# -*- coding: utf-8 -*-
"""
Monomotapa - A Micro CMS
Copyright (C) 2014, Paul Munday.
PO Box 28228, Portland, OR, USA 97228
paul at paulmunday.net
Modificado por: Rodrigo Garcia 2017 https://rmgss.net/contacto
This program is free software: you can redistribute it and/or modify
it under the terms of the GNU Affero Public License as published by
the Free Software Foundation, either version 3 of the License, or
(at your option) any later version.
This program is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU General Public License for more details.
You should have received a copy of the GNU Affero General Public License
along with this program. If not, see <http://www.gnu.org/licenses/>.
Monomotapa:
a city whose inhabitants are bounded by deep feelings of friendship,
so that they intuit one another's most secret needs and desire.
For instance, if one dreams that his friend is sad, the friend will
perceive the distress and rush to the sleepers rescue.
(Jean de La Fontaine, *Fables choisies, mises en vers*, VIII:11 Paris,
2nd ed., 1678-9)
cited in :
Alberto Manguel and Gianni Guadalupi, *The Dictionary of Imaginary Places*,
Bloomsbury, London, 1999.
A micro cms written using the Flask microframework, orignally to manage my
personal site. It is designed so that publishing a page requires no more than
dropping a markdown page in the appropriate directory (though you need to edit
a json file if you want it to appear in the top navigation).
It can also display its own source code and run its own unit tests.
The name 'monomotapa' was chosen more or less at random (it shares an initial
with me) as I didn't want to name it after the site and be typing import
paulmunday, or something similar, as that would be strange.
"""
from flask import render_template, abort, Markup, escape, request #, make_response
from flask import redirect
from werkzeug.utils import secure_filename
from pygments import highlight
from pygments.lexers import PythonLexer, HtmlDjangoLexer, TextLexer
from pygments.formatters import HtmlFormatter
import markdown
from time import gmtime, strptime, strftime, ctime, mktime
import datetime
import os.path
import os
import subprocess
import json
import traceback
from collections import OrderedDict
from simplemotds import SimpleMotd
from monomotapa import app
from monomotapa.config import ConfigError
from monomotapa.utils import captcha_comprobar_respuesta, captcha_pregunta_opciones_random
from monomotapa.utils import categorias_de_post, categoriasDePost, categoriasList, cabezaPost
from monomotapa.utils import titulo_legible, metaTagsAutomaticos
from markdown.extensions.toc import TocExtension
json_pattrs = {}
with open(os.path.join('monomotapa','pages.json'), 'r') as pagefile:
json_pattrs = json.load(pagefile)
simplemotd = SimpleMotd("config_simplemotds.json")
class MonomotapaError(Exception):
"""create classs for own errors"""
pass
def get_page_attributes(jsonfile):
"""Returns dictionary of page_attributes.
Defines additional static page attributes loaded from json file.
N.B. static pages do not need to have attributes defined there,
it is sufficient to have a page.md in src for each /page
possible values are src (name of markdown file to be rendered)
heading, title, and trusted (i.e. allow embeded html in markdown)"""
try:
with open(src_file(jsonfile), 'r') as pagesfile:
page_attributes = json.load(pagesfile)
except IOError:
page_attributes = []
return page_attributes
def get_page_attribute(attr_src, page, attribute):
"""returns attribute of page if it exists, else None.
attr_src = dictionary(from get_page_attributes)"""
if page in attr_src and attribute in attr_src[page]:
return attr_src[page][attribute]
else:
return None
# Navigation
def top_navigation(page):
"""Generates navigation as an OrderedDict from navigation.json.
Navigation.json consists of a json array(list) "nav_order"
containing the names of the top navigation elements and
a json object(dict) called "nav_elements"
if a page is to show up in the top navigation
there must be an entry present in nav_order but there need not
be one in nav_elements. However if there is the key must be the same.
Possible values for nav_elements are link_text, url and urlfor
The name from nav_order will be used to set the link text,
unless link_text is present in nav_elements.
url and urlfor are optional, however if ommited the url wil be
generated in the navigation by url_for('staticpage', page=[key])
equivalent to @app.route"/page"; def page())
which may not be correct. If a url is supplied it will be used
otherwise if urlfor is supplied it the url will be
generated with url_for(urlfor). url takes precendence so it makes
no sense to supply both.
Web Sign-in is supported by adding a "rel": "me" attribute.
"""
with open(src_file('navigation.json'), 'r') as navfile:
navigation = json.load(navfile)
base_nav = OrderedDict({})
for key in navigation["nav_order"]:
nav = {}
nav['base'] = key
nav['link_text'] = key
if key in navigation["nav_elements"]:
elements = navigation["nav_elements"][key]
nav.update(elements)
base_nav[key] = nav
return {'navigation' : base_nav, 'page' : page}
# For pages
class Page:
"""Generates pages as objects"""
def __init__(self, page, **kwargs):
"""Define attributes for pages (if present).
Sets self.name, self.title, self.heading, self.trusted etc
This is done through indirection so we can update the defaults
(defined in the 'attributes' dictionary) with values from config.json
or pages.json easily without lots of if else statements.
If css is supplied it will overide any default css. To add additional
style sheets on a per page basis specifiy them in pages.json.
The same also applies with hlinks.
css is used to set locally hosted stylesheets only. To specify
external stylesheets use hlinks: in config.json for
default values that will apply on all pages unless overidden, set here
to override the default. Set in pages.json to add after default.
"""
# set default attributes
self.page = page.rstrip('/')
self.defaults = get_page_attributes('defaults.json')
self.pages = get_page_attributes('pages.json')
self.url_base = self.defaults['url_base']
title = titulo_legible(page.lower())
heading = titulo_legible(page.capitalize())
self.categorias = categoriasDePost(self.page)
self.exclude_toc = True
try:
self.default_template = self.defaults['template']
except KeyError:
raise ConfigError('template not found in default.json')
# will become self.name, self.title, self.heading,
# self.footer, self.internal_css, self.trusted
attributes = {'name' : self.page, 'title' : title,
'navigation' : top_navigation(self.page),
'heading' : heading, 'footer' : None,
'css' : None , 'hlinks' :None, 'internal_css' : None,
'trusted': False,
'preview-chars': 250,
}
# contexto extra TODO: revisar otra forma de incluir un contexto
self.contexto = {}
self.contexto['consejo'] = simplemotd.getMotdContent()
# set from defaults
attributes.update(self.defaults)
# override with kwargs
attributes.update(kwargs)
# override attributes if set in pages.json
if page in self.pages:
attributes.update(self.pages[page])
# set attributes (as self.name etc) using indirection
for attribute, value in attributes.items():
# print('attribute', attribute, '=-==>', value)
setattr(self, attribute, value)
# meta tags
try:
self.pages[self.page]['title'] = attributes['title']
self.pages[self.page]['url_base'] = self.url_base
metaTags = metaTagsAutomaticos(self.page, self.pages.get(self.page, {}))
self.meta = metaTags
# for key, value in self.pages[self.page].items():
# print(' ', key, ' = ', value)
except Exception as e:
tb = traceback.format_exc()
print('Error assigning meta:', str(e), '\n', str(tb))
# reset these as we want to append rather than overwrite if supplied
if 'css' in kwargs:
self.css = kwargs['css']
elif 'css' in self.defaults:
self.css = self.defaults['css']
if 'hlinks' in kwargs:
self.hlinks = kwargs['hlinks']
elif 'hlinks' in self.defaults:
self.hlinks = self.defaults['hlinks']
# append hlinks and css from pages.json rather than overwriting
# if css or hlinks are not supplied they are set to default
if page in self.pages:
if 'css' in self.pages[page]:
self.css = self.css + self.pages[page]['css']
if 'hlinks' in self.pages[page]:
self.hlinks = self.hlinks + self.pages[page]['hlinks']
# append heading to default if set in config
self.title = self.title + app.config.get('default_title', '')
def _get_markdown(self):
"""returns rendered markdown or 404 if source does not exist"""
src = self.get_page_src(self.page, 'src', 'md')
if src is None:
abort(404)
else:
return render_markdown(src, self.trusted)
def get_page_src(self, page, directory=None, ext=None):
""""return path of file (used to generate page) if it exists,
or return none.
Also returns the template used to render that page, defaults
to static.html.
It will optionally add an extension, to allow
specifiying pages by route."""
# is it stored in a config
pagename = get_page_attribute(self.pages, page, 'src')
if not pagename:
pagename = page + get_extension(ext)
if os.path.exists(src_file(pagename , directory)):
return src_file(pagename, directory)
else:
return None
def get_template(self, page):
"""returns the template for the page"""
pagetemplate = get_page_attribute(self.pages, page, 'template')
if not pagetemplate:
pagetemplate = self.default_template
if os.path.exists(src_file(pagetemplate , 'templates')):
return pagetemplate
else:
raise MonomotapaError("Template: %s not found" % pagetemplate)
def generate_page(self, contents=None):
"""return a page generator function.
For static pages written in Markdown under src/.
contents are automatically rendered.
N.B. See note above in about headers"""
toc = '' # table of contents
if not contents:
contents, toc = self._get_markdown()
# print('////', toc)
template = self.get_template(self.page)
# print('......................')
# def mos(**kwargs):
# for k in kwargs:
# print(k, end=',')
# mos(**vars(self))
return render_template(template,
contents = Markup(contents),
toc=toc,
**vars(self))
# helper functions
def src_file(name, directory=None):
"""return potential path to file in this app"""
if not directory:
return os.path.join( 'monomotapa', name)
else:
return os.path.join('monomotapa', directory, name)
def get_extension(ext):
'''constructs extension, adding or stripping leading . as needed.
Return null string for None'''
if ext is None:
return ''
elif ext[0] == '.':
return ext
else:
return '.%s' % ext
def render_markdown(srcfile, trusted=False):
""" Returns markdown file rendered as html and the table of contents as html.
Defaults to untrusted:
html characters (and character entities) are escaped
so will not be rendered. This departs from markdown spec
which allows embedded html."""
try:
with open(srcfile, 'r') as f:
src = f.read()
md = markdown.Markdown(extensions=['toc', 'codehilite'])
md.convert(src)
toc = md.toc
if trusted == True:
content = markdown.markdown(src,
extensions=['codehilite',
TocExtension(permalink=True)])
else:
content = markdown.markdown(escape(src),
extensions=['codehilite',
TocExtension(permalink=True)])
return content, toc
except IOError:
return None
def render_pygments(srcfile, lexer_type):
"""returns src(file) marked up with pygments"""
if lexer_type == 'python':
with open(srcfile, 'r') as f:
src = f.read()
contents = highlight(src, PythonLexer(), HtmlFormatter())
elif lexer_type == 'html':
with open(srcfile, 'r') as f:
src = f.read()
contents = highlight(src, HtmlDjangoLexer(), HtmlFormatter())
# default to TextLexer for everything else
else:
with open(srcfile, 'r') as f:
src = f.read()
contents = highlight(src, TextLexer(), HtmlFormatter())
return contents
def get_pygments_css(style=None):
"""returns css for pygments, use as internal_css"""
if style is None:
style = 'friendly'
return HtmlFormatter(style=style).get_style_defs('.highlight')
def heading(text, level):
"""return as html heading at h[level]"""
heading_level = 'h%s' % str(level)
return '\n<%s>%s</%s>\n' % (heading_level, text, heading_level)
def posts_list(ordenar_por_fecha=True, ordenar_por_nombre=False):
'''Retorna una lista con los nombres de archivos con extension .md
dentro de la cappeta src/posts, por defecto retorna una lista con
la tupla (nombre_archivo, fecha_subida)'''
lista_posts = []
lp = []
if ordenar_por_nombre:
try:
ow = os.walk("monomotapa/src/posts")
p , directorios , archs = ow.__next__()
except OSError:
print ("[posts] - Error: Cant' os.walk() on monomotapa/src/posts except OSError")
else:
for arch in archs:
if arch.endswith(".md") and not arch.startswith("#") \
and not arch.startswith("~") and not arch.startswith("."):
lista_posts.append(arch)
lista_posts.sort()
return lista_posts
if ordenar_por_fecha:
try:
ow = os.walk("monomotapa/src/posts")
p,d,files=ow.__next__()
except OSError:
print ("[posts] - Error: Can't os.walk() on monomotapa/src/posts except OSError.")
else:
for f in files:
nombre_con_ruta = os.path.join("monomotapa/src/posts", f)
if not f.endswith("~") and not f.startswith("#") and not f.startswith("."):
secs_modificacion = SecsModificacionPostDesdeJson(f, json_pattrs)
ultima_modificacion = os.path.getmtime(nombre_con_ruta)
lp.append((secs_modificacion, ultima_modificacion, f))
lp.sort()
lp.reverse()
# colocando fecha en formato
for tupla in lp:
#fecha = strftime("a, %d %b %Y %H:%M:%S", ctime(tupla[0]))
cfecha = ctime(tupla[1])
#fecha = strptime("%a %b %d %H:%M:%S %Y", cfecha)
lista_posts.append((cfecha, tupla[2]))
return lista_posts
def categorias_list(categoria=None):
""" Rotorna una lista con los nombres de posts y el numero de posts que
pertenecen a la categoria dada o a cada categoria.
Las categorias se obtienen analizando la primera linea de cada archivo .md
an la carpeta donde se almacenan los posts.
Si no se especifica `categoria' cada elemento de la lista devuelta es:
(nombre_categoria, numero_posts, [nombres_posts])
si se especifica `categoria' cada elemento de la lista devuelta es:
(numero_posts, [nombres_posts]
"""
lista_posts = posts_list(ordenar_por_nombre=True)
lista_categorias = []
if categoria is not None:
c = 0
posts = []
for post in lista_posts:
nombre_arch = "monomotapa/src/posts/"+post
with open(nombre_arch, 'r') as file:
linea = file.readline().decode("utf-8")
lc = linea.split("[#")[1:]
for cad in lc:
cat = cad.split("]")[0]
if cat == categoria:
c += 1
posts.append(post)
lista_categorias = (c, posts)
return lista_categorias
dic_categorias = {}
for post in lista_posts:
nombre_arch = "monomotapa/src/posts/"+post
with open(nombre_arch, 'r') as fil:
linea = fil.readline().decode('utf-8') # primera linea
# extrayendo las categorias y registrando sus ocurrencias
# ejemplo: catgorías: [#reflexión](categoria/reflexion) [#navidad](categoria/navidad)
# extrae: [reflexion,navidad]
lc = linea.split("[#")[1:]
for cad in lc:
cat = cad.split("]")[0]
if cat not in dic_categorias:
dic_categorias[cat] = (1,[post]) # nuevo registro por categoria
else:
tupla = dic_categorias[cat]
c = tupla[0] + 1
lis = tupla[1]
if post not in lis:
lis.append(post)
dic_categorias[cat] = (c, lis)
# convirtiendo en lista
for k, v in dic_categorias.iteritems():
lista_categorias.append((k,v[0],v[1]))
lista_categorias.sort()
lista_categorias.reverse()
return lista_categorias
def cabeza_post(archivo , max_caracteres=250, categorias=True):
""" Devuelve las primeras lineas de una archivo de post (en formato markdown)
con un maximo numero de caracteres excluyendo titulos en la cabeza devuelta.
Si se especifica `categorias' en True
Se devuelve una lista de la forma:
(cabeza_post, categorias)
donde categorias son cadenas con los nombres de las categorias a la que
pertenece el post
"""
cabeza_post = ""
cats = []
with open(os.path.join("monomotapa/src/posts",archivo)) as file:
# analizando si hay titulos al principio
# Se su pone que la primera linea es de categorias
for linea in file.readlines():
linea = linea.decode("utf-8")
if linea.startswith(u"categorías:") or linea.startswith("categorias"):
if categorias:
cats = categoriasDePost(archivo)
#cats = categorias_de_post(archivo)
else:
# evitando h1, h2
if linea.startswith("##") or linea.startswith("#"):
cabeza_post += " "
else:
cabeza_post += linea
if len(cabeza_post) >= max_caracteres:
break
cabeza_post = cabeza_post[0:max_caracteres-1]
if categorias:
return (cabeza_post, cats)
return cabeza_post
def ultima_modificacion_archivo(archivo):
""" Retorna una cadena indicando la fecha de ultima modificacion del
`archivo' dado, se asume que `archivo' esta dentro la carpeta "monomotapa/src"
Retorna una cadena vacia en caso de no poder abrir `archivo'
"""
try:
ts = strptime(ctime(os.path.getmtime("monomotapa/src/"+archivo+".md")))
return strftime("%d %B %Y", ts)
except OSError:
return ""
def SecsModificacionPostDesdeJson(archivo, dict_json):
''' dado el post con nombre 'archivo' busca en 'dict_json' el
attribute 'date' y luego obtiene los segundos totales desde
esa fecha.
Si no encuentra 'date' para 'archivo' en 'dict.json'
retorna los segundos totales desde la ultima modificacion
del archivo de post directamente (usa os.path.getmtime)
'''
nombre = archivo.split('.md')[0] # no contar extension .md
nombre_con_ruta = os.path.join("monomotapa/src/posts", archivo)
date_str = dict_json.get('posts/'+nombre, {}).\
get('attributes',{}).\
get('date','')
if date_str == '':
# el post no tiene "date" en pages.json
return os.path.getmtime(nombre_con_ruta)
else:
time_struct = strptime(date_str, '%Y-%m-%d')
dt = datetime.datetime.fromtimestamp(mktime(time_struct))
return (dt - datetime.datetime(1970,1,1)).total_seconds()
def noticias_recientes(cantidad=11, max_caracteres=250,
categoria=None, pagina=0):
'''Devuelve una lista con hasta `cantidad' de posts mas recientes,
un maximo de `max_caracteres' de caracteres del principio del post y
el numero total de posts encontrados
Si se proporciona `categoria' devuelve la lista de posts solamente
pertenecientes esa categoria.
Si `pagina' > 0 se devulve hasta `cantidad' numero de posts en el
rango de [ cantidad*pagina : cantidad*(pagina+1)]
Cada elemento de la lista devuelta contiene:
(nombre_post, ultima_modificacion, cabeza_archivo, categorias)
Al final se retorna: (lista_posts, numero_de_posts)
'''
lista_posts = []
lp = []
num_posts = 0
posts_en_categoria = []
if categoria is not None:
#posts_en_categoria = categorias_list(categoria)[1]
posts_en_categoria = categoriasList(categoria)[1]
# categoria especial fotos
if categoria == "fotos":
l = []
for p in posts_en_categoria:
l.append(p + '.md')
posts_en_categoria = l
try:
ow = os.walk("monomotapa/src/posts")
p,d,files = ow.__next__()
#p,d,files=ow.next()
except OSError:
print ("[posts] - Error: Can't os.walk() on monomotapa/src/posts except OSError.")
else:
for f in files:
nombre_con_ruta = os.path.join("monomotapa/src/posts", f)
if not f.endswith("~") and not f.startswith("#") and not f.startswith("."):
secs_modificacion = SecsModificacionPostDesdeJson(f, json_pattrs)
ultima_modificacion = os.path.getmtime(nombre_con_ruta)
previewChars = json_pattrs.get('posts/'+f[:-3], {}).\
get('attributes', {}).\
get('preview-chars', max_caracteres)
if categoria is not None:
if f in posts_en_categoria:
lp.append((secs_modificacion,
ultima_modificacion,
previewChars,
f))
num_posts += 1
else:
lp.append((secs_modificacion,
ultima_modificacion,
previewChars,
f))
num_posts += 1
lp.sort()
lp.reverse()
# seleccionado por paginas
lp = lp[cantidad*pagina : cantidad*(pagina+1)]
# colocando fecha en formato
for tupla in lp:
cfecha = ctime(tupla[1])
nombre_post = tupla[3].split(os.sep)[-1]
previewChars = tupla[2]
#contenido = cabeza_post(tupla[3], max_caracteres=previewChars)[0]
#categorias = cabeza_post(tupla[3], max_caracteres=previewChars)[1]
contenido = cabezaPost(tupla[3], max_caracteres=previewChars)[0]
categorias = cabezaPost(tupla[3], max_caracteres=previewChars)[1]
cabeza_archivo = markdown.markdown(escape(contenido + ' ...'))
lista_posts.append((nombre_post[:-3], cfecha, \
cabeza_archivo, categorias))
return (lista_posts, num_posts)
def noticias_relacionadas(cantidad=5, nombre=None):
"""Retorna una lista con posts relacionadas, es decir que tienen son de las
mismas categorias que el post con nombre `nombre'.
Cada elemento de la lista de posts contiene el nombre del post
"""
#categorias = categorias_de_post(nombre) ## TODO: corregir categorias de post
categorias = categoriasDePost(nombre)
numero = 0
if categorias is None:
return None
posts = []
for categoria in categorias:
#lista = categorias_list(categoria)[1] # nombres de posts
lista = categoriasList(categoria)[1]
numero += len(lista)
for nombre_post in lista:
if nombre_post + '.md' != nombre:
posts.append(nombre_post)
if numero >= cantidad:
return posts
return posts
def rss_ultimos_posts_jinja(cantidad=15):
"""Retorna una lista de los ultimos posts preparados para
ser renderizados (usando jinja) como un feed rss
Examina cada post del mas reciente al menos reciente, en
total `cantidad' posts. Por cada post devuelve:
id: id which identifies the entry using a
universally unique and permanent URI
author: Get or set autor data. An author element is a dict containing a
name, an email adress and a uri.
category: A categories has the following fields:
- *term* identifies the category
- *scheme* identifies the categorization scheme via a URI.
- *label* provides a human-readable label for display
comments: Get or set the the value of comments which is the url of the
comments page for the item.
content: Get or set the cntent of the entry which contains or links to the
complete content of the entry.
description(no contiene): Get or set the description value which is the item synopsis.
Description is an RSS only element.
link: Get or set link data. An link element is a dict with the fields
href, rel, type, hreflang, title, and length. Href is mandatory for
ATOM.
pubdate(no contiene): Get or set the pubDate of the entry which indicates when the entry
was published.
title: the title value of the entry. It should contain a human
readable title for the entry.
updated: the updated value which indicates the last time the entry
was modified in a significant way.
"""
lista_posts = []
lp = []
num_posts = 0
try:
ow = os.walk("monomotapa/src/posts")
p,d,files=ow.__next__()
except OSError:
print ("[posts] - Error: Can't os.walk() on monomotapa/src/posts except OSError.")
else:
for f in files:
nombre_con_ruta = os.path.join("monomotapa/src/posts", f)
if not f.endswith("~") and not f.startswith("#") and not f.startswith("."):
lp.append((os.path.getmtime(nombre_con_ruta), f))
num_posts += 1
if num_posts > cantidad:
break
lp.sort()
lp.reverse()
# colocando fecha en formato
for tupla in lp:
nombre_post = tupla[1].split(os.sep)[-1]
#contenido = cabeza_post(tupla[1], max_caracteres=149999)
contenido = cabezaPost(tupla[1], max_caracteres=149999)
id_post = "https://rmgss.net/posts/"+nombre_post[:-3]
#categorias = categorias_de_post(nombre_post)
categorias = categoriasDePost(nombre_post)
dict_categorias = {}
c = ""
for cat in categorias:
c += cat + " "
dict_categorias['label'] = c
#dict_categorias['term'] = c
html = markdown.markdown(escape(contenido))
link = id_post
pubdate = ctime(tupla[0])
title = titulo_legible(nombre_post[:-3]) # no incluir '.md'
updated = pubdate
dict_feed_post = {
"id":id_post,
"author": "Rodrigo Garcia",
"category" : categorias,
"content": html,
"link" : id_post,
"updated" : updated,
"title": title
}
lista_posts.append(dict_feed_post)
return lista_posts
###### Define routes
@app.errorhandler(404)
def page_not_found(e):
""" provides basic 404 page"""
defaults = get_page_attributes('defaults.json')
try:
css = defaults['css']
except KeyError:
css = None
pages = get_page_attributes('pages.json')
if '404' in pages:
if'css' in pages['404']:
css = pages['404']['css']
return render_template('static.html',
title = "404::page not found", heading = "Page Not Found",
navigation = top_navigation('404'),
css = css,
contents = Markup(
"This page is not there, try somewhere else.")), 404
@app.route('/users/', defaults={'page': 1})
@app.route('/users/page/<int:page>')
@app.route("/", defaults={'pagina':0})
@app.route('/<int:pagina>')
def index(pagina):
"""provides index page"""
index_page = Page('index')
lista_posts_recientes, total_posts = noticias_recientes(pagina=pagina)
index_page.contexto['lista_posts_recientes'] = lista_posts_recientes
index_page.contexto['total_posts'] = total_posts
index_page.contexto['pagina_actual'] = int(pagina)
return index_page.generate_page()
# default route is it doe not exist elsewhere
@app.route("/<path:page>")
def staticpage(page):
""" display a static page rendered from markdown in src
i.e. displays /page or /page/ as long as src/page.md exists.
srcfile, title and heading may be set in the pages global
(ordered) dictionary but are not required"""
static_page = Page(page)
return static_page.generate_page()
@app.route("/posts/<page>")
def rposts(page):
""" Mustra las paginas dentro la carpeta posts, no es coincidencia
que en este ultimo directorio se guarden los posts.
Ademas incrusta en el diccionario de contexto de la pagina la
fecha de ultima modificacion del post
"""
static_page = Page("posts/"+page)
ultima_modificacion = ultima_modificacion_archivo("posts/"+page)
static_page.contexto['relacionadas'] = noticias_relacionadas(nombre=page+".md")
static_page.contexto['ultima_modificacion'] = ultima_modificacion
static_page.exclude_toc = False # no excluir Índice de contenidos
return static_page.generate_page()
@app.route("/posts")
def indice_posts():
""" Muestra una lista de todos los posts
"""
lista_posts_fecha = posts_list()
#lista_posts_categoria = categorias_list()
lista_posts_categoria = categoriasList()
static_page = Page("posts")
static_page.contexto['lista_posts_fecha'] = lista_posts_fecha
static_page.contexto['lista_posts_categoria'] = lista_posts_categoria
return static_page.generate_page()
@app.route("/posts/categorias")
def lista_categorias():
""" Muestra una lista de las categorias , los posts pertenecen
a cada una y un conteo"""
#lista_categorias = categorias_list()
lista_categorias = categoriasList()
static_page = Page("categorias")
static_page.contexto['lista_posts_categoria'] = lista_categorias
#return (str(lista_categorias))
return static_page.generate_page()
@app.route("/posts/categoria/<categoria>")
def posts_de_categoria(categoria):
""" Muestra los posts que perteneces a la categoria dada
"""
lista_posts = []
if categoria == "fotos": # caegoria especial fotos
lista_posts, total_posts = noticias_recientes(max_caracteres=1250,categoria=categoria)
static_page = Page("fotos")
static_page.contexto['categoria_actual'] = categoria
static_page.contexto['lista_posts_recientes'] = lista_posts
return static_page.generate_page()
#lista_posts = categorias_list(categoria=categoria)
lista_posts = categoriasList(categoria=categoria)
static_page = Page("categorias")
static_page.contexto['categoria_actual'] = categoria
static_page.contexto['lista_posts_categoria'] = lista_posts
return static_page.generate_page()
@app.route("/posts/recientes", defaults={'pagina':0})
@app.route("/posts/recientes/<int:pagina>")
def posts_recientes(pagina):
""" muestra una lista de los posts mas recientes
TODO: terminar
"""
lista_posts, total_posts = noticias_recientes(max_caracteres=368,
pagina=pagina)
static_page = Page("recientes")
static_page.contexto['lista_posts_recientes'] = lista_posts
static_page.contexto['total_posts'] = total_posts
static_page.contexto['pagina_actual'] = pagina
#return (str(lista_posts))
return static_page.generate_page()
@app.route("/contacto", methods=['GET'])
def contacto():
tupla_captcha = captcha_pregunta_opciones_random()
if tupla_captcha is None:
return ("<br>Parece un error interno!</br>")
pregunta = tupla_captcha[0]
opciones = tupla_captcha[1]
static_page = Page("contacto")
static_page.contexto['pregunta'] = pregunta
static_page.contexto['opciones'] = opciones
return static_page.generate_page()
@app.route("/contactoe", methods=['POST'])
def comprobar_mensaje():
""" Comprueba que el mensaje enviado por la caja de texto sea valido
y si lo es, guarda un archivo de texto con los detalles"""
errors = []
if request.method == "POST":
# comprobando validez
nombre = request.form["nombre"]
dir_respuesta = request.form['dir_respuesta']
mensaje = request.form['mensaje']
pregunta = request.form['pregunta']
respuesta = request.form['respuesta']
if len(mensaje) < 2 or mensaje.startswith(" "):
errors.append("Mensaje invalido")
if not captcha_comprobar_respuesta(pregunta, respuesta):
errors.append("Captcha invalido")
if len(errors) > 0:
return str(errors)
# guardando texto
texto = "Remitente: "+nombre
texto += "\nResponder_a: "+dir_respuesta
texto += "\n--- mensaje ---\n"
texto += mensaje
# TODO: cambiar a direccion especificada en archivo de configuracion
dt = datetime.datetime.now()
nombre = "m_"+str(dt.day)+"_"+str(dt.month)+\
"_"+str(dt.year)+"-"+str(dt.hour)+\
"-"+str(dt.minute)+"-"+str(dt.second)
with open(os.path.join("fbs",nombre), "wb") as f:
f.write(texto.encode("utf-8"))
return redirect("/mensaje_enviado", code=302)
@app.route("/mensaje_enviado")
def mensaje_enviado():
static_page = Page("mensaje_enviado")
return static_page.generate_page()
@app.route("/rss")
def rss_feed():
"""Genera la cadena rss con las 15 ultimas noticias del sitio
TODO: Agregar mecenismo para no generar los rss feeds y solo
devolver el archivo rss.xml generado anteriormente. Esto
quiere decir solamente generar el rss_feed cuando se haya hecho
un actualizacion en los posts mas reciente que la ultima vez
que se genero el rss_feed
"""
#return str(rss_ultimos_posts_jinja())
return render_template("rss.html",
contents = rss_ultimos_posts_jinja())
#**vars(self)
#)
##### specialized pages
@app.route("/source")
def source():
"""Display source files used to render a page"""
source_page = Page('source', title = "view the source code",
#heading = "Ver el código fuente",
heading = "Ver el codigo fuente",
internal_css = get_pygments_css())
page = request.args.get('page')
# get source for markdown if any. 404's for non-existant markdown
# unless special page eg source
pagesrc = source_page.get_page_src(page, 'src', 'md')
special_pages = ['source', 'unit-tests', '404']
if not page in special_pages and pagesrc is None:
abort(404)
# set enable_unit_tests to true in config.json to allow
# unit tests to be run through the source page
if app.config['enable_unit_tests']:
contents = '''<p><a href="/unit-tests" class="button">Run unit tests
</a></p>'''
# render tests.py if needed
if page == 'unit-tests':
contents += heading('tests.py', 2)
contents += render_pygments('tests.py', 'python')
else:
contents = ''
# render views.py
contents += heading('views.py', 2)
contents += render_pygments(source_page.get_page_src('views.py'),
'python')
# render markdown if present
if pagesrc:
contents += heading(os.path.basename(pagesrc), 2)
contents += render_pygments(pagesrc, 'markdown')
# render jinja templates
contents += heading('base.html', 2)
contents += render_pygments(
source_page.get_page_src('base.html', 'templates'), 'html')
template = source_page.get_template(page)
contents += heading(template, 2)
contents += render_pygments(
source_page.get_page_src(template, 'templates'), 'html')
return source_page.generate_page(contents)
# @app.route("/unit-tests")
# def unit_tests():
# """display results of unit tests"""
# unittests = Page('unit-tests', heading = "Test Results",
# internal_css = get_pygments_css())
# # exec unit tests in subprocess, capturing stderr
# capture = subprocess.Popen(["python", "tests.py"],
# stdout = subprocess.PIPE, stderr = subprocess.PIPE)
# output = capture.communicate()
# results = output[1]
# contents = '''<p>
# <a href="/unit-tests" class="button">Run unit tests</a>
# </p><br>\n
# <div class="output" style="background-color:'''
# if 'OK' in results:
# color = "#ddffdd"
# result = "TESTS PASSED"
# else:
# color = "#ffaaaa"
# result = "TESTS FAILING"
# contents += ('''%s">\n<strong>%s</strong>\n<pre>%s</pre>\n</div>\n'''
# % (color, result, results))
# # render test.py
# contents += heading('tests.py', 2)
# contents += render_pygments('tests.py', 'python')
# return unittests.generate_page(contents)
En este post veremos como publicar un paquete de software al repositorio pypi.python.org (Python Package Index), así estará disponible públicamente y para que cualquiera lo instale sólo hará falta usar `pip install nombre_del_paquete`.
Si tienes un módulo o paquete python que te ha servido mucho, lo hayas escrito tu o con amigos, puedes compartirlo en el repositorio [https://pypi.python.org](https://pypi.python.org) y así le servirá a cualquiera que lo necesite. En este post veremos el proceso paso a paso, empecemos.
## ¿ Qué es pypi.python.org ? ##
Pypi.python.org es un repositorio público que alberga software escrito en el lenguaje de programación python. A esta fecha hay más de 129000 paquetes disponibles.
Este repositorio facilita enormente en el desarrollo de software, por que para incluir uno o varios módulos, sólo hace falta utilizar [pip](https://pip.pypa.io/en/stable/) en un entorno de sistema o virtual para un programa que estemos escribiendo.
Por ejemplo para este sitio web, utilizo el [micro-framework Flask](http://flask.pocoo.org/) y otros paquetes python, de **no ser por pip** para instalarlo tendría que posiblemente descargarme el código fuente y hacer una serie de pasos manuales para que esta página web pueda utilizar sus funcionalidades. Pero gracias a pip y el repositorio pypi.python.org para instalar flask se puede hacer comdamente en un entorno virtual:
:::bash
mkdir nombre_proyecto
cd nombre_proyecto
virtualenv venv
source venv/bin/activate
# con la siguiente línea se descargará e instalará todo el framework Flask
# en el entorno virtual de nuestra computadora (la carpeta venv)
# y estará listo para usarse.
pip install flask
## Escribiendo el paquete o módulo python ##
Este el paso más largo e importante, una vez tengamos el módulo python funcional es cuando debemos pensar en si lo vamos a compartir con el resto del mundo. Para este ejemplo he escrito un pequeño paquete en python llamado simplemotds.
### Rápidamente sobre simplemotds ###
El paquete [simplemotds](https://pypi.python.org/pypi/simplemotds) ayuda a obtener un mensage del día y que cambie automáticamente, de ahí el nombre simple motds (motd = *Message Of The Day*).
Básicamente lo que hace es leer un directorio con archivos donde cada uno tiene un mensaje o consejo del día, al llamar al método `getMotdContent()`, este devuelve el contenido del archivo seleccionado para el día de hoy. Al día siguiente este mensaje cambiará automáticamente.
Adicionalmente a este módulo se le puede configurar fácilmente para que el mensaje cambie por ejemplo al cabo de un mes, una semana, una hora o hasta un minuto. La selección del mensaje tambíen puede cambiarse.
Para más detalles puedes ver el [código fuente de python-simplemotds](https://notabug.org/strysg/python-simplemotds) y una demostración de cómo funciona se la ve en esta misma página que muestra los consejos para cada día utilizando simplemotds.
## La estructura necesaria para subir el paquete python ##
Hay un buen tutorial para empaquetar software python [ [1] ](http://www.diveintopython3.net/packaging.html), para el ejemplo de simplemotds, tenemos la siguiente estrucutra:
:::bash
├── LICENSE.txt
├── MANIFEST.in
├── README.md
├── setup.cfg
├── setup.py
└── simplemotds # esta es la carpeta con el software en si
├── config.json
├── __init__.py
├── messages
│ ├── m1.html
│ ├── m2.html
│ └── m3.html
└── simplemotds.py
Independientemente del módulo python que desarrollemos, son obligatorios los archivos: `LICENSE.txt`, `MANIFEST.in`, `README` y `setup.py`. Estos son la meta-data que pypi.python.org usará para identificar nuestro paquete y deben estar **un directorio arriba de nuestro módulo**. Algo que difiere es que el archivo README debería estar en formato rst según la documentación oficial de python [ [2] ](https://packaging.python.org/tutorials/distributing-packages/#readme-rst).
El paquete simplemotds es tan simple que sólo tiene un archivo de código fuente `simplemotds.py` aunque también tiene otros archivos como `config.json` y un directorio `messages` donde hay unos mensajes de prueba, por supuesto para que python interprete el directorio como un módulo está el archivo `__init__.py`.
### setup.py ###
Este archivo es muy importante y se utiliza para configurar la instalación del paquete, para nuestro caso su contenido es:
:::python
from setuptools import setup, find_packages
setup(
name = 'simplemotds',
packages = ['simplemotds'],
include_package_data=True, # muy importante para que se incluyan archivos sin extension .py
version = '0.23',
description = 'Configurable package that returns the message of the day (motd)',
author='Rodrigo Garcia',
author_email="strysg@riseup.net",
license="GPLv3",
url="https://github.com/strymsg/python-simplemotds",
classifiers = ["Programming Language :: Python :: 3",\
"License :: OSI Approved :: GNU General Public License v3 (GPLv3)",\
"Development Status :: 4 - Beta", "Intended Audience :: Developers", \
"Operating System :: OS Independent"],
)
Para empaquetar este proyecto usaremos la biblioteca [setuptools](https://pypi.python.org/pypi/setuptools) y es mejor tenerla instalada en el sistema en su versión más reciente, si usamos una distribución de GNU linux basada en debian podríamos instalarlo con `sudo apt install python-setuptools`, pero puede que el paquete debian no sea actualizado, en todo caso podríamos utilizar pip.
pip install -U pip setuptools # que instalará setuptools en el sistema
* `name`: Es el nombre del paquete.
* `packages`: Es la lista de paquetes que contiene nuestro módulo, para el caso de simplemotds sólo existe un paquete que se llama simplemotds.
* `include_package_data`: Por defecto setuptools sólo empaqueta archivos con estensión .py, en este cas se utiliza un archivo de configuración `config.json` y varos archivos de prueba `.html`, esta variable debe ser `True` para que sean incluidos.
* `version`: La versión del paquete (debemos cambiarla cada que necesitemos actualizar.
* `description`: Una descripción corta
* `author` y `author_email`
* `license`: Obligatorio especificar una licencia de software libre o al menos código abierto, puedes revisar [esta guía](https://hipertextual.com/archivo/2014/05/como-elegir-licencias-open-source/) si no sabes cuál escoger. `url`: Sitio web donde se puede revisar el proyecto.
* `calssifiers`: Sirven para clasificar apropiadamente tu paquete en pypi.python.org [ [1] ](http://www.diveintopython3.net/packaging.html#trove).
Hay más opciones [ [2] ](https://packaging.python.org/tutorials/distributing-packages/#setup-args), [ [3] ](https://setuptools.readthedocs.io/en/latest/setuptools.html).
### MANIFEST.in ###
Este archivo es para especificar archivos adicionales [ [1] ](http://www.diveintopython3.net/packaging.html#manifest), para este caso queremos incluir el archivo `config.json` y los mensajes de prueba dentro el directorio `messages/`.
recursive-include simplemotds config.json
recursive-include simplemotds/messages *.html
Con esta configuración básica tenemos lo necesario para empaquetar el software python y luego subirlo.
## Empaquetando ##
Para empaquetar ejecutamos en el directorio raíz del proyecto:
python setup.py sdist
Lo que ocurrirá será que se interpreta `setup.py` se aplican las configuraciones y se leerá el archivo `MANIFEST.in` para incluir archivos adicionales. Una vez se termina, todo el módulo python quedará dentro un archivo `.tar.gz` **dentro el directorio** `dist`/ que setup creará.
En el caso de simplemotds se ha empaquetado en `simplemotds-0.23.tar.gz`, deberíamos revisar en el archivo comprimido si esta todo lo que se requiere.
## Subiendo el archivo empaquetado ##
Primero es necesario que tengamos una cuenta de usuario en pypi.python.org, [afortunadamente el registro es libre](https://pypi.python.org/pypi?%3Aaction=register_form).
### .pypirc (opcional) ###
Una vez hayamos creado la cuenta para facilitar el proceso de autenticación con pypi.python.org, podemos incluir las credenciales de la cuenta que tengamos en pypi.python.org en un archivo. Usualmente el archivo debería estar en el directorio HOME del usuario actual es decir `$HOME/.pypirc`, luego en ese archivo poner las credenciales de la siguiente manera:
[pypi]
username = <usuario>
password = <password>
Para que el archvivo este más seguro:
:::bash
chmod 600 $HOME/.pypirc
Una nota sobre passwords [ [4] ](http://peterdowns.com/posts/first-time-with-pypi.html).
### Instalando twine para facilitar la subida del paquete ###
Para subir el paquete he utilizado la herramienta [twine](https://github.com/pypa/twine) que ayuda a interactuar con [PyPI](https://packaging.python.org/glossary/#term-python-package-index-pypii) enviando las credenciales, y subiendo el paquete que preparamos antes al repositorio PyPI.
Twine no viene por defecto con python y por eso hay que instalarlo en el sistema, usualmente se debería poder con `sudo apt install twine`, pero en el caso de mi distribución la versión de twine estaba muy desactualizada y al tratar de usarlo retornaba error 401 [ [5] ](https://stackoverflow.com/questions/45207128/failed-to-upload-packages-to-pypi-410-gone).
Para solucionarlo he tenido que desinstalar twine del sistema e instalar la última versión estable con pip:
pip install -U pip setuptools twine
Luego confirmar la versión de twine con `twine --version` que debería devolver 1.9.1 o superior
**Nota:** En mi sistema (basado en ubuntu 16) hubo el problema que al desinstalar twine con `sudo apt-get purge twine` e instalarlo con pip, la referencia a la nueva versión de twine no se resolvía correctamente, entonces uso `whereis twine` que me dice que el binario de twine está en `/usr/local/bin/twine`. Para llamar al twine correcto uso `/usr/local/bin/twine` seguido de las opciones.
### Subiendo el paquete ###
Ahora usamos:
twine upload dist/*
Que subirá a pypi.python.org lo que tengamos en el directorio dist/ que es donde quedó empaquetado nuestro paquete python.
Una vez se haga esto correctamente deberíamos comprobar ingresando a [https://pypi.python.org](https://pypi.python.org) y buscando por el nombre del paquete que hemos subido recién.
### Habilitando para que esté disponible usando pip ###
En pypi.python.org es necesario indicar explícitamente que versión de nuestro paquete estará disponible públicamente. Par eso debemos ingresar con nuestra cuenta de usuario al sitio y revisar la página relacionada a nuestro paquete, luego **liberarla** manualmente. Para el caso de simplemotds, la imagen siguiente muestra como hacerlo.
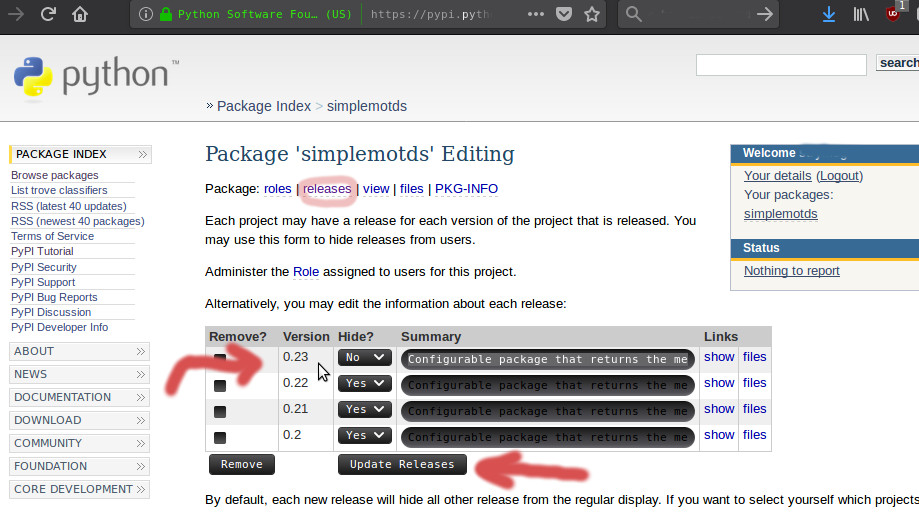
Como se ve, se listan las versiones que he subido de simplemotds, finalmente para **liberar** la última versión solo se hace click en *Update Releases*.
Bien, ahora si desde cualquier proyecto utilizamos
pip search simplemotds
Nos devuelve:
simplemotds (0.23) - Configurable package that returns the message of the day
(motd)
Esto indica que el paquete simplemotds se ha subido correctamente al índice de paquetes python https://pypi.python.org y por eso para cualquier proyecto lo podemos instalar con:
pip install simplemotds
### Conclusión ###
Puede que subir un paquete la primera vez sea algo tedioso, sin embargo como vimos existen las herramientas necesarias para hacerlo bien y facilitar el proceso.
Si tienes un pedazo de código tuyo escrito en python que funcione bien como módulo, piensa en compartirlo con todo el mundo o también si te gusta un módulo de python en especial haz tu aporte para mejorarlo y que otr@s se beneficien ;)
## Referencias
1. [Guía detallada para empaquetar bibliotecas python y subirlas a pypi.org](http://www.diveintopython3.net/packaging.html#manifest)
2. [Documentación oficial de python para empaquetar y distribuir paquetes](https://packaging.python.org/tutorials/distributing-packages/)
3. [Documentación de setuptools](https://setuptools.readthedocs.io/en/latest/setuptools.html)
4. [Post rápido para subir paquetes (desactualizado pero útil como referencia)](http://peterdowns.com/posts/first-time-with-pypi.html).
5. [Error 401 al enviar paquetes (hilo en stackoverflow)](https://stackoverflow.com/questions/45207128/failed-to-upload-packages-to-pypi-410-gone)


 Posts
Posts
 Categorías
Categorías
 Fotos
Fotos
 Acerca de mi
Acerca de mi
 Contacto
Contacto