

 Posts
Posts
 Categorías
Categorías
 Fotos
Fotos
 Acerca de mi
Acerca de mi
 Contacto
Contacto
Clasificación mensajes correo debian parte 2
Aplicación de técnicas de machine learning para generar modelos de clasificación, mensajes de correo electrónico de la lista de Debian
Continuando con la clasificación de mensajes de correo de debian en la parte 1, en esta parte aplicaremos dos técnicas de aprendizaje automático para generar modelos de predicciones, estas son Multinomial Naive Bayes y Random Forest Classifier.
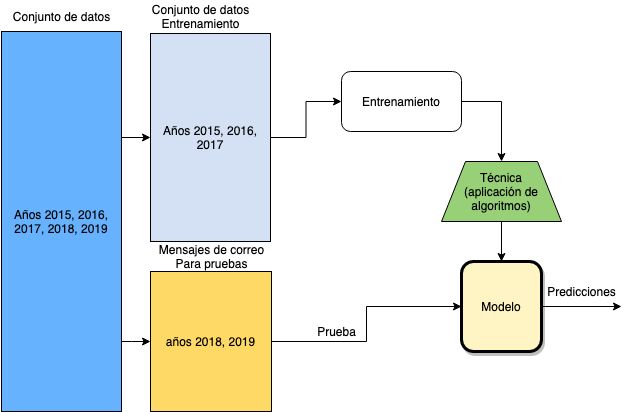
Todo el procedimiento se puede revisar en notebook de jupyter en la PARTE 2:
jupyter notebook: debian-2015-2019-NaiveBayes-RandomForest.ipynb
Aplicando Multinomial Naive Bayes¶
Una forma de entender esta técnica es calcular la ocurrencia de cada palabra en un documento (mensaje de correo) contando las veces que se repiten y aplicando este procedimiento a todos los documentos en el conjunto de datos. A partir de ese conteo de ocurrencias y usando el teorema de Bayes con las probabilidades condicionales se puede calcular la probabilidad de ocurrencia de un evento que no conocemos. En este caso la probabilidad de que un documento (correo electrónico) pertenezca a una categoría, entonces las categorías que tengan la mejor probabilidad serán nuestran predicciones. Una explicación más detallada se puede revisar en [1]
En el post anterior se ha obtenido la bolsa de palabras (bag of words) como se explica en [2] entonces tenemos todo listo para aplicar la técnica.
En el notebook se define una función obtenerModeloMultinomialNB() donde se tienen varios pasos.
Primero recibe como se muestra en la figura de arriba conjuntos de datos de entrenamiento (x_train y_train) y prueba (x_test y_test). Notarás que se dividen en x (mensajes) e y (categorías de mensajes), esto es por la forma que la biblioteca sklearn hace el cálculo de probabilidades.
labelencoder_y = LabelEncoder() y = labelencoder_y.fit_transform(y_train)
El algoritmo Naive Bayes trabaja solamente con valores numéricos, esta primera parte se encarga de representar las el arreglo de categorías de entrenamiento en forma numérica.
debian-science --> 8 debian-vote --> 9 debian-edu --> 2 debian-legal --> 5 debian-python --> 7 ...
Luego se usa CountVectorizer que hace el procedimiento de contar la ocurrencia de palabras en los documentos y ajustar este conteo a una conveniente matriz con documentos, palabras y número de ocurrencias por palabra.
(0, 1025) 2 # documento 0, palabra con indice 1025 tiene 2 ocurrencias ... (25977, 1121) 5 # documento 25977, palabra con indice 1121 tiene 5 ocurrencias
Con esta matriz se puede aplicar el entrenamiento y realizar un ajuste entre la matriz obtenida y el arreglo de categorías usando la técnica Naive Bayes.
mnb = MultinomialNB() predictions = mnb.predict(x_testcv)
mnb.predict() devuelve el conjunto de predicciones aplicadas sobre el conjunto de prueba que también se ha procesado con CountVectorizer. Lo que sigue es hacer el conteo de las predicciones correctas y armar un diccionario para mostrar gráficas con los resultados de las predicciones por categorías. El resultado de las predicciones usando Naive Bayes se puede ver en la siguiente gráfica.
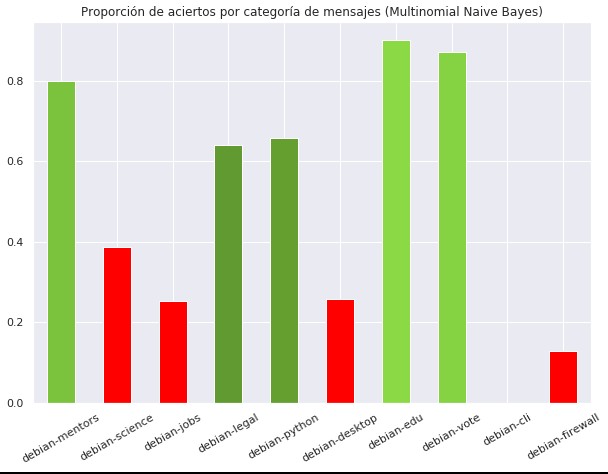
La gráfica muestra en rojo las predicciones que tienen menos del 61% de precisión, es decir las categorías debian-science debian-jobs debian-desktop debian-cli debian-firewall. Siendo un total de 5 categorías con predicciones mayores a 61% de precisión y 5 por debajo. La causa común de estas imprecisiones es la cantidad reducida de mensajes de entrenamiento en estas categorías, sin embargo es necesario realizar un mayor análisis del contenido mismo de los mensajes que podrían por ejemplo tener muchas palabras técnicas para las cuales la aplicación de Naive Bayes podría no ser la adecuada.
Aplicando el clasificador Random Forest¶
La técnica del clasificador Random Forest aprovecha los árboles de decisión para generar varios árboles con muestras aleatorias formando un bosque de árboles de decisión, del resultado de este bosque se obtienen los más comunes como las predicciones finales. Una descripción más detallada se puede ver en [3] .
Al igual que el caso anterior usaremos representaciones numéricas de las categorías y también usaremos CountVectorizer para obtener una matriz con el conteo de ocurrencias de palabras. Una diferencia es que Random Forest require que se indique cuantos árboles de decisión se van a generar antes de lanzar las predicciones.
# creando el objeto clasificador random forest para crear un número dado de árboles clf = RandomForestClassifier(n_estimators=trees) # Al aplicar fit se crean los árboles con los datos de entrenamiento clf.fit(x_traincv, y_train) # realizando las predicciones randomForest_predictions = clf.predict(x_testcv)
Luego de aplicar esta técnica tenemos varios resultados dependiendo de la cantidad de árboles generados.

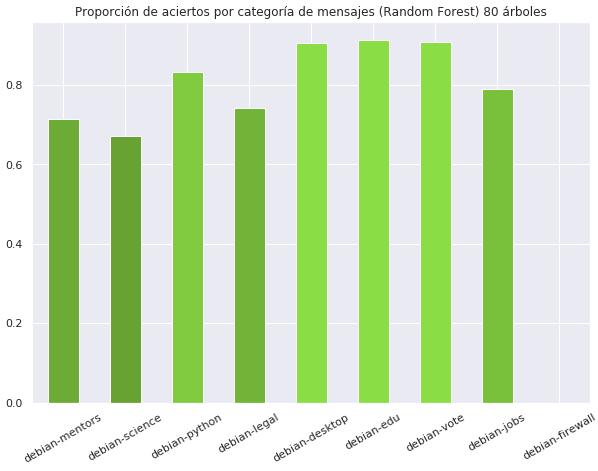
Se puede ver la mejora de predicciones entre la creación de 10 y 80 árboles de decisión, también se ve que siempre se tienen predicciones erróneas para la categoría debian-firewall y en el entrenamiento con 80 árboles se elimina la categoría debian-cli.
Una desventaja de esta técnica es que para la generación de múltiples árboles se requiere mucho más tiempo de procesamiento que aplicando Navie Bayes.
Conclusiones¶
Al parecer la técnica Random Forest produce mejores resultados que la técnica Naive Bayes aplicada a la lista de correos de debian en las categorías presentadas. Hay que considerar que no se hace un preprocesamiento exhaustivo de los mensajes de correo por ser demasiados (más de 20000) y que cada categoría en la lista de correos de debian puede tener tipos de mensajes muy distintos.
Por ejemplo debian-python o debian-firewall contienen muchos mensajes con contenido técnico lo que resulta en palabras poco comunes que inicialmente se eliminan en CountVectorizer (ver parte 1) y estas palabras podrían ser clave para identificar una categoría con contenido técnico de otra con mensajes con lenguaje más común.
Sería interesante aplicar estas técnicas a otras secciones de la lista de debian y cambiar el criterio de selección o limpieza de datos e incluso ajustes a los algoritmos Naive Bayes y Random Forest. Usando la herramienta de descarga descrita en la parte 1.
En la parte 3 se procederá a usar estos modelos generados para y usarlos en cualquier mensaje. El modelo generará predicciones e indicará a qué categoría podría pertenecer ese mensaje de manera más directa.