

 Posts
Posts
 Categorías
Categorías
 Fotos
Fotos
 Acerca de mi
Acerca de mi
 Contacto
Contacto
Clasificación mensajes correo debian parte 1
Análisis de datos exploratorio, mensajes de correo electrónico de la lista de Debian
Estuve aprendiendo a usar técnicas de aprendizaje automático para procesamiento de mensajes de texto y generación de modelos que permita predecir a qué categoría pertenecen.
Decidí jugar un poco con la lista de correos de debian y aplicar aprendizaje automático. En este post dividido en tres partes mostraré en la primera como obtuve los mensajes de la lista de correos de debian e hice un análisis exploratorio de datos (EDA) usando python.
En una segunda parte la aplicación del aprendizaje automático y en la tercera parte la aplicación del modelo generado y que devuelva una predicción indicando a que categoría podría pertenecer un mensaje de correo electrónico cualquiera.
Lista de correos de Debian¶
Para hacer todo este proceso se requieren datos, por lo que decidí usar parte de los mensajes de la lista de correos de debian en https://lists.debian.org/completeindex.html.
La lista de correos electrónicos de debian almacena los emails que la comunidad de debian intercambia. Esta lista está organizada en varias sublistas de acuerdo a una temática de trabajo, por ejemplo:
- debian-devel: Contiene discusiones sobre temas de desarrollo de software.
- debian-legal: Discusiones sobre legalidad como derechos de autor, patentes, etc.
- debian-jobs: Anuncios de trabajo para la comunidad debian.
Esta organización permite a la comunidad trabajar en temas de su interés y mantener las discusiones clasificadas.
Descargando los correos¶
Como son correos electrónicos públicos entonces la primera tarea es descargarlos, busqué herramientas para hacerlo pero no encontré ninguna que permita descargar los correos y que estos queden organizados según la estructura habitual, por lo que tuve que escribir una utilidad en python para descargarlos.
Esta utilidad se llama mailinglist-donwloader-py y básicamente descarga los mensajes de correo electrónico publicados en https://lists.debian.org/completeindex.html extrayendo información de las páginas web del archivo de la lista de correos mediante web scraping.
La utilidad permite descargar los correos según año y categoría (sublistas de correo) y los guarda en una carpeta como archivos de texto. Adicionalmente para facilitar el análisis y aplicación de técnicas de aprendizaje automático (machine learning) permite construir un archivo .csv con todos los mensajes.
Los pasos que seguí fuerón:
1) Descargar la utlidad e instalar dependencias. ver README
2) Crear y modificar el archivo debian-mailinglist.yaml para las descargas que al final quedó así:
index_url: https://lists.debian.org/completeindex.html download_all: False section_download: - debian-cli - debian-desktop - debian-edu - debian-firewall - debian-legal - debian-jobs - debian-python - debian-science - debian-vote - debian-mentors years: - 2015 - 2016 - 2017 - 2018 - 2019 debug: True
3) Descargar con make download-debian, la descarga debería terminar con un mensaje similar a:
Total of: 17177 urls found
Total of: 17129 files written
4) Crear el archivo .csv make csv-debian.
Luego el archivo resultante queda en output/debian-mailinglist/debian-mailinglist.csv.
Si no deseas seguir estos pasos puedes descargar aquí los mensajes.
Análisis exploratorio (EDA)¶
Para este análisis exploratorio usé python con numpy, pandas, scikitlearn y otras bibliotecas. Todas estas bibliotecas pueden instalarse en el sistema, en mi caso estoy usando anaconda3 como entorno python y todo el detalle del EDA está en el siguiente notebook de jupyter:
jupyter notebook: debian-2015-2019-NaiveBayes-RandomForest.ipynb
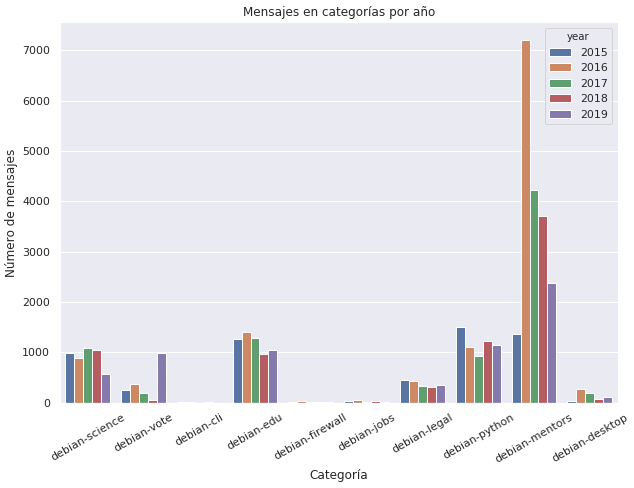
Nuestro objetivo final es generar un modelo que permita predecir a qué categoría o sublista de correo pertenece un mensaje. Para ello una estrategia es encontrar palabras en común que se repiten más en una categoría que en otra.
Lo que es importante resaltar es que los mensajes de correo ya están clasificados por categorías (sublista de correos) y no tendremos que analizar el significado de cada mensaje. Lo que si es necesario es un trabajo de limpieza de los mensajes, se dan varios casos:
- Correos en formato html: Muchos emails enviados están en html, esto no aporta al análisis por que no es una característica que permita diferenciar los correos según categoría. Además contiene etiquetas html por ejemplo
<a> <span> <div>, por lo que se quitarán las etiquetas html. - Firmas digitales: Muchos usuarios firman digitalmente sus mensajes para dar fé de que fueron ellos quienes realmente los escribieron. Pero estos bloques de texto no debemos tomarlos en cuenta por que tampoco es información que ayude a clasificar según categoría.
- Palabras muy comunes: Los correos como cualquier mensaje de texto contienen palabras comunes en cualquier categoría como
the is an from to he she thosey tampoco ayudan a diferenciar por categorías, entonces usaremos un diccionario de palabras comunes en inglés para ignorarlas. - Texto citado: Muchos mensajes contienen bloques citando texto en otros mensajes, esto causa que las palabras se repitan un número indefinido de veces por que no todos los mensajes citan texto de otros. Para evitar esta ambigüedad y no contar palabras más de una vez se eliminarán las líneas que comiencen con
>que es la marca usada para citar mensajes.
En resumen la siguiente imagen muestra un ejemplo del proceso.

Una vez se han limpiado los mensajes como se muestra en el jupyter notebook los tenemos prácticamente listos para aplicar una o mas técnicas de aprendizaje automático y generar modelos que permitan predecir a que categoría podrían pertenecer otros mensajes.
Este trabajo continúa en la segunda parte.