# -*- coding: utf-8 -*-
"""
Monomotapa - A Micro CMS
Copyright (C) 2014, Paul Munday.
PO Box 28228, Portland, OR, USA 97228
paul at paulmunday.net
Modificado por: Rodrigo Garcia 2017 https://rmgss.net/contacto
This program is free software: you can redistribute it and/or modify
it under the terms of the GNU Affero Public License as published by
the Free Software Foundation, either version 3 of the License, or
(at your option) any later version.
This program is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU General Public License for more details.
You should have received a copy of the GNU Affero General Public License
along with this program. If not, see <http://www.gnu.org/licenses/>.
Monomotapa:
a city whose inhabitants are bounded by deep feelings of friendship,
so that they intuit one another's most secret needs and desire.
For instance, if one dreams that his friend is sad, the friend will
perceive the distress and rush to the sleepers rescue.
(Jean de La Fontaine, *Fables choisies, mises en vers*, VIII:11 Paris,
2nd ed., 1678-9)
cited in :
Alberto Manguel and Gianni Guadalupi, *The Dictionary of Imaginary Places*,
Bloomsbury, London, 1999.
A micro cms written using the Flask microframework, orignally to manage my
personal site. It is designed so that publishing a page requires no more than
dropping a markdown page in the appropriate directory (though you need to edit
a json file if you want it to appear in the top navigation).
It can also display its own source code and run its own unit tests.
The name 'monomotapa' was chosen more or less at random (it shares an initial
with me) as I didn't want to name it after the site and be typing import
paulmunday, or something similar, as that would be strange.
"""
from flask import render_template, abort, Markup, escape, request #, make_response
from flask import redirect
from werkzeug.utils import secure_filename
from pygments import highlight
from pygments.lexers import PythonLexer, HtmlDjangoLexer, TextLexer
from pygments.formatters import HtmlFormatter
import markdown
from time import gmtime, strptime, strftime, ctime, mktime
import datetime
import os.path
import os
import subprocess
import json
import traceback
from collections import OrderedDict
from simplemotds import SimpleMotd
from monomotapa import app
from monomotapa.config import ConfigError
from monomotapa.utils import captcha_comprobar_respuesta, captcha_pregunta_opciones_random
from monomotapa.utils import categorias_de_post, categoriasDePost, categoriasList, cabezaPost
from monomotapa.utils import titulo_legible, metaTagsAutomaticos
from markdown.extensions.toc import TocExtension
json_pattrs = {}
with open(os.path.join('monomotapa','pages.json'), 'r') as pagefile:
json_pattrs = json.load(pagefile)
simplemotd = SimpleMotd("config_simplemotds.json")
class MonomotapaError(Exception):
"""create classs for own errors"""
pass
def get_page_attributes(jsonfile):
"""Returns dictionary of page_attributes.
Defines additional static page attributes loaded from json file.
N.B. static pages do not need to have attributes defined there,
it is sufficient to have a page.md in src for each /page
possible values are src (name of markdown file to be rendered)
heading, title, and trusted (i.e. allow embeded html in markdown)"""
try:
with open(src_file(jsonfile), 'r') as pagesfile:
page_attributes = json.load(pagesfile)
except IOError:
page_attributes = []
return page_attributes
def get_page_attribute(attr_src, page, attribute):
"""returns attribute of page if it exists, else None.
attr_src = dictionary(from get_page_attributes)"""
if page in attr_src and attribute in attr_src[page]:
return attr_src[page][attribute]
else:
return None
# Navigation
def top_navigation(page):
"""Generates navigation as an OrderedDict from navigation.json.
Navigation.json consists of a json array(list) "nav_order"
containing the names of the top navigation elements and
a json object(dict) called "nav_elements"
if a page is to show up in the top navigation
there must be an entry present in nav_order but there need not
be one in nav_elements. However if there is the key must be the same.
Possible values for nav_elements are link_text, url and urlfor
The name from nav_order will be used to set the link text,
unless link_text is present in nav_elements.
url and urlfor are optional, however if ommited the url wil be
generated in the navigation by url_for('staticpage', page=[key])
equivalent to @app.route"/page"; def page())
which may not be correct. If a url is supplied it will be used
otherwise if urlfor is supplied it the url will be
generated with url_for(urlfor). url takes precendence so it makes
no sense to supply both.
Web Sign-in is supported by adding a "rel": "me" attribute.
"""
with open(src_file('navigation.json'), 'r') as navfile:
navigation = json.load(navfile)
base_nav = OrderedDict({})
for key in navigation["nav_order"]:
nav = {}
nav['base'] = key
nav['link_text'] = key
if key in navigation["nav_elements"]:
elements = navigation["nav_elements"][key]
nav.update(elements)
base_nav[key] = nav
return {'navigation' : base_nav, 'page' : page}
# For pages
class Page:
"""Generates pages as objects"""
def __init__(self, page, **kwargs):
"""Define attributes for pages (if present).
Sets self.name, self.title, self.heading, self.trusted etc
This is done through indirection so we can update the defaults
(defined in the 'attributes' dictionary) with values from config.json
or pages.json easily without lots of if else statements.
If css is supplied it will overide any default css. To add additional
style sheets on a per page basis specifiy them in pages.json.
The same also applies with hlinks.
css is used to set locally hosted stylesheets only. To specify
external stylesheets use hlinks: in config.json for
default values that will apply on all pages unless overidden, set here
to override the default. Set in pages.json to add after default.
"""
# set default attributes
self.page = page.rstrip('/')
self.defaults = get_page_attributes('defaults.json')
self.pages = get_page_attributes('pages.json')
self.url_base = self.defaults['url_base']
title = titulo_legible(page.lower())
heading = titulo_legible(page.capitalize())
self.categorias = categoriasDePost(self.page)
self.exclude_toc = True
try:
self.default_template = self.defaults['template']
except KeyError:
raise ConfigError('template not found in default.json')
# will become self.name, self.title, self.heading,
# self.footer, self.internal_css, self.trusted
attributes = {'name' : self.page, 'title' : title,
'navigation' : top_navigation(self.page),
'heading' : heading, 'footer' : None,
'css' : None , 'hlinks' :None, 'internal_css' : None,
'trusted': False,
'preview-chars': 250,
}
# contexto extra TODO: revisar otra forma de incluir un contexto
self.contexto = {}
self.contexto['consejo'] = simplemotd.getMotdContent()
# set from defaults
attributes.update(self.defaults)
# override with kwargs
attributes.update(kwargs)
# override attributes if set in pages.json
if page in self.pages:
attributes.update(self.pages[page])
# set attributes (as self.name etc) using indirection
for attribute, value in attributes.items():
# print('attribute', attribute, '=-==>', value)
setattr(self, attribute, value)
# meta tags
try:
self.pages[self.page]['title'] = attributes['title']
self.pages[self.page]['url_base'] = self.url_base
metaTags = metaTagsAutomaticos(self.page, self.pages.get(self.page, {}))
self.meta = metaTags
# for key, value in self.pages[self.page].items():
# print(' ', key, ' = ', value)
except Exception as e:
tb = traceback.format_exc()
print('Error assigning meta:', str(e), '\n', str(tb))
# reset these as we want to append rather than overwrite if supplied
if 'css' in kwargs:
self.css = kwargs['css']
elif 'css' in self.defaults:
self.css = self.defaults['css']
if 'hlinks' in kwargs:
self.hlinks = kwargs['hlinks']
elif 'hlinks' in self.defaults:
self.hlinks = self.defaults['hlinks']
# append hlinks and css from pages.json rather than overwriting
# if css or hlinks are not supplied they are set to default
if page in self.pages:
if 'css' in self.pages[page]:
self.css = self.css + self.pages[page]['css']
if 'hlinks' in self.pages[page]:
self.hlinks = self.hlinks + self.pages[page]['hlinks']
# append heading to default if set in config
self.title = self.title + app.config.get('default_title', '')
def _get_markdown(self):
"""returns rendered markdown or 404 if source does not exist"""
src = self.get_page_src(self.page, 'src', 'md')
if src is None:
abort(404)
else:
return render_markdown(src, self.trusted)
def get_page_src(self, page, directory=None, ext=None):
""""return path of file (used to generate page) if it exists,
or return none.
Also returns the template used to render that page, defaults
to static.html.
It will optionally add an extension, to allow
specifiying pages by route."""
# is it stored in a config
pagename = get_page_attribute(self.pages, page, 'src')
if not pagename:
pagename = page + get_extension(ext)
if os.path.exists(src_file(pagename , directory)):
return src_file(pagename, directory)
else:
return None
def get_template(self, page):
"""returns the template for the page"""
pagetemplate = get_page_attribute(self.pages, page, 'template')
if not pagetemplate:
pagetemplate = self.default_template
if os.path.exists(src_file(pagetemplate , 'templates')):
return pagetemplate
else:
raise MonomotapaError("Template: %s not found" % pagetemplate)
def generate_page(self, contents=None):
"""return a page generator function.
For static pages written in Markdown under src/.
contents are automatically rendered.
N.B. See note above in about headers"""
toc = '' # table of contents
if not contents:
contents, toc = self._get_markdown()
# print('////', toc)
template = self.get_template(self.page)
# print('......................')
# def mos(**kwargs):
# for k in kwargs:
# print(k, end=',')
# mos(**vars(self))
return render_template(template,
contents = Markup(contents),
toc=toc,
**vars(self))
# helper functions
def src_file(name, directory=None):
"""return potential path to file in this app"""
if not directory:
return os.path.join( 'monomotapa', name)
else:
return os.path.join('monomotapa', directory, name)
def get_extension(ext):
'''constructs extension, adding or stripping leading . as needed.
Return null string for None'''
if ext is None:
return ''
elif ext[0] == '.':
return ext
else:
return '.%s' % ext
def render_markdown(srcfile, trusted=False):
""" Returns markdown file rendered as html and the table of contents as html.
Defaults to untrusted:
html characters (and character entities) are escaped
so will not be rendered. This departs from markdown spec
which allows embedded html."""
try:
with open(srcfile, 'r') as f:
src = f.read()
md = markdown.Markdown(extensions=['toc', 'codehilite'])
md.convert(src)
toc = md.toc
if trusted == True:
content = markdown.markdown(src,
extensions=['codehilite',
TocExtension(permalink=True)])
else:
content = markdown.markdown(escape(src),
extensions=['codehilite',
TocExtension(permalink=True)])
return content, toc
except IOError:
return None
def render_pygments(srcfile, lexer_type):
"""returns src(file) marked up with pygments"""
if lexer_type == 'python':
with open(srcfile, 'r') as f:
src = f.read()
contents = highlight(src, PythonLexer(), HtmlFormatter())
elif lexer_type == 'html':
with open(srcfile, 'r') as f:
src = f.read()
contents = highlight(src, HtmlDjangoLexer(), HtmlFormatter())
# default to TextLexer for everything else
else:
with open(srcfile, 'r') as f:
src = f.read()
contents = highlight(src, TextLexer(), HtmlFormatter())
return contents
def get_pygments_css(style=None):
"""returns css for pygments, use as internal_css"""
if style is None:
style = 'friendly'
return HtmlFormatter(style=style).get_style_defs('.highlight')
def heading(text, level):
"""return as html heading at h[level]"""
heading_level = 'h%s' % str(level)
return '\n<%s>%s</%s>\n' % (heading_level, text, heading_level)
def posts_list(ordenar_por_fecha=True, ordenar_por_nombre=False):
'''Retorna una lista con los nombres de archivos con extension .md
dentro de la cappeta src/posts, por defecto retorna una lista con
la tupla (nombre_archivo, fecha_subida)'''
lista_posts = []
lp = []
if ordenar_por_nombre:
try:
ow = os.walk("monomotapa/src/posts")
p , directorios , archs = ow.__next__()
except OSError:
print ("[posts] - Error: Cant' os.walk() on monomotapa/src/posts except OSError")
else:
for arch in archs:
if arch.endswith(".md") and not arch.startswith("#") \
and not arch.startswith("~") and not arch.startswith("."):
lista_posts.append(arch)
lista_posts.sort()
return lista_posts
if ordenar_por_fecha:
try:
ow = os.walk("monomotapa/src/posts")
p,d,files=ow.__next__()
except OSError:
print ("[posts] - Error: Can't os.walk() on monomotapa/src/posts except OSError.")
else:
for f in files:
nombre_con_ruta = os.path.join("monomotapa/src/posts", f)
if not f.endswith("~") and not f.startswith("#") and not f.startswith("."):
secs_modificacion = SecsModificacionPostDesdeJson(f, json_pattrs)
ultima_modificacion = os.path.getmtime(nombre_con_ruta)
lp.append((secs_modificacion, ultima_modificacion, f))
lp.sort()
lp.reverse()
# colocando fecha en formato
for tupla in lp:
#fecha = strftime("a, %d %b %Y %H:%M:%S", ctime(tupla[0]))
cfecha = ctime(tupla[1])
#fecha = strptime("%a %b %d %H:%M:%S %Y", cfecha)
lista_posts.append((cfecha, tupla[2]))
return lista_posts
def categorias_list(categoria=None):
""" Rotorna una lista con los nombres de posts y el numero de posts que
pertenecen a la categoria dada o a cada categoria.
Las categorias se obtienen analizando la primera linea de cada archivo .md
an la carpeta donde se almacenan los posts.
Si no se especifica `categoria' cada elemento de la lista devuelta es:
(nombre_categoria, numero_posts, [nombres_posts])
si se especifica `categoria' cada elemento de la lista devuelta es:
(numero_posts, [nombres_posts]
"""
lista_posts = posts_list(ordenar_por_nombre=True)
lista_categorias = []
if categoria is not None:
c = 0
posts = []
for post in lista_posts:
nombre_arch = "monomotapa/src/posts/"+post
with open(nombre_arch, 'r') as file:
linea = file.readline().decode("utf-8")
lc = linea.split("[#")[1:]
for cad in lc:
cat = cad.split("]")[0]
if cat == categoria:
c += 1
posts.append(post)
lista_categorias = (c, posts)
return lista_categorias
dic_categorias = {}
for post in lista_posts:
nombre_arch = "monomotapa/src/posts/"+post
with open(nombre_arch, 'r') as fil:
linea = fil.readline().decode('utf-8') # primera linea
# extrayendo las categorias y registrando sus ocurrencias
# ejemplo: catgorías: [#reflexión](categoria/reflexion) [#navidad](categoria/navidad)
# extrae: [reflexion,navidad]
lc = linea.split("[#")[1:]
for cad in lc:
cat = cad.split("]")[0]
if cat not in dic_categorias:
dic_categorias[cat] = (1,[post]) # nuevo registro por categoria
else:
tupla = dic_categorias[cat]
c = tupla[0] + 1
lis = tupla[1]
if post not in lis:
lis.append(post)
dic_categorias[cat] = (c, lis)
# convirtiendo en lista
for k, v in dic_categorias.iteritems():
lista_categorias.append((k,v[0],v[1]))
lista_categorias.sort()
lista_categorias.reverse()
return lista_categorias
def cabeza_post(archivo , max_caracteres=250, categorias=True):
""" Devuelve las primeras lineas de una archivo de post (en formato markdown)
con un maximo numero de caracteres excluyendo titulos en la cabeza devuelta.
Si se especifica `categorias' en True
Se devuelve una lista de la forma:
(cabeza_post, categorias)
donde categorias son cadenas con los nombres de las categorias a la que
pertenece el post
"""
cabeza_post = ""
cats = []
with open(os.path.join("monomotapa/src/posts",archivo)) as file:
# analizando si hay titulos al principio
# Se su pone que la primera linea es de categorias
for linea in file.readlines():
linea = linea.decode("utf-8")
if linea.startswith(u"categorías:") or linea.startswith("categorias"):
if categorias:
cats = categoriasDePost(archivo)
#cats = categorias_de_post(archivo)
else:
# evitando h1, h2
if linea.startswith("##") or linea.startswith("#"):
cabeza_post += " "
else:
cabeza_post += linea
if len(cabeza_post) >= max_caracteres:
break
cabeza_post = cabeza_post[0:max_caracteres-1]
if categorias:
return (cabeza_post, cats)
return cabeza_post
def ultima_modificacion_archivo(archivo):
""" Retorna una cadena indicando la fecha de ultima modificacion del
`archivo' dado, se asume que `archivo' esta dentro la carpeta "monomotapa/src"
Retorna una cadena vacia en caso de no poder abrir `archivo'
"""
try:
ts = strptime(ctime(os.path.getmtime("monomotapa/src/"+archivo+".md")))
return strftime("%d %B %Y", ts)
except OSError:
return ""
def SecsModificacionPostDesdeJson(archivo, dict_json):
''' dado el post con nombre 'archivo' busca en 'dict_json' el
attribute 'date' y luego obtiene los segundos totales desde
esa fecha.
Si no encuentra 'date' para 'archivo' en 'dict.json'
retorna los segundos totales desde la ultima modificacion
del archivo de post directamente (usa os.path.getmtime)
'''
nombre = archivo.split('.md')[0] # no contar extension .md
nombre_con_ruta = os.path.join("monomotapa/src/posts", archivo)
date_str = dict_json.get('posts/'+nombre, {}).\
get('attributes',{}).\
get('date','')
if date_str == '':
# el post no tiene "date" en pages.json
return os.path.getmtime(nombre_con_ruta)
else:
time_struct = strptime(date_str, '%Y-%m-%d')
dt = datetime.datetime.fromtimestamp(mktime(time_struct))
return (dt - datetime.datetime(1970,1,1)).total_seconds()
def noticias_recientes(cantidad=11, max_caracteres=250,
categoria=None, pagina=0):
'''Devuelve una lista con hasta `cantidad' de posts mas recientes,
un maximo de `max_caracteres' de caracteres del principio del post y
el numero total de posts encontrados
Si se proporciona `categoria' devuelve la lista de posts solamente
pertenecientes esa categoria.
Si `pagina' > 0 se devulve hasta `cantidad' numero de posts en el
rango de [ cantidad*pagina : cantidad*(pagina+1)]
Cada elemento de la lista devuelta contiene:
(nombre_post, ultima_modificacion, cabeza_archivo, categorias)
Al final se retorna: (lista_posts, numero_de_posts)
'''
lista_posts = []
lp = []
num_posts = 0
posts_en_categoria = []
if categoria is not None:
#posts_en_categoria = categorias_list(categoria)[1]
posts_en_categoria = categoriasList(categoria)[1]
# categoria especial fotos
if categoria == "fotos":
l = []
for p in posts_en_categoria:
l.append(p + '.md')
posts_en_categoria = l
try:
ow = os.walk("monomotapa/src/posts")
p,d,files = ow.__next__()
#p,d,files=ow.next()
except OSError:
print ("[posts] - Error: Can't os.walk() on monomotapa/src/posts except OSError.")
else:
for f in files:
nombre_con_ruta = os.path.join("monomotapa/src/posts", f)
if not f.endswith("~") and not f.startswith("#") and not f.startswith("."):
secs_modificacion = SecsModificacionPostDesdeJson(f, json_pattrs)
ultima_modificacion = os.path.getmtime(nombre_con_ruta)
previewChars = json_pattrs.get('posts/'+f[:-3], {}).\
get('attributes', {}).\
get('preview-chars', max_caracteres)
if categoria is not None:
if f in posts_en_categoria:
lp.append((secs_modificacion,
ultima_modificacion,
previewChars,
f))
num_posts += 1
else:
lp.append((secs_modificacion,
ultima_modificacion,
previewChars,
f))
num_posts += 1
lp.sort()
lp.reverse()
# seleccionado por paginas
lp = lp[cantidad*pagina : cantidad*(pagina+1)]
# colocando fecha en formato
for tupla in lp:
cfecha = ctime(tupla[1])
nombre_post = tupla[3].split(os.sep)[-1]
previewChars = tupla[2]
#contenido = cabeza_post(tupla[3], max_caracteres=previewChars)[0]
#categorias = cabeza_post(tupla[3], max_caracteres=previewChars)[1]
contenido = cabezaPost(tupla[3], max_caracteres=previewChars)[0]
categorias = cabezaPost(tupla[3], max_caracteres=previewChars)[1]
cabeza_archivo = markdown.markdown(escape(contenido + ' ...'))
lista_posts.append((nombre_post[:-3], cfecha, \
cabeza_archivo, categorias))
return (lista_posts, num_posts)
def noticias_relacionadas(cantidad=5, nombre=None):
"""Retorna una lista con posts relacionadas, es decir que tienen son de las
mismas categorias que el post con nombre `nombre'.
Cada elemento de la lista de posts contiene el nombre del post
"""
#categorias = categorias_de_post(nombre) ## TODO: corregir categorias de post
categorias = categoriasDePost(nombre)
numero = 0
if categorias is None:
return None
posts = []
for categoria in categorias:
#lista = categorias_list(categoria)[1] # nombres de posts
lista = categoriasList(categoria)[1]
numero += len(lista)
for nombre_post in lista:
if nombre_post + '.md' != nombre:
posts.append(nombre_post)
if numero >= cantidad:
return posts
return posts
def rss_ultimos_posts_jinja(cantidad=15):
"""Retorna una lista de los ultimos posts preparados para
ser renderizados (usando jinja) como un feed rss
Examina cada post del mas reciente al menos reciente, en
total `cantidad' posts. Por cada post devuelve:
id: id which identifies the entry using a
universally unique and permanent URI
author: Get or set autor data. An author element is a dict containing a
name, an email adress and a uri.
category: A categories has the following fields:
- *term* identifies the category
- *scheme* identifies the categorization scheme via a URI.
- *label* provides a human-readable label for display
comments: Get or set the the value of comments which is the url of the
comments page for the item.
content: Get or set the cntent of the entry which contains or links to the
complete content of the entry.
description(no contiene): Get or set the description value which is the item synopsis.
Description is an RSS only element.
link: Get or set link data. An link element is a dict with the fields
href, rel, type, hreflang, title, and length. Href is mandatory for
ATOM.
pubdate(no contiene): Get or set the pubDate of the entry which indicates when the entry
was published.
title: the title value of the entry. It should contain a human
readable title for the entry.
updated: the updated value which indicates the last time the entry
was modified in a significant way.
"""
lista_posts = []
lp = []
num_posts = 0
try:
ow = os.walk("monomotapa/src/posts")
p,d,files=ow.__next__()
except OSError:
print ("[posts] - Error: Can't os.walk() on monomotapa/src/posts except OSError.")
else:
for f in files:
nombre_con_ruta = os.path.join("monomotapa/src/posts", f)
if not f.endswith("~") and not f.startswith("#") and not f.startswith("."):
lp.append((os.path.getmtime(nombre_con_ruta), f))
num_posts += 1
if num_posts > cantidad:
break
lp.sort()
lp.reverse()
# colocando fecha en formato
for tupla in lp:
nombre_post = tupla[1].split(os.sep)[-1]
#contenido = cabeza_post(tupla[1], max_caracteres=149999)
contenido = cabezaPost(tupla[1], max_caracteres=149999)
id_post = "https://rmgss.net/posts/"+nombre_post[:-3]
#categorias = categorias_de_post(nombre_post)
categorias = categoriasDePost(nombre_post)
dict_categorias = {}
c = ""
for cat in categorias:
c += cat + " "
dict_categorias['label'] = c
#dict_categorias['term'] = c
html = markdown.markdown(escape(contenido))
link = id_post
pubdate = ctime(tupla[0])
title = titulo_legible(nombre_post[:-3]) # no incluir '.md'
updated = pubdate
dict_feed_post = {
"id":id_post,
"author": "Rodrigo Garcia",
"category" : categorias,
"content": html,
"link" : id_post,
"updated" : updated,
"title": title
}
lista_posts.append(dict_feed_post)
return lista_posts
###### Define routes
@app.errorhandler(404)
def page_not_found(e):
""" provides basic 404 page"""
defaults = get_page_attributes('defaults.json')
try:
css = defaults['css']
except KeyError:
css = None
pages = get_page_attributes('pages.json')
if '404' in pages:
if'css' in pages['404']:
css = pages['404']['css']
return render_template('static.html',
title = "404::page not found", heading = "Page Not Found",
navigation = top_navigation('404'),
css = css,
contents = Markup(
"This page is not there, try somewhere else.")), 404
@app.route('/users/', defaults={'page': 1})
@app.route('/users/page/<int:page>')
@app.route("/", defaults={'pagina':0})
@app.route('/<int:pagina>')
def index(pagina):
"""provides index page"""
index_page = Page('index')
lista_posts_recientes, total_posts = noticias_recientes(pagina=pagina)
index_page.contexto['lista_posts_recientes'] = lista_posts_recientes
index_page.contexto['total_posts'] = total_posts
index_page.contexto['pagina_actual'] = int(pagina)
return index_page.generate_page()
# default route is it doe not exist elsewhere
@app.route("/<path:page>")
def staticpage(page):
""" display a static page rendered from markdown in src
i.e. displays /page or /page/ as long as src/page.md exists.
srcfile, title and heading may be set in the pages global
(ordered) dictionary but are not required"""
static_page = Page(page)
return static_page.generate_page()
@app.route("/posts/<page>")
def rposts(page):
""" Mustra las paginas dentro la carpeta posts, no es coincidencia
que en este ultimo directorio se guarden los posts.
Ademas incrusta en el diccionario de contexto de la pagina la
fecha de ultima modificacion del post
"""
static_page = Page("posts/"+page)
ultima_modificacion = ultima_modificacion_archivo("posts/"+page)
static_page.contexto['relacionadas'] = noticias_relacionadas(nombre=page+".md")
static_page.contexto['ultima_modificacion'] = ultima_modificacion
static_page.exclude_toc = False # no excluir Índice de contenidos
return static_page.generate_page()
@app.route("/posts")
def indice_posts():
""" Muestra una lista de todos los posts
"""
lista_posts_fecha = posts_list()
#lista_posts_categoria = categorias_list()
lista_posts_categoria = categoriasList()
static_page = Page("posts")
static_page.contexto['lista_posts_fecha'] = lista_posts_fecha
static_page.contexto['lista_posts_categoria'] = lista_posts_categoria
return static_page.generate_page()
@app.route("/posts/categorias")
def lista_categorias():
""" Muestra una lista de las categorias , los posts pertenecen
a cada una y un conteo"""
#lista_categorias = categorias_list()
lista_categorias = categoriasList()
static_page = Page("categorias")
static_page.contexto['lista_posts_categoria'] = lista_categorias
#return (str(lista_categorias))
return static_page.generate_page()
@app.route("/posts/categoria/<categoria>")
def posts_de_categoria(categoria):
""" Muestra los posts que perteneces a la categoria dada
"""
lista_posts = []
if categoria == "fotos": # caegoria especial fotos
lista_posts, total_posts = noticias_recientes(max_caracteres=1250,categoria=categoria)
static_page = Page("fotos")
static_page.contexto['categoria_actual'] = categoria
static_page.contexto['lista_posts_recientes'] = lista_posts
return static_page.generate_page()
#lista_posts = categorias_list(categoria=categoria)
lista_posts = categoriasList(categoria=categoria)
static_page = Page("categorias")
static_page.contexto['categoria_actual'] = categoria
static_page.contexto['lista_posts_categoria'] = lista_posts
return static_page.generate_page()
@app.route("/posts/recientes", defaults={'pagina':0})
@app.route("/posts/recientes/<int:pagina>")
def posts_recientes(pagina):
""" muestra una lista de los posts mas recientes
TODO: terminar
"""
lista_posts, total_posts = noticias_recientes(max_caracteres=368,
pagina=pagina)
static_page = Page("recientes")
static_page.contexto['lista_posts_recientes'] = lista_posts
static_page.contexto['total_posts'] = total_posts
static_page.contexto['pagina_actual'] = pagina
#return (str(lista_posts))
return static_page.generate_page()
@app.route("/contacto", methods=['GET'])
def contacto():
tupla_captcha = captcha_pregunta_opciones_random()
if tupla_captcha is None:
return ("<br>Parece un error interno!</br>")
pregunta = tupla_captcha[0]
opciones = tupla_captcha[1]
static_page = Page("contacto")
static_page.contexto['pregunta'] = pregunta
static_page.contexto['opciones'] = opciones
return static_page.generate_page()
@app.route("/contactoe", methods=['POST'])
def comprobar_mensaje():
""" Comprueba que el mensaje enviado por la caja de texto sea valido
y si lo es, guarda un archivo de texto con los detalles"""
errors = []
if request.method == "POST":
# comprobando validez
nombre = request.form["nombre"]
dir_respuesta = request.form['dir_respuesta']
mensaje = request.form['mensaje']
pregunta = request.form['pregunta']
respuesta = request.form['respuesta']
if len(mensaje) < 2 or mensaje.startswith(" "):
errors.append("Mensaje invalido")
if not captcha_comprobar_respuesta(pregunta, respuesta):
errors.append("Captcha invalido")
if len(errors) > 0:
return str(errors)
# guardando texto
texto = "Remitente: "+nombre
texto += "\nResponder_a: "+dir_respuesta
texto += "\n--- mensaje ---\n"
texto += mensaje
# TODO: cambiar a direccion especificada en archivo de configuracion
dt = datetime.datetime.now()
nombre = "m_"+str(dt.day)+"_"+str(dt.month)+\
"_"+str(dt.year)+"-"+str(dt.hour)+\
"-"+str(dt.minute)+"-"+str(dt.second)
with open(os.path.join("fbs",nombre), "wb") as f:
f.write(texto.encode("utf-8"))
return redirect("/mensaje_enviado", code=302)
@app.route("/mensaje_enviado")
def mensaje_enviado():
static_page = Page("mensaje_enviado")
return static_page.generate_page()
@app.route("/rss")
def rss_feed():
"""Genera la cadena rss con las 15 ultimas noticias del sitio
TODO: Agregar mecenismo para no generar los rss feeds y solo
devolver el archivo rss.xml generado anteriormente. Esto
quiere decir solamente generar el rss_feed cuando se haya hecho
un actualizacion en los posts mas reciente que la ultima vez
que se genero el rss_feed
"""
#return str(rss_ultimos_posts_jinja())
return render_template("rss.html",
contents = rss_ultimos_posts_jinja())
#**vars(self)
#)
##### specialized pages
@app.route("/source")
def source():
"""Display source files used to render a page"""
source_page = Page('source', title = "view the source code",
#heading = "Ver el código fuente",
heading = "Ver el codigo fuente",
internal_css = get_pygments_css())
page = request.args.get('page')
# get source for markdown if any. 404's for non-existant markdown
# unless special page eg source
pagesrc = source_page.get_page_src(page, 'src', 'md')
special_pages = ['source', 'unit-tests', '404']
if not page in special_pages and pagesrc is None:
abort(404)
# set enable_unit_tests to true in config.json to allow
# unit tests to be run through the source page
if app.config['enable_unit_tests']:
contents = '''<p><a href="/unit-tests" class="button">Run unit tests
</a></p>'''
# render tests.py if needed
if page == 'unit-tests':
contents += heading('tests.py', 2)
contents += render_pygments('tests.py', 'python')
else:
contents = ''
# render views.py
contents += heading('views.py', 2)
contents += render_pygments(source_page.get_page_src('views.py'),
'python')
# render markdown if present
if pagesrc:
contents += heading(os.path.basename(pagesrc), 2)
contents += render_pygments(pagesrc, 'markdown')
# render jinja templates
contents += heading('base.html', 2)
contents += render_pygments(
source_page.get_page_src('base.html', 'templates'), 'html')
template = source_page.get_template(page)
contents += heading(template, 2)
contents += render_pygments(
source_page.get_page_src(template, 'templates'), 'html')
return source_page.generate_page(contents)
# @app.route("/unit-tests")
# def unit_tests():
# """display results of unit tests"""
# unittests = Page('unit-tests', heading = "Test Results",
# internal_css = get_pygments_css())
# # exec unit tests in subprocess, capturing stderr
# capture = subprocess.Popen(["python", "tests.py"],
# stdout = subprocess.PIPE, stderr = subprocess.PIPE)
# output = capture.communicate()
# results = output[1]
# contents = '''<p>
# <a href="/unit-tests" class="button">Run unit tests</a>
# </p><br>\n
# <div class="output" style="background-color:'''
# if 'OK' in results:
# color = "#ddffdd"
# result = "TESTS PASSED"
# else:
# color = "#ffaaaa"
# result = "TESTS FAILING"
# contents += ('''%s">\n<strong>%s</strong>\n<pre>%s</pre>\n</div>\n'''
# % (color, result, results))
# # render test.py
# contents += heading('tests.py', 2)
# contents += render_pygments('tests.py', 'python')
# return unittests.generate_page(contents)
Una implementación SSL/TLS libre, [mbedtls](https://tls.mbed.org/) es una biblioteca que reúne una suite de herramientas para cifrado. Está hecha de tal forma que se puede portar fácilmente a dispositivos embebidos como un barato enrutador con GNU/Linux.
## Un poco sobre TLS ##
*Transport Security Layer* ([TLS](https://es.wikipedia.org/wiki/Transport_Layer_Security)) es un conjunto de protocolos que no solamente permiten cifrar comunicaciones, también permiten autenticarlas, veamos un poco de la necesidad de autenticación además del cifrado.
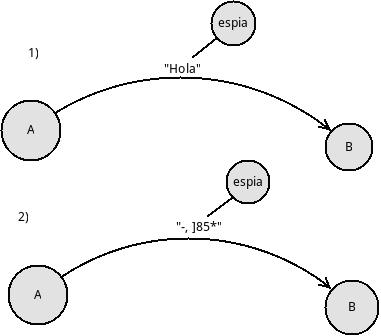
En el caso 1 de arriba se ve como **A** envía a **B** un mensaje "Hola", pero hay un **espía** que está atento a lo que A y B se envían y el espía tambíen recibe "Hola".
En el caso 2 **A** toma una medida de seguridad y cifra el mismo mensaje "Hola" con algún algoritmo de cifrado y el resultado es "-, ]85*" y suponiendo que B conoce el algoritmo que ha usado A, B podrá descifrarlo y obtener "Hola".
Pero "-, ]85*" es el resultado de usar un algortmo "débil" dada su simplicidad ya que el espia con algo de conocimiento en cifrado puede con algunos cientos o miles de intentos podría descubrir el algoritmo simple que A usó para cifrar "Hola". En el siguiente caso A y B deciden usar un mejor método de cifrado:
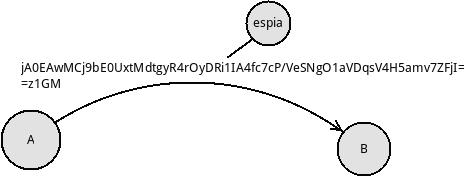
Ahora A ha cifrado "Hola" usando una **clave en común** que comparte con B. El mensaje resultante es:
jA0EAwMCj9bE0UxtMdtgyR4rOyDRi1IA4fc7cP/VeSNgO1aVDqsV4H5amv7ZFjI=
=z1GM
B usa la clave y el algoritmo que ha usado A para descifrar este mensaje como "Hola", suponiendo que el **espia** conce el algoritmo que A, B han usado, aún necesita saber la clave que han usado o al espia le será prácticamente imposible descifrar el mensaje correctamente.
Este cifrado es fuerte en tanto el espia no conozca la clave en común, pero aquí estamos suponiendo que A y B ambos ya cuentan con la clave en común. Pero este no siempre es el caso.
Por ejemplo imaginemos que A y B nunca antes se han comunicado y necesitan comunicarse de manera segura desde la primera vez. Para ello, necesitan **definir el algoritmo que usarán** e **intercambiar una clave en común** antes de comenzar a comunicarse de manera segura.
Allí es donde TLS entra en juego, agrega una capa de seguridad permitiendo a cualquier A o B a usar [criptografía asimétrica](https://es.wikipedia.org/wiki/Criptograf%C3%ADa_asim%C3%A9trica) y protocolos para intercambiar estas estas claves de manera segura.
### Criptografía asimétrica ###
De manera muy resumida con la criptografía asimétrica cualquier A, B necesitan un par de claves; una `clave privada` y una `pública`, estas dos claves están matemáticamente relacionadas y se consigue:
* Cuando se cifra con la llave privada, sólo se puede descifrar con la clave pública.
* Cuando se cifra con la clave pública, sólo se puede descifrar con la clave privada.
La clave pública está pensada para que A la comprata con cualquier otro B, C, etc. y así estos últimos puedan descifrar los mensajes que A cifre usando su llave privada. De igual manera si B usa la clave pública de A para enviarle un mensaje a A, sólo A podrá descifrar este mensaje por que se supone que A y solamente A posee su clave privada. La clave privada no se comparte con nadie.
En tanto A y B intercambien claves públicas y no revelen sus claves privadas, podrán comunicarse de manera segura. Un ejemplo de programa que permite usar este tipo de cifrado es [GNUpg](https://gnupg.org/).
### Necesidad de autenticación ###
Suponiendo que el espia no puede acceder a las claves de A o B, aún puede engañar a B fingiendo que es A:

En este caso el espia le dice a B que es A y le pasa una clave pública, B no tiene forma de comprobar que en realidad un espia esta intentando hacerse pasar por A y aceptará la clave que se le pase, además confiará en esta clave para comunicarse con A.
Para evitar esto se usan certificados [X.509](https://es.wikipedia.org/wiki/X.509), donde se agrega una medida de seguridad para evitar que un espia suplante a algún A. Se usan certificados firmados por autoridades certificadoras de confianza que aseguran a que A es quien dice ser. De este modo B primero confía en una autoridad certificadora **CA**. Cuando alguien le dice a B: "yo soy A, toma mi clave pública". B no confiará ciegamente en esto, primero le pedirá a CA que compruebe que la clave que se le ha pasado a B, realmente le pertenece a A.
Si CA lo comprueba, B confiará plenamente en esa clave pública y a partir de ese momento la asociará a A. Entonces el espia no podrá suplantar de nuevo a A, precisamente TLS implementa avanzados protocolos para asegurar que esto funcione correctamente.
----
Por eso todas las páginas web actualizadas y que cifran su contenido, usan TLS y se identifican con `https`, así los navegadores web y la página web intercambian contenido con un cifrado fuerte, y con las claves autenticadas de manera segura. Por defecto los nevegadores web, confían en un número de [autoridades certificadoras](https://es.wikipedia.org/wiki/Categor%C3%ADa:Autoridades_de_certificaci%C3%B3n) en internet.
## Jugando con mbedtls ##
A diferencia de [openssl](https://www.openssl.org/) que es una implementación muy conocida de TLS, mbedtls se centra en brindar una manera más sencilla de usar TLS o su conjunto de herramientas de cifrado. Además mbedtls se puede fácilmente usar en dispositivos embebidos con capacidades computacionales reducidas, para lo que sigue de este post mostraré una forma de construir mbedtls para que funcione en un enrutador TL-WDR3600 (aunque podría hacerse funcionar en un más barato como el tl-mr3020), desde una distribución GNU/Linux.
Estamos asumiendo que el enrutador tiene instalado firmware libre como lede, openwrt o librecmc.
### Construyendo mbedtls ###
Una vez descargamos el código fuente desde [https://tls.mbed.org/download](https://tls.mbed.org/download), abrimos el archivo `README.md`, veremos que este requiere de herramienetas de construcción como `make` o `cmake`. Para nuestro caso usaremos solamente make, entonces instalaremos los paquetes; `gcc`, `build-essential`, `make`. En nuestra distribución preferida GNU/Linux.
Luego vamos al directorio donde esta mbedtls y ejecutamos:
make
Deberíamos estar atentos al procedimiento y si este termina satisfactoriamente, deberíamos poder probar por ejemplo cifrando y descifrando con `rsa`. Se ha creado una una carpeta `programs/pkey/` y allí unos ejecutables que son programas de prueba:
cd programs/pkey
./rsa_encrypt "Hola"
Cifrará el mensaje "Hola" con el par de claves de prueba que se crearón al hacer make; `rsa_priv.txt` y `rsa_pub.txt` y lo guarda en `result-enc.txt`, para descifrarlo se usa.
./rsa_decrypt
Y si vemos "Hola", significa que se ha descifrado correctamente.
### Compilación cruzada de mbedtls ###
Vamos a utilizar el SDK *Software Development Kit* de lede o librecmc para construir programas para enrutadores como el TL-WDR3600, ([revisa este post para ver como construir el SDK ](construir-firmware-para-enrutadores-con-buildroot)).
Una vez tengamos el SDK, al llamar a `make` tenemos que usar el compilador gcc para la arquitectura mips_74kc que es la arquitectura del TL-WDR3600, en lugar del `gcc` instalado en el sistema desde el cual compilaremos.
Para simplificar la compilación cruzada, puedes utilizar este script que llamaremos `set-up.sh`. Antes de ver el script deberíamos hacer un enlace simbólico del SDK que usaremos en la misma ruta donde descomprimimos mbedtls, lo podemos hacer con:
ln --symbolic /ruta/absoluta/hacia/el/sdk/ SDK
Por ejemplo:
ln --symbolic /home/alguien/lede-sdk-ar71xx-generic_gcc-5.4.0_musl.Linux-i686 SDK
A continuación el script `set-up.sh`.
:::bash
#!/bin/bash
# Para compilar:
#
# ./set-up.sh build
# ./set-up.sh clean
# para copiarlo directamente al enrutador con <IP> dada (lo copia en /tmp/)
#
# ./set-up.sh export <IP>
OP1=$1
OP2=$2
ayuda()
{
echo "Uso:"
echo "Construye usando un cross compiler mips-openwrt-linux-musl-gcc:"
echo " ./set-up.sh build"
echo "Equivalente a 'make clean':"
echo " ./set-up.sh clean"
echo "Construye y copia al enrutador con IP (usa root@IP y copia en /tmp/):"
echo " ./set-up.sh export IP"
echo "Ejemplo:"
echo " ./set-up.sh export 192.168.1.1"
echo ""
echo "NOTA Antes de ejecutar:"
echo " La ruta hacia el SDK de LEDE debe estar en este mismo directorio"
echo " puede ser con un enlace simbolico con el nombre 'SDK'"
echo " ln --symbolic /ruta/absoluta/hacia/el/sdk/ SDK"
}
####
# setup inicial
setup()
{
# agregando al path
if ! echo $PATH | grep "mips-openwrt-linux-gcc-5.4.0/bin"
then
RUTA_SDK=$(readlink SDK)
PATH=$PATH:"$RUTA_SDK"staging_dir/toolchain-mips_24kc_gcc-5.4.0_musl/bin/
export PATH
fi
# agregando staging dir
if ! echo $STAGING_DIR | grep "lede-sdk-ar71xx-generic_gcc-5.4.0_musl.Linux-i686/staging_dir"
then
RUTA_SDK=$(readlink SDK)
STAGING_DIR="$RUTA_SDK"staging_dir/toolchain-mips_24kc_gcc-5.4.0_musl/bin/
export STAGING_DIR
fi
echo
echo "PATH:$PATH"
echo "STAGING_DIR:$STAGING_DIR"
}
####
build()
{
echo "Construyendo..."
setup
echo
echo "CROSS COMPILER:"
mips-openwrt-linux-musl-gcc --version
# para construir mbedtls (ver README.md)
#make CC=mips-openwrt-linux-musl-gcc LD=mips-openwrt-linux-ld
# construir usando archivo de configuracion personalizado
echo ":-:-:"
echo "Construyendo usando archivo de configuracion distinto al por defecto"
echo "config-mini-tls1_1.h"
make CC=mips-openwrt-linux-musl-gcc \
LD=mips-openwrt-linux-ld \
CFLAGS="-I$PWD/configs -DMBEDTLS_CONFIG_FILE='<config-mini-tls1_1.h>'" \
SHARED=TRUE
echo "Hecho"
}
clean()
{
echo "Limpiando..."
setup
make clean
}
exportar()
{
"Exportando..."
build
scp -r programs/pkey root@$OP2:/tmp/
}
####
# opciones
if [ -z "$OP1" ]
then
ayuda
exit 2
fi
if [ $OP1 == "build" ]
then
build
exit 0
fi
if [ $OP1 == "clean" ]
then
clean
exit 0
fi
if [ $OP1 == "export" ]
then
R=$(echo $OP2 | grep "[a-z,A-Z]")
if [ -z $OP2 ] || [ $R != "" ]
then
ayuda
exit 2
else
exportar
exit 0
fi
fi
ayuda
exit 2
Para que sea más cómodo manejarlo le daremos permisos de ejecución con `chmod +x set-up.sh`
El script se encarga de primero agregar al `PATH` el compilador del SDK de lede y lo exporta. Al hacer `./set-up.sh build` se llamará al Makefile de mbedtls pero pasándole tres opciones extra para que realice la compilación cruzada correctamente:
:::bash
make CC=mips-openwrt-linux-musl-gcc LD=mips-openwrt-linux-ld CFLAGS="-I$PWD/configs -DMBEDTLS_CONFIG_FILE='<config-mini-tls1_1.h>'" SHARED=TRUE
Aquí, `CC=mips-openwrt-linux-musl-gcc` indica a make que use el compilador `mips-openwrt-linux-musl-gcc` en lugar de `gcc` instalado en el S.O. De igual forma con el enlazador al modificar `LD`.
Como se indica en la documentación (ver README en configs/README.txt de mbedtls) usaremos una configuración mínima para compilar mbedtls sin por ejemplo el módulo de entropía, y se usará el archivo de configuración `config-mini-tls1_1.h`, esto se logra agregando `CFLAGS="-I$PWD/configs -DMBEDTLS_CONFIG_FILE='<config-mini-tls1_1.h>'"` al llamar a make. Finalmente `SHARED=TRUE` hace que se construyan tambíen bibliotecas compartidas (ver más adelante)
Así es como el script nos permite hacer el *cross compiling* (compilación cruzada) y una vez termina podemos probar si esto ha funcionado copiando la carpeta `programs/pkey/` en el enrutador manualmente o mediante el script y su opción "export".
Para poder probarlo, deberíamos tener instalado en el enrutador la biblioteca mbedtls, en lede se hace con:
opkg install libmbedtls
**Si no logras instalar vía opkg**, el siguiente procedimiento podría funcionar (no lo he probado):
1. De la carpeta `library/` en el directorio donde construimos mbedtls, copiar al directorio `/usr/lib/` del enrutador los archivos; `libmbedcrypto.so`, `libmbedtls.so`, `libmbedx509.so`. Estos son las bibliotecas compartidas que make ha construido al definir `SHARED=TRUE` en el script.
2. Crear enlaces simbólicos en el enrutador, para que el programa de cifrado sepa que la biblioteca mbedtls esta instalada:
cd /usr/lib/
ln -s $PWD/libmbedcrypto.so libmbedcrypto.so.0
ln -s $PWD/libmbedtls.so libmbedtls.so.10
ln -s $PWD/libmbedx509.so libmbedx509.so.0
2. Copiar la carpeta `programs/pkey` que se construyerón con los programas de prueba, a `/tmp/` del enrutador.
Luego en el enrutador en el directorio `/tmp/programs/pkey`, deberíamos poder ejecutar los programas para cifrar y descifrar con rsa como probamos antes, si todo funciona bien ya podemos jugar y usar la bilioteca mbedtls para hacer/modificar programas y que se puedan ejecutar en nuestros enrutadores :)
#### Modificando ####
Como mbedtls es software libre, podemos modificar el código en cualquier momento y probar los resultados de las modificaciones que hagamos, es cuestión de estudiar el código y aprender a dominarlo para hacer cosas divertidas.
Espero esta guía te haya servido, [ponte en contacto](/contacto) para consultas o correcciones.


 Posts
Posts
 Categorías
Categorías
 Fotos
Fotos
 Acerca de mi
Acerca de mi
 Contacto
Contacto