlo en otro sobre que venga de ti. La **dirección de Diana** es "Las Palmas #816 - Chiclayo, Perú". Este el mensaje: ...
Si Mijael sigue las instrucciones, escribirá otro mensaje o usará este mismo y lo pondrá en **otro sobre** con la dirección de Diana y lo llevará a la oficina postal mas cercana con él como remitente. De esta manera la oficina postal no sabrá que el mensaje original viene de Delia.
Delia y Mijael podrían ir más lejos y proteger el mensaje escribiendo en otro idioma o codificado de forma que si alguien no autorizado abre el sobre, no pueda entenderlo, es decir aplicarían algún tipo de **cifrado**.
#### Ocultando el remitente en TCP/IP
Los paquetes de datos de red son una serie bits (1 y 0) acomodados en cierto orden de manera que los equipos de red como los *routers* los revisen y sepan dónde enviarlos. Los *routers* revisarán ciertas secciones del paquete para determinar el origen y destino de los paquetes. Luego revisarán secciones de bits diferentes para determinar a qué puerto de la computadora destino irán,cúal es el origen y tomarán en cuenta otras partes del paquete para hacer verificaciones adicionales.
Repasemos un poco una parte de un paquete de datos UDP+IP, [UDP](https://es.wikipedia.org/wiki/Protocolo_de_datagramas_de_usuario) es un protocolo de transporte que permite transmisión de datagramas de forma rápida.
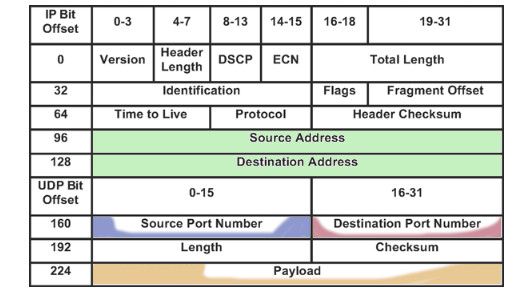
Imagen modificada de [Irwin, David & Slay. Extracting Evidence Related to VoIP Calls.](https://www.researchgate.net/publication/221352750_Extracting_Evidence_Related_to_VoIP_Calls)
La sección del paquete que dice **Payload** son los datos o mensaje y al igual que hizo Delia, se puede enviar en el mensaje mismo otra IP como destinatario final. Algo mas o menos así:
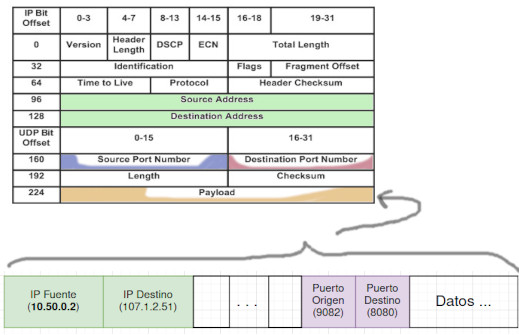
El encapsulamiento permite incrustar en el payload del mensaje otras direcciones, puertos y datos. Como si se tratase de un paquete dentro de uno o más paquetes. Las VPN como wireguard van más lejos y usan protocolos y algoritmos de cifrado para que todo el tráfico dentro del payload solo sea reconocible por **miembros autorizados**.
Para que una VPN funcione, se necesitan programas que hagan como Mijael, es decir, revisen el mensaje (*payload*) y busquen si se trata de un mensaje que en realidad va para otra dirección que no esté declarada en las cabeceras *Source Address, Destination Address* originales de los paquetes UDP+IP.
Esto es encapsular paquetes dentro de otros paquetes, y si el programa detecta que este paquete es para otro destinatario entonces lo reenviará para que el resto de la red se encargue de hacerlo llegar al destino real. Entonces, en la práctica tenemos una **red virtual**. Si se agrega cifrado y otras medidas de seguridad, se tiene una red privada virtual (*VPN*) mucho mas segura, flexible y resistente a posibles bloqueos o vigilancia indiscriminada por parte de cualquier equipo dentro de la red.
----
## 2. Configurando la VPN
Ahora configuraremos un servidor remoto y una computadora cliente para crear una VPN con wireguard, luego haremos que la computadora cliente salga a internet a través de la conexión VPN hacia el servidor y que el servidor redirija los paquetes del cliente hacia el internet a modo de compuerta de salida o *internet gateway*.
### Lo necesario
Para el resto de este tutorial se asume que se tiene un servidor y computadora con GNU/Linux, para este tutorial se usa debian 11 en ambos lados, sin embargo wireguard también funciona en otros S.O. como Windows. Lo que si es necesario es tener acceso a un servidor remoto que tenga conexión a internet.

[<- más grande](/static/imgs/posts/vpn-gateway.png)
El anterior es un diagrama de un caso posible de uso donde hay un servidor web, lo importante es la parte de conexión por VPN y salida por NAT. La implementación siguiente es sólo para configurar la conexión por VPN y uso del servidor como *internet gateway*.
### Poniendo servidor y pc en la misma VPN
Para este primer paso puedes revisar el post [Accediendo a equipos de casa mediante VPN wireguard](accediendo-a-equipos-de-casa-mediante-vpn-wireguard) como otro ejemplo. Pero resumiendo las configuraciones las haremos como en el diagrama
anterior:
* Servidor
* IP: 10.50.0.1
* Puerto: 51830
* Gateway y NAT
* Cliente
* IP: 10.50.0.2
* Puerto: 51830
Ahora declararemos los archivos de configuración de wireguard.
#### wireguard.conf en el Servidor
:::conf
[Interface]
PrivateKey = YPrreNTz7...
ListenPort = 51830
# peer pc
[Peer]
PublicKey = yQ2po/Rl3...
AllowedIPs = 10.50.0.2/32
En el servidor declaramos también el *peer* de la pc
#### wireguard.conf en el cliente
:::conf
[Interface]
PrivateKey = cMNHAA7vY6k9X...
ListenPort = 51830
# peer servidor (gateway server)
[Peer]
PublicKey = BTg7lbZWQ...
Endpoint = <IP o dominio del servidor>:51830
AllowedIPs = 0.0.0.0/0
PersistentKeepalive = 15
#### Interfaz de red, masquerading y NAT en el servidor
Wireguard es tan conveniente que nos permite dedicar una interfaz de red a la VPN. El siguiente script en bash, nos ayuda a crear la interfaz de red para wireguard (`wg0`), habilitar *NAT* (Network Address Translation) y agregar reglas de ruteo para que cuando se reciba tráfico en la interfaz `wg0` este pueda ser redirigido hacia internet aplicando *NAT masquerading*.
:::bash
#!/bin/bash
# levantar.sh
WG=wg
conf_file=./wireguard.conf
interface=wg0
address=10.50.0.1
nw_cidr=10.50.0.0/24
nw_interface=eth0 # interfaz por la que el servidor sale hacia internet
# Configurando interfaces de red
ip link del dev $interface 2>/dev/null || true
ip link add $interface type wireguard
ip addr add $address/24 dev $interface
ip link set $interface up
# usando archivo de config
$WG setconf $interface $conf_file
$WG show
# Habilitando masquerading
echo "net.ipv4.ip_forward = 1" > /etc/sysctl.d/70-wireguard-routing.conf
sysctl -p /etc/sysctl.d/70-wireguard-routing.conf -w
# Agrega la regla NAT a la cadena POSTROUTING para tráfico ya filtrado por iptables
iptables -t nat -A POSTROUTING -s $nw_cidr -o $nw_interface -j MASQUERADE
# mtu
ip link set mtu 1378 up dev $interface
exit 0
Ejecutaremos el script con privilegios de superusuario. `sudo bash levantar.sh`. Con `ip a` se debería mostrar una interfaz `wg0` existente y con `sudo iptables -t nat -L -v`:
Chain POSTROUTING (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
0 0 MASQUERADE all -- any eth0 10.50.0.0/24 anywhere
#### Interfaz de red, reglas para salir a internet a través de la conexión VPN
:::bash
#!/bin/bash
# levantar.sh
WG=wg
conf_file=./wireguard.conf
interface=wg0
address=10.50.0.2
# Configurando interfaces de red
ip link del dev $interface 2>/dev/null || true
ip link add $interface type wireguard
ip addr add $address/24 dev $interface
ip link set $interface up
# usando archivo de config wireguard.con
$WG setconf $interface $conf_file
$WG show
# mtu
ip link set mtu 1420 up dev $interface
# fwmark agrega una marca a los paquetes de wireguard para que
# se manden a una tabla de ruteo alternativa, en este caso 51820
wg set $interface fwmark 51820
wg setconf $interface /dev/fd/63
ip link set mtu 1420 up dev $interface
# se establece la ruta por defecto hacia la tabla de ruteo 51820
ip -4 route add 0.0.0.0/0 dev $interface table 51820
# los paquetes que no tienen la marca fwmark iran a esta tabla alternativa
ip -4 rule add not fwmark 51820 table 51820
# Se permiten a los paquetes sin la marca, usar la tabla de ruteo principal
ip -4 rule add table main suppress_prefixlength 0
sysctl -q net.ipv4.conf.all.src_valid_mark=1
nft -f /dev/fd/63
exit 0
Ahora ejecutamos el script con `sudo bash levantar.sh`. Para probar que la conexión con el servidor funciona, `ping 10.50.0.1` debería funcionar.
Para comprobar que el tráfico a internet va por VPN a través del servidor, se puede hacer `traceroute 1.1.1.1` que debería mostrar el primer salto como la IP del servidor en la VPN.
traceroute to 1.1.1.1 (1.1.1.1), 30 hops max, 60 byte packets
1 10.50.0.1 (10.50.0.1) 224.311 ms 224.063 ms 223.958 ms
2 * * *
3 51.12.176.255 (51.12.176.255) 224.546 ms 224.427 ms 224.305 ms
4 195.12.20.173 (195.12.20.173) 225.083 ms 225.010 ms 225.157 ms
5 195.22.0.8 (195.22.0.8) 228.603 ms 228.657 ms 228.534 ms
6 170.4.122.195.in-addr.arpa (195.22.0.8) 228.520 ms 240.060 ms 239.866 ms
7 1.1.1.1.in-addr.arpa (1.1.1.1) 227.739 ms 228.523 ms 228.461 ms
## Conclusiones
Existen muchos servicios que permiten salir a internet a través de VPN, a pesar de que muchos son buenos hay otros que no son garantizados y también son poco transparentes. Esta solución nos permite tener un mayor control.
Ahora podemos navegar por internet usando el servidor como puerta de acceso, además el tráfico va cifrado y sobre una red que podemos extender a nuestra conveniencia. Por ejemplo agregando más equipos o uniéndose a otras redes. Se puede agregar más seguridad por ejemplo sobre el tráfico DNS como se ve en los enlaces adicionales.
Espero este tutorial te haya ayudado a entender mejor cómo funcionan internamente las redes dentro de otras redes ;)
## Enlaces de interés
* [A little bit about how VPN actually works… – The 4-Layer TCP/IP Stack + TLS](https://www.kiloroot.com/a-little-bit-about-how-vpn-actually-works-the-4-layer-tcpip-stack-tls/). Este artículo también explica como funcionan las VPN de forma mas de detallada.
* [Using the VPN as the default gateway](https://ubuntu.com/server/docs/wireguard-vpn-defaultgw). Usé ese post para configurar el mecanismo del default gateway en el cliente y el servidor.
* [Configure NAT masquerading in iptables](https://www.adamintech.com/configure-nat-masquerading-in-iptables/). Sobre `iptables` y *masquerading*.


 Posts
Posts
 Categorías
Categorías
 Fotos
Fotos
 Acerca de mi
Acerca de mi
 Contacto
Contacto