

 Posts
Posts
 Categorías
Categorías
 Fotos
Fotos
 Acerca de mi
Acerca de mi
 Contacto
Contacto
views.py
# -*- coding: utf-8 -*-
"""
Monomotapa - A Micro CMS
Copyright (C) 2014, Paul Munday.
PO Box 28228, Portland, OR, USA 97228
paul at paulmunday.net
Modificado por: Rodrigo Garcia 2017 https://rmgss.net/contacto
This program is free software: you can redistribute it and/or modify
it under the terms of the GNU Affero Public License as published by
the Free Software Foundation, either version 3 of the License, or
(at your option) any later version.
This program is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU General Public License for more details.
You should have received a copy of the GNU Affero General Public License
along with this program. If not, see <http://www.gnu.org/licenses/>.
Monomotapa:
a city whose inhabitants are bounded by deep feelings of friendship,
so that they intuit one another's most secret needs and desire.
For instance, if one dreams that his friend is sad, the friend will
perceive the distress and rush to the sleepers rescue.
(Jean de La Fontaine, *Fables choisies, mises en vers*, VIII:11 Paris,
2nd ed., 1678-9)
cited in :
Alberto Manguel and Gianni Guadalupi, *The Dictionary of Imaginary Places*,
Bloomsbury, London, 1999.
A micro cms written using the Flask microframework, orignally to manage my
personal site. It is designed so that publishing a page requires no more than
dropping a markdown page in the appropriate directory (though you need to edit
a json file if you want it to appear in the top navigation).
It can also display its own source code and run its own unit tests.
The name 'monomotapa' was chosen more or less at random (it shares an initial
with me) as I didn't want to name it after the site and be typing import
paulmunday, or something similar, as that would be strange.
"""
from flask import render_template, abort, Markup, escape, request #, make_response
from flask import redirect
from werkzeug.utils import secure_filename
from pygments import highlight
from pygments.lexers import PythonLexer, HtmlDjangoLexer, TextLexer
from pygments.formatters import HtmlFormatter
import markdown
from time import gmtime, strptime, strftime, ctime, mktime
import datetime
import os.path
import os
import subprocess
import json
import traceback
from collections import OrderedDict
from simplemotds import SimpleMotd
from monomotapa import app
from monomotapa.config import ConfigError
from monomotapa.utils import captcha_comprobar_respuesta, captcha_pregunta_opciones_random
from monomotapa.utils import categorias_de_post, categoriasDePost, categoriasList, cabezaPost
from monomotapa.utils import titulo_legible, metaTagsAutomaticos
from markdown.extensions.toc import TocExtension
json_pattrs = {}
with open(os.path.join('monomotapa','pages.json'), 'r') as pagefile:
json_pattrs = json.load(pagefile)
simplemotd = SimpleMotd("config_simplemotds.json")
class MonomotapaError(Exception):
"""create classs for own errors"""
pass
def get_page_attributes(jsonfile):
"""Returns dictionary of page_attributes.
Defines additional static page attributes loaded from json file.
N.B. static pages do not need to have attributes defined there,
it is sufficient to have a page.md in src for each /page
possible values are src (name of markdown file to be rendered)
heading, title, and trusted (i.e. allow embeded html in markdown)"""
try:
with open(src_file(jsonfile), 'r') as pagesfile:
page_attributes = json.load(pagesfile)
except IOError:
page_attributes = []
return page_attributes
def get_page_attribute(attr_src, page, attribute):
"""returns attribute of page if it exists, else None.
attr_src = dictionary(from get_page_attributes)"""
if page in attr_src and attribute in attr_src[page]:
return attr_src[page][attribute]
else:
return None
# Navigation
def top_navigation(page):
"""Generates navigation as an OrderedDict from navigation.json.
Navigation.json consists of a json array(list) "nav_order"
containing the names of the top navigation elements and
a json object(dict) called "nav_elements"
if a page is to show up in the top navigation
there must be an entry present in nav_order but there need not
be one in nav_elements. However if there is the key must be the same.
Possible values for nav_elements are link_text, url and urlfor
The name from nav_order will be used to set the link text,
unless link_text is present in nav_elements.
url and urlfor are optional, however if ommited the url wil be
generated in the navigation by url_for('staticpage', page=[key])
equivalent to @app.route"/page"; def page())
which may not be correct. If a url is supplied it will be used
otherwise if urlfor is supplied it the url will be
generated with url_for(urlfor). url takes precendence so it makes
no sense to supply both.
Web Sign-in is supported by adding a "rel": "me" attribute.
"""
with open(src_file('navigation.json'), 'r') as navfile:
navigation = json.load(navfile)
base_nav = OrderedDict({})
for key in navigation["nav_order"]:
nav = {}
nav['base'] = key
nav['link_text'] = key
if key in navigation["nav_elements"]:
elements = navigation["nav_elements"][key]
nav.update(elements)
base_nav[key] = nav
return {'navigation' : base_nav, 'page' : page}
# For pages
class Page:
"""Generates pages as objects"""
def __init__(self, page, **kwargs):
"""Define attributes for pages (if present).
Sets self.name, self.title, self.heading, self.trusted etc
This is done through indirection so we can update the defaults
(defined in the 'attributes' dictionary) with values from config.json
or pages.json easily without lots of if else statements.
If css is supplied it will overide any default css. To add additional
style sheets on a per page basis specifiy them in pages.json.
The same also applies with hlinks.
css is used to set locally hosted stylesheets only. To specify
external stylesheets use hlinks: in config.json for
default values that will apply on all pages unless overidden, set here
to override the default. Set in pages.json to add after default.
"""
# set default attributes
self.page = page.rstrip('/')
self.defaults = get_page_attributes('defaults.json')
self.pages = get_page_attributes('pages.json')
self.url_base = self.defaults['url_base']
title = titulo_legible(page.lower())
heading = titulo_legible(page.capitalize())
self.categorias = categoriasDePost(self.page)
self.exclude_toc = True
try:
self.default_template = self.defaults['template']
except KeyError:
raise ConfigError('template not found in default.json')
# will become self.name, self.title, self.heading,
# self.footer, self.internal_css, self.trusted
attributes = {'name' : self.page, 'title' : title,
'navigation' : top_navigation(self.page),
'heading' : heading, 'footer' : None,
'css' : None , 'hlinks' :None, 'internal_css' : None,
'trusted': False,
'preview-chars': 250,
}
# contexto extra TODO: revisar otra forma de incluir un contexto
self.contexto = {}
self.contexto['consejo'] = simplemotd.getMotdContent()
# set from defaults
attributes.update(self.defaults)
# override with kwargs
attributes.update(kwargs)
# override attributes if set in pages.json
if page in self.pages:
attributes.update(self.pages[page])
# set attributes (as self.name etc) using indirection
for attribute, value in attributes.items():
# print('attribute', attribute, '=-==>', value)
setattr(self, attribute, value)
# meta tags
try:
self.pages[self.page]['title'] = attributes['title']
self.pages[self.page]['url_base'] = self.url_base
metaTags = metaTagsAutomaticos(self.page, self.pages.get(self.page, {}))
self.meta = metaTags
# for key, value in self.pages[self.page].items():
# print(' ', key, ' = ', value)
except Exception as e:
tb = traceback.format_exc()
print('Error assigning meta:', str(e), '\n', str(tb))
# reset these as we want to append rather than overwrite if supplied
if 'css' in kwargs:
self.css = kwargs['css']
elif 'css' in self.defaults:
self.css = self.defaults['css']
if 'hlinks' in kwargs:
self.hlinks = kwargs['hlinks']
elif 'hlinks' in self.defaults:
self.hlinks = self.defaults['hlinks']
# append hlinks and css from pages.json rather than overwriting
# if css or hlinks are not supplied they are set to default
if page in self.pages:
if 'css' in self.pages[page]:
self.css = self.css + self.pages[page]['css']
if 'hlinks' in self.pages[page]:
self.hlinks = self.hlinks + self.pages[page]['hlinks']
# append heading to default if set in config
self.title = self.title + app.config.get('default_title', '')
def _get_markdown(self):
"""returns rendered markdown or 404 if source does not exist"""
src = self.get_page_src(self.page, 'src', 'md')
if src is None:
abort(404)
else:
return render_markdown(src, self.trusted)
def get_page_src(self, page, directory=None, ext=None):
""""return path of file (used to generate page) if it exists,
or return none.
Also returns the template used to render that page, defaults
to static.html.
It will optionally add an extension, to allow
specifiying pages by route."""
# is it stored in a config
pagename = get_page_attribute(self.pages, page, 'src')
if not pagename:
pagename = page + get_extension(ext)
if os.path.exists(src_file(pagename , directory)):
return src_file(pagename, directory)
else:
return None
def get_template(self, page):
"""returns the template for the page"""
pagetemplate = get_page_attribute(self.pages, page, 'template')
if not pagetemplate:
pagetemplate = self.default_template
if os.path.exists(src_file(pagetemplate , 'templates')):
return pagetemplate
else:
raise MonomotapaError("Template: %s not found" % pagetemplate)
def generate_page(self, contents=None):
"""return a page generator function.
For static pages written in Markdown under src/.
contents are automatically rendered.
N.B. See note above in about headers"""
toc = '' # table of contents
if not contents:
contents, toc = self._get_markdown()
# print('////', toc)
template = self.get_template(self.page)
# print('......................')
# def mos(**kwargs):
# for k in kwargs:
# print(k, end=',')
# mos(**vars(self))
return render_template(template,
contents = Markup(contents),
toc=toc,
**vars(self))
# helper functions
def src_file(name, directory=None):
"""return potential path to file in this app"""
if not directory:
return os.path.join( 'monomotapa', name)
else:
return os.path.join('monomotapa', directory, name)
def get_extension(ext):
'''constructs extension, adding or stripping leading . as needed.
Return null string for None'''
if ext is None:
return ''
elif ext[0] == '.':
return ext
else:
return '.%s' % ext
def render_markdown(srcfile, trusted=False):
""" Returns markdown file rendered as html and the table of contents as html.
Defaults to untrusted:
html characters (and character entities) are escaped
so will not be rendered. This departs from markdown spec
which allows embedded html."""
try:
with open(srcfile, 'r') as f:
src = f.read()
md = markdown.Markdown(extensions=['toc', 'codehilite'])
md.convert(src)
toc = md.toc
if trusted == True:
content = markdown.markdown(src,
extensions=['codehilite',
TocExtension(permalink=True)])
else:
content = markdown.markdown(escape(src),
extensions=['codehilite',
TocExtension(permalink=True)])
return content, toc
except IOError:
return None
def render_pygments(srcfile, lexer_type):
"""returns src(file) marked up with pygments"""
if lexer_type == 'python':
with open(srcfile, 'r') as f:
src = f.read()
contents = highlight(src, PythonLexer(), HtmlFormatter())
elif lexer_type == 'html':
with open(srcfile, 'r') as f:
src = f.read()
contents = highlight(src, HtmlDjangoLexer(), HtmlFormatter())
# default to TextLexer for everything else
else:
with open(srcfile, 'r') as f:
src = f.read()
contents = highlight(src, TextLexer(), HtmlFormatter())
return contents
def get_pygments_css(style=None):
"""returns css for pygments, use as internal_css"""
if style is None:
style = 'friendly'
return HtmlFormatter(style=style).get_style_defs('.highlight')
def heading(text, level):
"""return as html heading at h[level]"""
heading_level = 'h%s' % str(level)
return '\n<%s>%s</%s>\n' % (heading_level, text, heading_level)
def posts_list(ordenar_por_fecha=True, ordenar_por_nombre=False):
'''Retorna una lista con los nombres de archivos con extension .md
dentro de la cappeta src/posts, por defecto retorna una lista con
la tupla (nombre_archivo, fecha_subida)'''
lista_posts = []
lp = []
if ordenar_por_nombre:
try:
ow = os.walk("monomotapa/src/posts")
p , directorios , archs = ow.__next__()
except OSError:
print ("[posts] - Error: Cant' os.walk() on monomotapa/src/posts except OSError")
else:
for arch in archs:
if arch.endswith(".md") and not arch.startswith("#") \
and not arch.startswith("~") and not arch.startswith("."):
lista_posts.append(arch)
lista_posts.sort()
return lista_posts
if ordenar_por_fecha:
try:
ow = os.walk("monomotapa/src/posts")
p,d,files=ow.__next__()
except OSError:
print ("[posts] - Error: Can't os.walk() on monomotapa/src/posts except OSError.")
else:
for f in files:
nombre_con_ruta = os.path.join("monomotapa/src/posts", f)
if not f.endswith("~") and not f.startswith("#") and not f.startswith("."):
secs_modificacion = SecsModificacionPostDesdeJson(f, json_pattrs)
ultima_modificacion = os.path.getmtime(nombre_con_ruta)
lp.append((secs_modificacion, ultima_modificacion, f))
lp.sort()
lp.reverse()
# colocando fecha en formato
for tupla in lp:
#fecha = strftime("a, %d %b %Y %H:%M:%S", ctime(tupla[0]))
cfecha = ctime(tupla[1])
#fecha = strptime("%a %b %d %H:%M:%S %Y", cfecha)
lista_posts.append((cfecha, tupla[2]))
return lista_posts
def categorias_list(categoria=None):
""" Rotorna una lista con los nombres de posts y el numero de posts que
pertenecen a la categoria dada o a cada categoria.
Las categorias se obtienen analizando la primera linea de cada archivo .md
an la carpeta donde se almacenan los posts.
Si no se especifica `categoria' cada elemento de la lista devuelta es:
(nombre_categoria, numero_posts, [nombres_posts])
si se especifica `categoria' cada elemento de la lista devuelta es:
(numero_posts, [nombres_posts]
"""
lista_posts = posts_list(ordenar_por_nombre=True)
lista_categorias = []
if categoria is not None:
c = 0
posts = []
for post in lista_posts:
nombre_arch = "monomotapa/src/posts/"+post
with open(nombre_arch, 'r') as file:
linea = file.readline().decode("utf-8")
lc = linea.split("[#")[1:]
for cad in lc:
cat = cad.split("]")[0]
if cat == categoria:
c += 1
posts.append(post)
lista_categorias = (c, posts)
return lista_categorias
dic_categorias = {}
for post in lista_posts:
nombre_arch = "monomotapa/src/posts/"+post
with open(nombre_arch, 'r') as fil:
linea = fil.readline().decode('utf-8') # primera linea
# extrayendo las categorias y registrando sus ocurrencias
# ejemplo: catgorías: [#reflexión](categoria/reflexion) [#navidad](categoria/navidad)
# extrae: [reflexion,navidad]
lc = linea.split("[#")[1:]
for cad in lc:
cat = cad.split("]")[0]
if cat not in dic_categorias:
dic_categorias[cat] = (1,[post]) # nuevo registro por categoria
else:
tupla = dic_categorias[cat]
c = tupla[0] + 1
lis = tupla[1]
if post not in lis:
lis.append(post)
dic_categorias[cat] = (c, lis)
# convirtiendo en lista
for k, v in dic_categorias.iteritems():
lista_categorias.append((k,v[0],v[1]))
lista_categorias.sort()
lista_categorias.reverse()
return lista_categorias
def cabeza_post(archivo , max_caracteres=250, categorias=True):
""" Devuelve las primeras lineas de una archivo de post (en formato markdown)
con un maximo numero de caracteres excluyendo titulos en la cabeza devuelta.
Si se especifica `categorias' en True
Se devuelve una lista de la forma:
(cabeza_post, categorias)
donde categorias son cadenas con los nombres de las categorias a la que
pertenece el post
"""
cabeza_post = ""
cats = []
with open(os.path.join("monomotapa/src/posts",archivo)) as file:
# analizando si hay titulos al principio
# Se su pone que la primera linea es de categorias
for linea in file.readlines():
linea = linea.decode("utf-8")
if linea.startswith(u"categorías:") or linea.startswith("categorias"):
if categorias:
cats = categoriasDePost(archivo)
#cats = categorias_de_post(archivo)
else:
# evitando h1, h2
if linea.startswith("##") or linea.startswith("#"):
cabeza_post += " "
else:
cabeza_post += linea
if len(cabeza_post) >= max_caracteres:
break
cabeza_post = cabeza_post[0:max_caracteres-1]
if categorias:
return (cabeza_post, cats)
return cabeza_post
def ultima_modificacion_archivo(archivo):
""" Retorna una cadena indicando la fecha de ultima modificacion del
`archivo' dado, se asume que `archivo' esta dentro la carpeta "monomotapa/src"
Retorna una cadena vacia en caso de no poder abrir `archivo'
"""
try:
ts = strptime(ctime(os.path.getmtime("monomotapa/src/"+archivo+".md")))
return strftime("%d %B %Y", ts)
except OSError:
return ""
def SecsModificacionPostDesdeJson(archivo, dict_json):
''' dado el post con nombre 'archivo' busca en 'dict_json' el
attribute 'date' y luego obtiene los segundos totales desde
esa fecha.
Si no encuentra 'date' para 'archivo' en 'dict.json'
retorna los segundos totales desde la ultima modificacion
del archivo de post directamente (usa os.path.getmtime)
'''
nombre = archivo.split('.md')[0] # no contar extension .md
nombre_con_ruta = os.path.join("monomotapa/src/posts", archivo)
date_str = dict_json.get('posts/'+nombre, {}).\
get('attributes',{}).\
get('date','')
if date_str == '':
# el post no tiene "date" en pages.json
return os.path.getmtime(nombre_con_ruta)
else:
time_struct = strptime(date_str, '%Y-%m-%d')
dt = datetime.datetime.fromtimestamp(mktime(time_struct))
return (dt - datetime.datetime(1970,1,1)).total_seconds()
def noticias_recientes(cantidad=11, max_caracteres=250,
categoria=None, pagina=0):
'''Devuelve una lista con hasta `cantidad' de posts mas recientes,
un maximo de `max_caracteres' de caracteres del principio del post y
el numero total de posts encontrados
Si se proporciona `categoria' devuelve la lista de posts solamente
pertenecientes esa categoria.
Si `pagina' > 0 se devulve hasta `cantidad' numero de posts en el
rango de [ cantidad*pagina : cantidad*(pagina+1)]
Cada elemento de la lista devuelta contiene:
(nombre_post, ultima_modificacion, cabeza_archivo, categorias)
Al final se retorna: (lista_posts, numero_de_posts)
'''
lista_posts = []
lp = []
num_posts = 0
posts_en_categoria = []
if categoria is not None:
#posts_en_categoria = categorias_list(categoria)[1]
posts_en_categoria = categoriasList(categoria)[1]
# categoria especial fotos
if categoria == "fotos":
l = []
for p in posts_en_categoria:
l.append(p + '.md')
posts_en_categoria = l
try:
ow = os.walk("monomotapa/src/posts")
p,d,files = ow.__next__()
#p,d,files=ow.next()
except OSError:
print ("[posts] - Error: Can't os.walk() on monomotapa/src/posts except OSError.")
else:
for f in files:
nombre_con_ruta = os.path.join("monomotapa/src/posts", f)
if not f.endswith("~") and not f.startswith("#") and not f.startswith("."):
secs_modificacion = SecsModificacionPostDesdeJson(f, json_pattrs)
ultima_modificacion = os.path.getmtime(nombre_con_ruta)
previewChars = json_pattrs.get('posts/'+f[:-3], {}).\
get('attributes', {}).\
get('preview-chars', max_caracteres)
if categoria is not None:
if f in posts_en_categoria:
lp.append((secs_modificacion,
ultima_modificacion,
previewChars,
f))
num_posts += 1
else:
lp.append((secs_modificacion,
ultima_modificacion,
previewChars,
f))
num_posts += 1
lp.sort()
lp.reverse()
# seleccionado por paginas
lp = lp[cantidad*pagina : cantidad*(pagina+1)]
# colocando fecha en formato
for tupla in lp:
cfecha = ctime(tupla[1])
nombre_post = tupla[3].split(os.sep)[-1]
previewChars = tupla[2]
#contenido = cabeza_post(tupla[3], max_caracteres=previewChars)[0]
#categorias = cabeza_post(tupla[3], max_caracteres=previewChars)[1]
contenido = cabezaPost(tupla[3], max_caracteres=previewChars)[0]
categorias = cabezaPost(tupla[3], max_caracteres=previewChars)[1]
cabeza_archivo = markdown.markdown(escape(contenido + ' ...'))
lista_posts.append((nombre_post[:-3], cfecha, \
cabeza_archivo, categorias))
return (lista_posts, num_posts)
def noticias_relacionadas(cantidad=5, nombre=None):
"""Retorna una lista con posts relacionadas, es decir que tienen son de las
mismas categorias que el post con nombre `nombre'.
Cada elemento de la lista de posts contiene el nombre del post
"""
#categorias = categorias_de_post(nombre) ## TODO: corregir categorias de post
categorias = categoriasDePost(nombre)
numero = 0
if categorias is None:
return None
posts = []
for categoria in categorias:
#lista = categorias_list(categoria)[1] # nombres de posts
lista = categoriasList(categoria)[1]
numero += len(lista)
for nombre_post in lista:
if nombre_post + '.md' != nombre:
posts.append(nombre_post)
if numero >= cantidad:
return posts
return posts
def rss_ultimos_posts_jinja(cantidad=15):
"""Retorna una lista de los ultimos posts preparados para
ser renderizados (usando jinja) como un feed rss
Examina cada post del mas reciente al menos reciente, en
total `cantidad' posts. Por cada post devuelve:
id: id which identifies the entry using a
universally unique and permanent URI
author: Get or set autor data. An author element is a dict containing a
name, an email adress and a uri.
category: A categories has the following fields:
- *term* identifies the category
- *scheme* identifies the categorization scheme via a URI.
- *label* provides a human-readable label for display
comments: Get or set the the value of comments which is the url of the
comments page for the item.
content: Get or set the cntent of the entry which contains or links to the
complete content of the entry.
description(no contiene): Get or set the description value which is the item synopsis.
Description is an RSS only element.
link: Get or set link data. An link element is a dict with the fields
href, rel, type, hreflang, title, and length. Href is mandatory for
ATOM.
pubdate(no contiene): Get or set the pubDate of the entry which indicates when the entry
was published.
title: the title value of the entry. It should contain a human
readable title for the entry.
updated: the updated value which indicates the last time the entry
was modified in a significant way.
"""
lista_posts = []
lp = []
num_posts = 0
try:
ow = os.walk("monomotapa/src/posts")
p,d,files=ow.__next__()
except OSError:
print ("[posts] - Error: Can't os.walk() on monomotapa/src/posts except OSError.")
else:
for f in files:
nombre_con_ruta = os.path.join("monomotapa/src/posts", f)
if not f.endswith("~") and not f.startswith("#") and not f.startswith("."):
lp.append((os.path.getmtime(nombre_con_ruta), f))
num_posts += 1
if num_posts > cantidad:
break
lp.sort()
lp.reverse()
# colocando fecha en formato
for tupla in lp:
nombre_post = tupla[1].split(os.sep)[-1]
#contenido = cabeza_post(tupla[1], max_caracteres=149999)
contenido = cabezaPost(tupla[1], max_caracteres=149999)
id_post = "https://rmgss.net/posts/"+nombre_post[:-3]
#categorias = categorias_de_post(nombre_post)
categorias = categoriasDePost(nombre_post)
dict_categorias = {}
c = ""
for cat in categorias:
c += cat + " "
dict_categorias['label'] = c
#dict_categorias['term'] = c
html = markdown.markdown(escape(contenido))
link = id_post
pubdate = ctime(tupla[0])
title = titulo_legible(nombre_post[:-3]) # no incluir '.md'
updated = pubdate
dict_feed_post = {
"id":id_post,
"author": "Rodrigo Garcia",
"category" : categorias,
"content": html,
"link" : id_post,
"updated" : updated,
"title": title
}
lista_posts.append(dict_feed_post)
return lista_posts
###### Define routes
@app.errorhandler(404)
def page_not_found(e):
""" provides basic 404 page"""
defaults = get_page_attributes('defaults.json')
try:
css = defaults['css']
except KeyError:
css = None
pages = get_page_attributes('pages.json')
if '404' in pages:
if'css' in pages['404']:
css = pages['404']['css']
return render_template('static.html',
title = "404::page not found", heading = "Page Not Found",
navigation = top_navigation('404'),
css = css,
contents = Markup(
"This page is not there, try somewhere else.")), 404
@app.route('/users/', defaults={'page': 1})
@app.route('/users/page/<int:page>')
@app.route("/", defaults={'pagina':0})
@app.route('/<int:pagina>')
def index(pagina):
"""provides index page"""
index_page = Page('index')
lista_posts_recientes, total_posts = noticias_recientes(pagina=pagina)
index_page.contexto['lista_posts_recientes'] = lista_posts_recientes
index_page.contexto['total_posts'] = total_posts
index_page.contexto['pagina_actual'] = int(pagina)
return index_page.generate_page()
# default route is it doe not exist elsewhere
@app.route("/<path:page>")
def staticpage(page):
""" display a static page rendered from markdown in src
i.e. displays /page or /page/ as long as src/page.md exists.
srcfile, title and heading may be set in the pages global
(ordered) dictionary but are not required"""
static_page = Page(page)
return static_page.generate_page()
@app.route("/posts/<page>")
def rposts(page):
""" Mustra las paginas dentro la carpeta posts, no es coincidencia
que en este ultimo directorio se guarden los posts.
Ademas incrusta en el diccionario de contexto de la pagina la
fecha de ultima modificacion del post
"""
static_page = Page("posts/"+page)
ultima_modificacion = ultima_modificacion_archivo("posts/"+page)
static_page.contexto['relacionadas'] = noticias_relacionadas(nombre=page+".md")
static_page.contexto['ultima_modificacion'] = ultima_modificacion
static_page.exclude_toc = False # no excluir Índice de contenidos
return static_page.generate_page()
@app.route("/posts")
def indice_posts():
""" Muestra una lista de todos los posts
"""
lista_posts_fecha = posts_list()
#lista_posts_categoria = categorias_list()
lista_posts_categoria = categoriasList()
static_page = Page("posts")
static_page.contexto['lista_posts_fecha'] = lista_posts_fecha
static_page.contexto['lista_posts_categoria'] = lista_posts_categoria
return static_page.generate_page()
@app.route("/posts/categorias")
def lista_categorias():
""" Muestra una lista de las categorias , los posts pertenecen
a cada una y un conteo"""
#lista_categorias = categorias_list()
lista_categorias = categoriasList()
static_page = Page("categorias")
static_page.contexto['lista_posts_categoria'] = lista_categorias
#return (str(lista_categorias))
return static_page.generate_page()
@app.route("/posts/categoria/<categoria>")
def posts_de_categoria(categoria):
""" Muestra los posts que perteneces a la categoria dada
"""
lista_posts = []
if categoria == "fotos": # caegoria especial fotos
lista_posts, total_posts = noticias_recientes(max_caracteres=1250,categoria=categoria)
static_page = Page("fotos")
static_page.contexto['categoria_actual'] = categoria
static_page.contexto['lista_posts_recientes'] = lista_posts
return static_page.generate_page()
#lista_posts = categorias_list(categoria=categoria)
lista_posts = categoriasList(categoria=categoria)
static_page = Page("categorias")
static_page.contexto['categoria_actual'] = categoria
static_page.contexto['lista_posts_categoria'] = lista_posts
return static_page.generate_page()
@app.route("/posts/recientes", defaults={'pagina':0})
@app.route("/posts/recientes/<int:pagina>")
def posts_recientes(pagina):
""" muestra una lista de los posts mas recientes
TODO: terminar
"""
lista_posts, total_posts = noticias_recientes(max_caracteres=368,
pagina=pagina)
static_page = Page("recientes")
static_page.contexto['lista_posts_recientes'] = lista_posts
static_page.contexto['total_posts'] = total_posts
static_page.contexto['pagina_actual'] = pagina
#return (str(lista_posts))
return static_page.generate_page()
@app.route("/contacto", methods=['GET'])
def contacto():
tupla_captcha = captcha_pregunta_opciones_random()
if tupla_captcha is None:
return ("<br>Parece un error interno!</br>")
pregunta = tupla_captcha[0]
opciones = tupla_captcha[1]
static_page = Page("contacto")
static_page.contexto['pregunta'] = pregunta
static_page.contexto['opciones'] = opciones
return static_page.generate_page()
@app.route("/contactoe", methods=['POST'])
def comprobar_mensaje():
""" Comprueba que el mensaje enviado por la caja de texto sea valido
y si lo es, guarda un archivo de texto con los detalles"""
errors = []
if request.method == "POST":
# comprobando validez
nombre = request.form["nombre"]
dir_respuesta = request.form['dir_respuesta']
mensaje = request.form['mensaje']
pregunta = request.form['pregunta']
respuesta = request.form['respuesta']
if len(mensaje) < 2 or mensaje.startswith(" "):
errors.append("Mensaje invalido")
if not captcha_comprobar_respuesta(pregunta, respuesta):
errors.append("Captcha invalido")
if len(errors) > 0:
return str(errors)
# guardando texto
texto = "Remitente: "+nombre
texto += "\nResponder_a: "+dir_respuesta
texto += "\n--- mensaje ---\n"
texto += mensaje
# TODO: cambiar a direccion especificada en archivo de configuracion
dt = datetime.datetime.now()
nombre = "m_"+str(dt.day)+"_"+str(dt.month)+\
"_"+str(dt.year)+"-"+str(dt.hour)+\
"-"+str(dt.minute)+"-"+str(dt.second)
with open(os.path.join("fbs",nombre), "wb") as f:
f.write(texto.encode("utf-8"))
return redirect("/mensaje_enviado", code=302)
@app.route("/mensaje_enviado")
def mensaje_enviado():
static_page = Page("mensaje_enviado")
return static_page.generate_page()
@app.route("/rss")
def rss_feed():
"""Genera la cadena rss con las 15 ultimas noticias del sitio
TODO: Agregar mecenismo para no generar los rss feeds y solo
devolver el archivo rss.xml generado anteriormente. Esto
quiere decir solamente generar el rss_feed cuando se haya hecho
un actualizacion en los posts mas reciente que la ultima vez
que se genero el rss_feed
"""
#return str(rss_ultimos_posts_jinja())
return render_template("rss.html",
contents = rss_ultimos_posts_jinja())
#**vars(self)
#)
##### specialized pages
@app.route("/source")
def source():
"""Display source files used to render a page"""
source_page = Page('source', title = "view the source code",
#heading = "Ver el código fuente",
heading = "Ver el codigo fuente",
internal_css = get_pygments_css())
page = request.args.get('page')
# get source for markdown if any. 404's for non-existant markdown
# unless special page eg source
pagesrc = source_page.get_page_src(page, 'src', 'md')
special_pages = ['source', 'unit-tests', '404']
if not page in special_pages and pagesrc is None:
abort(404)
# set enable_unit_tests to true in config.json to allow
# unit tests to be run through the source page
if app.config['enable_unit_tests']:
contents = '''<p><a href="/unit-tests" class="button">Run unit tests
</a></p>'''
# render tests.py if needed
if page == 'unit-tests':
contents += heading('tests.py', 2)
contents += render_pygments('tests.py', 'python')
else:
contents = ''
# render views.py
contents += heading('views.py', 2)
contents += render_pygments(source_page.get_page_src('views.py'),
'python')
# render markdown if present
if pagesrc:
contents += heading(os.path.basename(pagesrc), 2)
contents += render_pygments(pagesrc, 'markdown')
# render jinja templates
contents += heading('base.html', 2)
contents += render_pygments(
source_page.get_page_src('base.html', 'templates'), 'html')
template = source_page.get_template(page)
contents += heading(template, 2)
contents += render_pygments(
source_page.get_page_src(template, 'templates'), 'html')
return source_page.generate_page(contents)
# @app.route("/unit-tests")
# def unit_tests():
# """display results of unit tests"""
# unittests = Page('unit-tests', heading = "Test Results",
# internal_css = get_pygments_css())
# # exec unit tests in subprocess, capturing stderr
# capture = subprocess.Popen(["python", "tests.py"],
# stdout = subprocess.PIPE, stderr = subprocess.PIPE)
# output = capture.communicate()
# results = output[1]
# contents = '''<p>
# <a href="/unit-tests" class="button">Run unit tests</a>
# </p><br>\n
# <div class="output" style="background-color:'''
# if 'OK' in results:
# color = "#ddffdd"
# result = "TESTS PASSED"
# else:
# color = "#ffaaaa"
# result = "TESTS FAILING"
# contents += ('''%s">\n<strong>%s</strong>\n<pre>%s</pre>\n</div>\n'''
# % (color, result, results))
# # render test.py
# contents += heading('tests.py', 2)
# contents += render_pygments('tests.py', 'python')
# return unittests.generate_page(contents)
probando-bmx7.md
En este post compartiré unas pruebas y pequeña guía del protocolo de enrutamiento [Bmx7](https://github.com/bmx-routing/bmx7) para una red en malla.
Para construir una [red en malla autónoma](https://es.wikipedia.org/wiki/Red_en_malla) hace falta uno o más protocolo de enrutamiento, donde cada [nodo](https://es.wikipedia.org/wiki/Nodo_(inform%C3%A1tica)) en la red se hace descubrir, descubre a otros nodos, avisa a sus vecinos a quienes ha descubierto y también ayuda a llevar información de un nodo a otro a través de el mismo.
Existen varios protocolos de enrutamiento para redes *mesh* como Batman-adv, Babel, OLSR, bmx6, etc. y en el proyecto [LaOtraRed](https://wiki.lapaz.laotrared.net) hemos estado probando varios y buscando el protocolo que más se ajuste a las necesidades de una red libre comunitaria y de control colectivo. En ese afán hemos estado trabajando sobre una [primera versión estable o 1VE](https://foro.laotrared.net/t/discusion-rumbo-a-la-primera-version-estable-de-laotrared/211) donde hemos definido el protocolo **bmx7 como el principal**.
## Sobre bmx7 ##
Este protocolo es una versión más segura de [bmx6](http://bmx6.net/projects/bmx6). Bmx6 siendo una modificación de [Batman-adv](https://www.open-mesh.org/projects/batman-adv/wiki), está enfocado a redes en malla (que es lo mismo que decir redes *mesh*) pero le agrega soporte para IPv6, mejora la difusión del estado de cada nodo, etc [ [1] ](http://dsg.ac.upc.edu/sites/default/files/1569632801.pdf).
Bmx7 además le agrega seguridad usando SEMTOR lo que hace que los anuncios de rutas estén firmados criptográficamente [ [2] ](https://pdfs.semanticscholar.org/1752/f3710783f55784f8cf38a35cd5789bed8125.pdf).
A pesar de lo complejo que se ve el protocolo, configurar enrutadores para que lo utilicen es sencillo una vez se consigue poner el software necesario en el equipo.
## Preparando el escenario ##
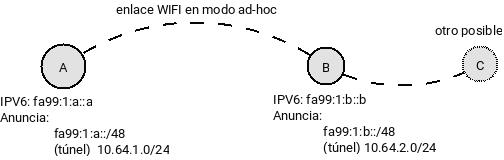
Son básicamente dos nodos, el nodo A y el nodo B se descubren y establecen comunicación con la ayuda de bmx7. El nodo A tiene la dirección IPv6: fa99:1:a::a y también IPv4: 10.64.1.1, de manera similar el nodo B tiene sus propias direcciones IP.
En el escenario descrito A y B anuncian también bloques de red, por ejemplo A dirá que es acreedor del bloque IPv6 `fa99:1:a::/48` directamente y también anuncia un bloque IPv4: `10.64.1.1/24` a través de un túnel, la manera de hacer anuncios varía en bmx7 y veremos eso más adelante.
La idea de este escenario es que se puede hacer que un nodo le diga a toda la red y más específicamente a sus vecinos, que tiene conexión a un grupo de direcciones IP (bloque IP) y que a través de si mismo los demás nodos de la red pueden conectarse a los dispositivos sean cuales fueren dentro de los bloques que anuncia.
## Preparando los nodos ##
Vamos a configurar paso a paso ambos enrutadores, para esta prueba he usado dos modelos de enrutadores baratos, el TP-link mr3040 y mr3020.
Normalmente bastaría con descargar la última versión estable del sistema operativo **openwrt** o lede para estos enrutadores desde [https://downloads.lede-project.org/releases/17.01.4/targets/ar71xx/generic/](https://downloads.lede-project.org/releases/17.01.4/targets/ar71xx/generic/) y buscando las imagenes `.factory.bin` o `.sysupgrade.bin` para el mr3020 y 3040 respectivamente. Luego instalar los paquetes necesarios con:
:::bash
opkg install bmx7 libmbedtls bmx7 bmx7-uci-config \
bmx7-iwinfo bmx7-tun bmx7-table kmod-iptunnel6 \
kmod-ip6-tunnel kmod-iptunnel4 kmod-iptunnel
Las imágenes de firmware por defecto en el repositorio de paquetes de lede u openwrt vienen con la interfaz `luci` para administrar el enrutador.
Debido a que bmx7 usa criptografía para firmar paquetes y verificar autenticidad, requiere la biblioteca [mbedtls](/posts/probando-mbedtls/) instalada en el sistema, como los enrutadores mr3020 y 3040 **sólo tienen 4MB** de memoria FLASH, si se incluye el luci no hay cabida para bmx7. En modelos de enrtuadores con 8 MB de FLASH no se tiene esta limitación.
Una solución sería desinstalar completamente luci pero no he encontrado una forma sencilla de hacerlo, por lo que se puede construir imágenes de firmware usando buildroot o image-generator, en el post [construir imágenes de firmware para enrutadores con build root](/posts/construir-firmware-para-enrutadores-con-buildroot/) puedes ver cómo hacerlo.
Por ejemplo usando el [image-generator](https://openwrt.org/docs/user-guide/additional-software/imagebuilder) se puede construir imágenes de firmware **sin luci** y con las dependencias necesarias para bmx7 con:
:::bash
make image PACKAGES="-libiwinfo-lua -liblua -libubus-lua -libuci-lua \
-lua -luci -luci-app-firewall -luci-base -luci-lib-ip -luci-lib-nixio\
-luci-mod-admin-full -luci-proto-ipv6 -luci-proto-ppp \
-luci-theme-bootstrap -uhttpd -uhttpd-mod-ubus \
bmx7 bmx7-iwinfo kmod-ip6-tunnel kmod-iptunnel6 kmod-iptunnel4 \
kmod-iptunnel bmx7-json bmx7-sms bmx7-table bmx7-topology bmx7-tun\
bmx7-uci-config libmbedtls"
--> También puedes descargar las imágenes de firmware con estas características de mi repositorio de imágenes de firmware de openwrt (este repositorio cambia y no esta garantizado que siempre vaya a funcionar):
* [https://openwrt.rmgss.net/targets/ar71xx/generic/](https://openwrt.rmgss.net/targets/ar71xx/generic/)
Luego instalar las imágenes de firmware correspondientes en los enrutadores. Si nunca lo has hecho revisa [esta guía](https://wiki.lapaz.laotrared.net/guias/instalar_openwrt).
### Configurando interfaces de red y WiFi ###
Primero el archivo de interfaces de red para el Nodo A.
#### /etc/network/interfaces
:::bash
config interface 'loopback'
option ifname 'lo'
option proto 'static'
option ipaddr '127.0.0.1'
option netmask '255.0.0.0'
config globals 'globals'
# mejor no cambiar esto en el enrutador
option ula_prefix 'fd91:9cd6:f633::/48'
config interface 'lan'
option proto 'static'
option type 'bridge'
option ipaddr '10.64.1.1'
option netmask '255.255.255.0'
option ifname 'eth0'
config interface 'mesh'
option proto 'static'
option ip6addr 'fa99:1:a::a'
Con lo anterior configuramos dos interfaces, `lan` en IPv4 y `mesh` en IPv6.
#### /etc/config/wireless
:::bash
config wifi-device 'radio0'
option type 'mac80211'
option hwmode '11g'
option path 'platform/ar933x_wmac'
option htmode 'HT20'
option channel '2'
option country 'BO'
option txpower '18'
option disabled '0'
config wifi-iface
option device 'radio0'
option network 'mesh'
option mode 'adhoc'
option ssid 'bmx7.pruebas'
option bssid 'D0:D0:11:11:11:11'
option encryption 'none'
Hacemos que el nodo emita una señal wifi en modo adhoc que con ssid "bmx7.pruebas" y ligada a la interfaz "mesh" definida anteriormente.
#### /etc/config/bmx7
:::bash
# modificamos un poco el archivo de configuracion por defecto
# en bmx7
config 'bmx7' 'general'
# usando la interfaz mesh
config 'dev' 'mesh'
option 'dev' 'wlan0'
# anuncios UHNA (para ipv6 directo)
config 'unicastHna' 'miPrefijoDeRed'
option 'unicastHna' 'fa99:1:a::/48'
# tuneles (para bloques ipv4)
# anunciar tunel ipv4
config 'tunDev' defaultbmx7
option 'tunDev' 'defaultbmx7'
option 'tun4Address' '10.64.1.0/24'
# aceptar anuncios
config 'tunOut'
option 'tunOut' 'ip4'
option 'network' '10.64.0.0/16'
# lo siguiente es para habilitar el plugin bmx7-tun
# y con esto poder crear tuneles
config 'plugin'
option 'plugin' 'bmx7_tun.so'
config 'plugin'
option 'plugin' 'bmx7_table.so'
En la configuración de bmx7, primero definimos en que interfaz va a trabjar el protocolo.
Luego definimos anuncios [uHNA](https://github.com/bmx-routing/bmx7#unicast-host-network-announcements-uhna) que son mensajes que anuncian a los nodos vecinos bloques y direcciones IP que tiene un nodo en la red. Lo bueno de usar UHNAs es que se garantiza que ningún otro nodo pueda utilizar las IP que anuncia un nodo mediante un identificador único y que los bloques de direcciones no se solapen. Todos estos paquetes se asocian a un indentificador único por cada nodo y van firmados criptográficamente.
Finalmente, bmx7 es sólo IPv6 y para anunciar bloques IPv4 utiliza [anuncios de túneles](https://github.com/bmx-routing/bmx7#tunnel-announcements). Afortunadamente no tenemos que crear los túneles manualemente ya que bmx7 los crea por nosotros, sólo indicamos mediante `tun4Address` que este nodo anuncia la red `10.64.1.0/24` y mediante `tunOut` le decimos que acepte anuncios que estén dentro de `10.64.0.0/16` y que los retransmita.
En el nodo B las configuraciones son similares donde sólo cambian los bloques y direcciones IP correspondientes, si habría otro nodo C o otros más se hace de la misma forma.
Una vez guardadas estas configuraciones, reiniciamos el demonio bmx7 con:
/etc/init.d/network restart
/etc/init.d/bmx7 restart
## Haciendo pruebas ##
El demonio bmx7 se puede consultar en cualquier momento para consultar su estado ,nodos asociados o túneles, a continuación algunas consultas hechas en el enrutador.
<div style="border:1px solid black;height:320px;width: 620px;overflow-y:hidden;overflow-x:scroll;">
<pre>
bmx7 -c status
# que responde
STATUS:
shortId name nodeKey cv revision primaryIp tun6Address tun4Address uptime cpu txQ nbs rts nodes
1A0165FA openwrt RSA2048 21 0a82c7c fd70:1a01:65fa:6d39:dce1:20b6:1299:1f82 ::/0 172.24.3.1/24 0:00:38:28 0.4 0/50 1 1 2/2
# se puede tambien consultar mas detalles
bmx7 -c status originators
# que responde
STATUS:
shortId name nodeKey cv revision primaryIp tun6Address tun4Address uptime cpu txQ nbs rts nodes
1A0165FA openwrt RSA2048 21 0a82c7c fd70:1a01:65fa:6d39:dce1:20b6:1299:1f82 ::/0 10.64.0.0/24 0:00:38:28 0.4 0/50 1 1 2/2
ORIGINATORS:
shortId name as S s T t descSqn lastDesc descSize cv revision primaryIp dev nbShortId nbName metric hops ogmSqn lastRef
7B037847 openwrt1 nA A A A A 512 2303 671+747 21 0a82c7c fd70:7b03:7847:472a:414:9eee:2d98:3e14 wlan0 7B037847 openwrt1 22399K 1 356 0
1A0165FA openwrt nQ A A A A 413 132 671+749 21 0a82c7c fd70:1a01:65fa:6d39:dce1:20b6:1299:1f82 --- --- --- 257G 0 20 5
# en la salida anterior el nodo B se reconoce como openwrt1
# con identificador 7B037847
# tambien una descripcion mas completa con los detalles de los anuncios de cada nodo
bmx7 -c status originators descriptions tunnels
# que produce una salida muy larga
</pre>
</div>
La guía completa de comandos se puede ver en [https://github.com/bmx-routing/bmx7](https://github.com/bmx-routing/bmx7) o una descripcion mas corta con `bmx7 --verboseHelp`.
Como en las consultas anteriores vemos que el nodo B se ha dectectado, comprobamos que en el enrutador se hayan establecido rutas hacia él, por ejmplo con:
:::bash
ip -6 route
# que muestra entre su salida que hay una ruta establecida hacia el nodo B
fa99:1:b::/48 via fe80::ea94:f6ff:fe6b:80fa dev wlan0 metric 1024
fd70:7b03:7847:472a:414:9eee:2d98:3e14 via fe80::ea94:f6ff:fe6b:80fa dev wlan0 metric 1024
unreachable default dev lo metric -1 error -128
fa99:1:a::a dev wlan0 metric 256
En bmx7 los nodos configuran automáticamente una dirección IPv6 al azar y un indentificador único en la red, pero los anuncios de redes UHNA son únicos y eso suprime el riesgo de IP spoofing.
Ahora la comunicación entre el nodo A,B o una cantidad arbitraria de nodos es posible, podemos comprobar haciendo por ejemplo la prueba trazando rutas.
:::bash
traceroute -6 fa99:1:b::b
Que muestra que se puede llegar a esa direccion IP iendo por el nodo B.
:::bash
traceroute to fa99:1:b::b (fa99:1:b::b), 30 hops max, 16 byte packets
1 fa99:1:b::b (fa99:1:b::b) 1.392 ms 1.581 ms 1.329 ms
# usando ip para ver que ruta se sigue para alcanzar una IP
ip route get fa99:1:b::b
fa99:1:b::b from :: via fe80::ea94:f6ff:fe6b:80fa dev wlan0 src fc99:1:a::a metric 1024
### Modificaciones "en caliente" ###
En bmx7 no es obligatorio utilizar un archivo de configuración para modificar el comportamiento del protocolo. Cuando el demonio bmx7 esta ejecutándose con comandos se puede por ejemplo hacer que se anuncien bloques adicionales mediante UHNA.
bmx7 -c u=fc01:1934:ffed::/64
Que haría que el nodo también anuncie el bloque `fc01:1934:ffed::/64`, de igual manera se puede hacer que se anuncien túneles, quitarlos, establecer póliticas para aceptar anuncios y distribuirlos, etc. Consulta la [guía oficial](https://github.com/bmx-routing/bmx7).
Con toda la flexibilidad que ofrece bmx7 ya tenemos construida una pequeña red en malla :)
## Referencias ##
1. [An evaluation of BMX6 for Community Wireless Networks](http://dsg.ac.upc.edu/sites/default/files/1569632801.pdf)
2. [Securely-Entrusted Multi-Topology Routing for
Community Networks](https://pdfs.semanticscholar.org/1752/f3710783f55784f8cf38a35cd5789bed8125.pdf)
base.html
<!DOCTYPE html>
<!--
Monomotapa - A Micro CMS
Copyright (C) 2014, Paul Munday.
PO Box 28228, Portland, OR, USA 97228
paul at paulmunday.net
This program is free software: you can redistribute it and/or modify
it under the terms of the GNU Affero Public License as published by
the Free Software Foundation, either version 3 of the License, or
(at your option) any later version.
This program is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU General Public License for more details.
You should have received a copy of the GNU Affero General Public License
along with this program. If not, see <http://www.gnu.org/licenses/>.
There should also be a copy of the AGPL in src/license.md that should be
accessible by going to <a href ="/license">/license<a> on this site.
-->
<html>
<head>
<title>{% if title -%}{{title}}{% endif %}</title>
<meta name="viewport" content="width=device-width, initial-scale=1">
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<meta name="lang" content="es"/>
<meta name="author" content="Rodrigo Garcia Saenz"/>
<meta property="article:publisher" content="https://rmgss.net"/>
<meta property="og:site_name" content="Sitio personal de Rodrigo Garcia Saenz"/>
<!-- meta datos dinamicos -->
{%- for metadato in meta -%}
<meta {{metadato.tag}}="{{metadato.name}}" content="{{metadato.content}}"/>
{%- endfor -%}
<!-- -->
<link rel="stylesheet" type="text/css" title="oscuro" href="/static/style_rmgss.css">
<link rel="alternate stylesheet" type="text/css" title="claro" href="/static/style_rmgss_claro.css">
<!-- {%- if css -%} -->
<!-- {%- for file in css %} -->
<!-- <link href="{{ url_for('static', filename=file) }}" rel="stylesheet" type="text/css" /> -->
<!-- {%- endfor -%} -->
<!-- {%- endif %} -->
{% if internal_css %}
<style type="text/css">
{{internal_css}}
</style>
{% endif %}
{%- if hlinks -%}
{%- for item in hlinks -%}
<link
{%- if item.href %} href="{{item.href}}"{% endif -%}
{%- if item.rel %} rel="{{item.rel}}"{% endif -%}
{%- if item.type %} type="{{item.type}}"{% endif -%}
{%- if item.media %} type="{{item.media}}"{% endif -%}
{%- if item.hreflang %} type="{{item.hreflang}}"{% endif -%}
{%- if item.charset %} type="{{item.charset}}"{% endif -%}
>
{% endfor %}
{%- endif -%}
<link rel="apple-touch-icon" sizes="76x76" href="{{ url_for('static', filename='imgs/favicon/apple-touch-icon.png')}}">
<link rel="icon" type="image/png" sizes="32x32" href="{{ url_for('static', filename='imgs/favicon/favicon-32x32.png')}}">
<link rel="icon" type="image/png" sizes="16x16" href="{{ url_for('static', filename='imgs/favicon/favicon-16x16.png')}}">
<link rel="manifest" href="{{ url_for('static', filename='imgs/favicon/site.webmanifest')}}">
<link rel="mask-icon" href="{{ url_for('static', filename='imgs/favicon/safari-pinned-tab.svg')}}" color="#5bbad5">
<meta name="msapplication-TileColor" content="#da532c">
<meta name="theme-color" content="#ffffff">
{# <link rel="shortcut icon" type="image/png" href="/{{ url_for('static', filename='imgs/favicon.png') }}> #}
</head>
<body onload="loadCssStyle()">
<div id="wrap">
<div>
<p>
<a href="/">
<img src="/static/imgs/cabecera1.png">
</a>
<br>
<span style="font-size:12px;">
<q><b>sitio personal</b> de Rodrigo Garcia Saenz.</q>
</span>
</p>
</div>
<div class="row">
<!-- <div class="col fifth"> -->
<!-- Importante dejar este -->
<!-- </div> -->
<div class="col fifth">
<!-- Tabla de contenidos del post -->
{%- if not exclude_toc -%}
<div id="side_toc">
<h3>Índice del post</h3>
{{ toc|safe }}
</div>
{%- endif -%}
<div id="nav_left">
<ul>
<dd>
<a href="/">
<img class="leftbaricon"
src="/static/imgs/inicio.svg" alt="Inicio / Start" title="Inicio 🏡">
</a>
</dd>
<dd>
<a href="/posts">
<img class="leftbaricon" src="/static/imgs/misc.svg" alt="Posts" title="Posts">
Posts
</a>
<ul>
<dd>
<a href="/posts/categorias">
<img
class="leftbaricon"
src="/static/imgs/categorias.svg" alt="Categorías" title="Categorías">
Categorías
</a>
</dd>
</ul>
</dd>
<dd>
<a href="/posts/categoria/fotos">
<img
class="leftbaricon"
src="/static/imgs/fotos.svg" alt="fotos" title="fotos 🖼">
Fotos
</a>
<dd>
<a href="/acerca_de_mi">
<img src="/static/imgs/acercade.svg" alt="acerca de mi" title="Acerca de mi">
Acerca de mi
</a>
</dd>
<dd>
<a href="/contacto">
<img
class="leftbaricon"
src="/static/imgs/contacto.svg" alt="contacto" title="Contacto 📨">
Contacto
</a>
</dd>
</ul>
<ul>
<hr>
{%- for item in navigation.navigation.values() -%}
<li><a href="
{%- if item.url -%}{{item.url}}
{%- elif item.urlfor -%}
{%- if item.urlfor == "source" -%}
{{ url_for(item.urlfor, page=navigation.page) }}
{%- else -%}
{{ url_for(item.urlfor) }}
{%- endif -%}
{%- else -%}
{{ url_for('staticpage', page=item.base) }}
{%- endif -%}
{%- if item.rel -%}
" rel="{{item.rel}}
{%- endif -%}
">{{item.link_text}}</a></li>
{% endfor -%}
</ul>
<p>
<a href="/rss" >
<img src="/static/imgs/rss.png" width="24" heigth="24">
RSS
</a>
</p>
</div>
<!-- consejo del dia -->
<div id="consejo_del_dia">
<b>Consejo del día</b>
<hr>
{% if contexto %}
{{ contexto['consejo']|safe }}
{% endif %}
</div>
<!-- Noticias Realcionadas si es un post -->
<div id="noticias_relacionadas">
{% if contexto is defined %}
{% if contexto['relacionadas'] is defined %}
<h3>Posts/Noticias relacionadas</h3>
{% for post_relacionado in contexto['relacionadas'] %}
<p>
<a href="/posts/{{ post_relacionado }}">
{{ post_relacionado|n_heading }}
</a>
</p>
<hr>
{% endfor %}
{% endif %}
{% endif %}
</div>
</div>
<!-- Contenido -->
<div class="col fill">
<!-- Cabecera -->
<div style="margin-bottom: 7px">
<form>
<input type="submit" onclick="cambiarEstilo('oscuro'); return false;" name="theme" value="☻" id="oscuro" style="background-color: #333933; color: #C3C4C2; border-radius:3px;">
<input type="submit" onclick="cambiarEstilo('claro'); return false;" name="theme" value="☺" id="claro" style="background-color: #D1E9D3; color: #131914; border-radius:3px;">
</form>
</div>
<!-- Contenido -->
{% block content %}{% endblock %}
<!-- nav bottom (para pantallas chicas) -->
<div id="nav_bottom">
<ul>
<dd>
<a href="/">
<img src="/static/imgs/inicio.svg"
class="leftbaricon"
title="Inicio 🏡"
alt="Inicio">
</a>
</dd>
<dd>
<a href="/posts">
<img
class="leftbaricon"
title="Posts"
src="/static/imgs/misc.svg" alt="posts">
Posts
</a>
<ul>
<dd>
<a href="/posts/categorias">
<img
class="leftbaricon"
title="Categorías"
src="/static/imgs/categorias.svg" alt="categorías">
categorías
</a>
</dd>
</ul>
</dd>
<dd>
<a href="/posts/categoria/fotos">
<img
class="leftbaricon"
title="Fotos 🖼"
src="/static/imgs/fotos.svg" alt="fotos">
fotos
</a>
</dd>
<dd>
<a href="/acerca_de_mi">
<img
class="leftbaricon"
title="Acerca de mi"
src="/static/imgs/acercade.svg" alt="Acerca de mi">
acerca de
</a>
</dd>
</ul>
<dd>
<a href="/contacto">
<img
class="leftbaricon"
title="Contacto 📨"
src="/static/imgs/contacto.svg" alt="Contacto">
contacto
</a>
</dd>
</ul>
<ul>
<hr>
{%- for item in navigation.navigation.values() -%}
<li><a href="
{%- if item.url -%}{{item.url}}
{%- elif item.urlfor -%}
{%- if item.urlfor == "source" -%}
{{ url_for(item.urlfor, page=navigation.page) }}
{%- else -%}
{{ url_for(item.urlfor) }}
{%- endif -%}
{%- else -%}
{{ url_for('staticpage', page=item.base) }}
{%- endif -%}
{%- if item.rel -%}
" rel="{{item.rel}}
{%- endif -%}
">{{item.link_text}}</a></li>
{% endfor -%}
</ul>
<p>
<a href="/rss" >
<img src="/static/imgs/rss.png" width="24" heigth="24">
RSS
</a>
</p>
</div>
<!-- Noticias Realcionadas si es un post -->
<div id="noticias_relacionadas_bottom">
{% if contexto is defined %}
{% if contexto['relacionadas'] is defined %}
<h3>Posts/Noticias relacionadas</h3>
{% for post_relacionado in contexto['relacionadas'] %}
<p>
<a href="/posts/{{ post_relacionado }}">
{{ post_relacionado|n_heading }}
</a>
</p>
<hr>
{% endfor %}
{% endif %}
{% endif %}
</div>
<!-- consejo del dia -->
<div id="consejo_del_dia_bottom">
<b>Consejo del día</b>
<hr>
{% if contexto %}
{{ contexto['consejo']|safe }}
{% endif %}
</div>
</div>
</div> <!-- row -->
</div>
<div id="footer">
<p id="footer">
Este sitio web es software libre aquí el <a href="https://notabug.org/strysg/monimatapa">código fuente</a>.<br>
El contenido de este sitio esta bajo una licencia Creative Commons <a href="https://creativecommons.org/licenses/by/4.0/">Attribution 4.0 International (CC BY 4.0)</a> a menos que se indique lo contrario.
<!-- footer goes here -->
{% if footer %}
{{footer}}
{% endif %}
</p>
</div>
<!-- javascript -->
<script language="javascript">
function loadCssStyle() {
const _varStyleName = 'style_css';
var lsStyle = window.localStorage.getItem(_varStyleName);
if (!lsStyle) {
// default
window.localStorage.setItem('style_css', 'oscuro');
lsStyle = window.localStorage.getItem(_varStyleName);
}
var i, link_tag = document.getElementsByTagName("link");
// inspeccionando hojas de estilo css cargadas
for (
i = 0,
link_tag = document.getElementsByTagName("link") ; i < link_tag.length ;
i++ ) {
if ((link_tag[i].rel.indexOf( "stylesheet" ) != -1)) {
link_tag[i].disabled = true;
if (link_tag[i].title === lsStyle) {
link_tag[i].disabled = false ;
console.log('enabling', link_tag[i].title);
}
}
}
}
function cambiarEstilo(value) {
window.localStorage.setItem('style_css', value);
loadCssStyle();
}
</script>
<!-- --->
</body>
</html>
post.html
{% extends "base.html" %}
{% block content %}
<article class="h-entry">
<div>
{% if heading %}<h1 class="p-name">{{heading}}</h1>{% endif %}
</div>
{# <hr> #}
{# {{ meta }} #}
{# <hr> #}
{% if attributes %}
<div id="attributes">
<p id="post-details">
{% if attributes['date'] %}
<time class="dt-published" datetime="{{attributes['date']}}">
{% if attributes['date-text'] %}
{{attributes['date-text']}}
{% else %}
{{attributes['date']}}
{% endif %}
</time>
{% endif %}
{% if attributes['author'] %}
<span class="p-author">{{attributes['author']}}</span>
{% endif %}
<a class="u-url" href="/{{name}}">permalink.</a>
</p>
{% if attributes['summary'] %}
<p class="p-summary">{{attributes['summary']}}</p>
{% endif %}
</div>
{% endif %}
<div class='e-content'>
<div align="right">
{% if contexto['ultima_modificacion'] %}
<small>Actualizado - {{ contexto['ultima_modificacion'] }}</small>
{% endif %}
</div>
{% if categorias %}
<div class="categorias">
{% for cat in categorias %}
<a href="/posts/categoria/{{ cat }}">#{{ cat }}</a>
{% endfor %}
</div>
{% endif %}
{{contents}}
</div>
</article>
{% endblock %}